 何恺明团队所在的Facebook AI推出ResNeXt-101模型
何恺明团队所在的Facebook AI推出ResNeXt-101模型
近日,何恺明团队所在的Facebook AI推出ResNeXt-101模型,利用Instagram上的用户标记图片作为预训练数据集,省去了人工标记数据的巨额成本,而且使用中只需微调,性能即超越了ImageNet任务的SOTA水平。
目前,几乎所有最先进的视觉感知算法都依赖于相同的范式:(1)在手动注释的大型图像分类数据集上预训练卷积网络,(2)在较小的特定任务的数据集上微调网络。这个模式已经广泛使用了好多年,并取得了明显的进展。比如:物体检测,语义分割,人体姿势估计,视频识别,单眼深度估计等。
事实上,如果没有有监督式预训练,很多方法现在还被认为是一种蛮干 ImageNet数据集实际上是预训练数据集。我们现在实际上对数据集的预训练了解相对较少。其原因很多:比如现存的预训练数据集数量很少,构建新数据集是劳动密集型的工作,需要大量的计算资源来进行实验。然而,鉴于预训练过程在机器学习相关领域的核心作用,扩大我们在这一领域的科学知识是非常重要的。

本文试图通过研究一个未开发的数据体系来解决这个复杂的问题:使用外部社交媒体上数十亿的带有标签的图像作为数据源。该数据源具有大而且不断增长的优点,而且是“免费”注释的,因为数据不需要手动标记。显而易见,对这些数据的训练将产生良好的迁移学习结果。
本文的主要成果是,在不使用手动数据集管理或复杂的数据清理的情况下,利用数千个不同主题标签作为标记的数十亿幅Instagram图像进行训练的模型,表现出了优异的传输学习性能。在目标检测和图像分类任务上实现了对当前SOTA性能的提升。在ImageNet-1k图像分类数据集上获得single-crop 最高准确率达到了85.4%,AP达到了45.2%。当在ImageNet-1k上训练(或预训练)相同模型时,分数分别为79.8%和43.7%。然而,我们的主要目标是提供关于此前未开发的制度的新实验数据。为此,我们进行了大量实验,揭示了一些有趣的趋势。
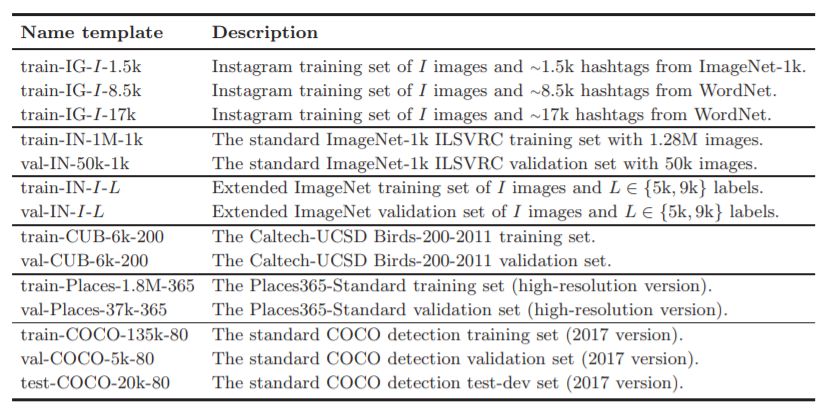
表1:图像分类数据集的摘要。每个数据集标明数据来源和功能(训练集,验证集,测试集),图像数量I和标签数量L。
ImageNet数据集和模型
除了标准的IN-1k数据集之外,我们还尝试了包含1420万幅图像和22000标签的完整ImageNet2011完整版本的更大子集。我们构建了包含5k和9k标签的训练集和验证集。
对于5k标签集组,我们使用现在标准的IN-5k(6.6M训练图像)。对于9k标签集,我们遵循用于构建IN-5k数据集的相同协议,采用下一个最频繁的4k标签和所有相关图像(10.5M训练图像)。在两种情况下,均使用50个图像进行验证。
我们使用具有分组卷积层的残差网络ResNeXt 。实验中使用ResNeXt-101 32×Cd,它有101层,32组,组宽分别为:4(8B乘加FLOPs,43M参数),8(16B,88M),16(36B,193M), 32(87B,466M)和48(153B,829M)。我们认为实验结果可以推广到其他架构。
与ImageNet相比,我们使用的Instagram数据集可能包含每个图像的多个标签(因为用户指定了多个主题标签)。每个图像的平均标签数量因数据集而异;例如,train-IG-1B-17k每个图像最多包含2个主题标签。
实验结果与性能
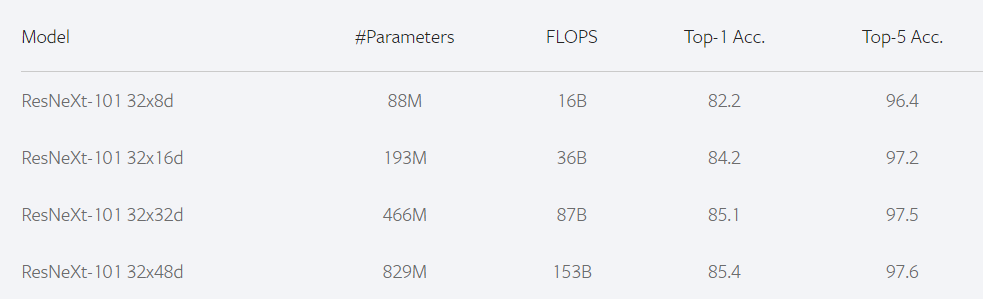
表2:使用不同规模、不同参数配置的ResNeXt-101模型获得的不同性能结果比较

图1:使用不同规模和参数配置的ResNeXt-101模型在ImageNet和Instagram标记数据集的分类性能的比较
运行实例及相关代码
# Download an example image from the pytorch websiteimport urlliburl, filename = ("https://github.com/pytorch/hub/raw/master/dog.jpg", "dog.jpg")try: urllib.URLopener().retrieve(url, filename)except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)from PIL import Imagefrom torchvision import transformsinput_image = Image.open(filename)preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])input_tensor = preprocess(input_image)input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model# move the input and model to GPU for speed if availableif torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda')with torch.no_grad(): output = model(input_batch)# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classesprint(output[0])# The output has unnormalized scores. To get probabilities, you can run a softmax on it.print(torch.nn.functional.softmax(output[0], dim=0))
-
图像分类
+关注
关注
0文章
90浏览量
11914 -
机器学习
+关注
关注
66文章
8397浏览量
132514 -
数据集
+关注
关注
4文章
1206浏览量
24667
原文标题:何恺明团队新作ResNext:Instagram图片预训练,挑战ImageNet新精度
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

Facebook手机明年或上市 采用Firefox OS系统
Facebook 最新推出的虚拟现实世界,简直好玩到炸裂
苹果音箱月产大跌 Facebook智能音箱延至10月
Facebook智能音箱可能先在国际市场推出 隐私问题受到关注
如何加速电信领域AI开发?
Bloomsbury AI团队加入Facebook团队,共同构建新的自然语言杜绝假新闻
Facebook推出ONNX,旨在为不同编程框架的神经网络创建共享模型
Facebook构建虚拟空间训练AI
Facebook推出新款AI打牌机器人 可打败专业对手
Facebook推出新AI模型,希望给计算机视觉领域带来一次“革命”
NVIDIA 为全球企业带来生成式 AI 推出用于创建大型语言模型和视觉模型的云服务

开源大模型FLM-101B:训练成本最低的超100B参数大模型






 工商网监
工商网监
评论