 无需翻译的无监督复述的新方法:允许从输入句子生成多样化、但语义上接近的句子
无需翻译的无监督复述的新方法:允许从输入句子生成多样化、但语义上接近的句子

无需翻译的无监督复述的新方法:允许从输入句子生成多样化、但语义上接近的句子。模型基于矢量量化自动编码器(VQ-VAE),可以在单纯语言环境中解释句子。它还具有独特的功能,即与量化瓶颈并行的残余连接,可以更好地控制解码器熵并简化优化过程。
近年来,研究人员一直在尝试开发自动复述的方法,复述就是对相同语义的不同表达,例如一句话,可以有一千种说法。这需要从文本中自动抽象语义内容。
由于缺乏可用的复映对标记数据集,目前更多的是使用依赖于机器翻译(MT)技术的方法,已经被证明非常受欢迎。
理论上来看,翻译技术可能是自动复述的有效解决方案,因为翻译技术是从语言实现中抽象出语义内容。例如,将相同的句子分配给不同的翻译者,最终翻译出来的内容通常是有差别的,这样就得到一个丰富的解释集,在复述任务中可能会非常有用。
尽管许多研究人员已经开发出基于翻译的自动复述方法,但显然人类并不需要翻译才能解释句子。
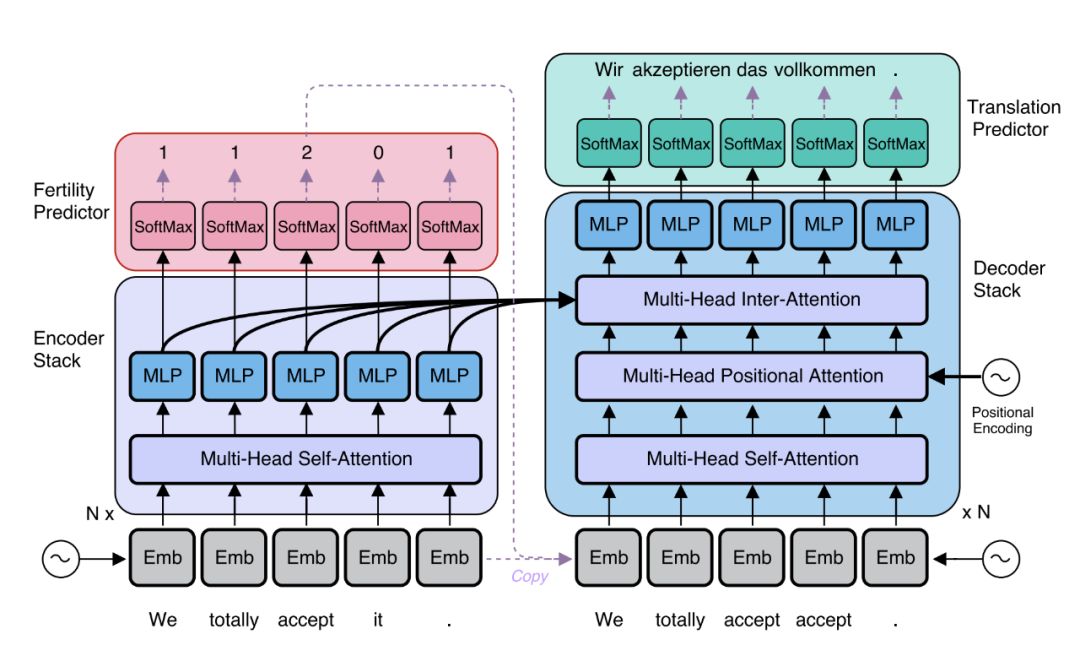
基于这一观察结果,Google Research的两位研究人员最近提出了一种新的复述技术,可以不依赖机器翻译的方法。
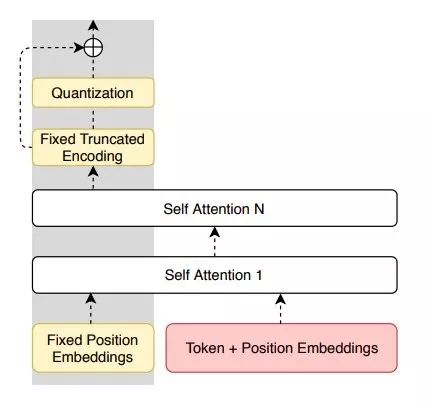
在预先发表在arXiv上的论文中,他们将这种单语方法与其他翻译技巧进行了比较(例如监督翻译和无监督翻译方法),该论文被引用了47次。
进行这项研究的两位研究人员Aurko Roy和David Grangier在他们的论文中写道:“这项工作建议只从未标记的单语语料库中学习复述模型…为此,我们提出了矢量量化变分自动编码器的残差变量。”
Aurko Roy
David Grangier
研究人员介绍的模型基于矢量量化自动编码器(VQ-VAE),可以在单纯语言环境中解释句子。同时,它还具有独特的特征(即与量化瓶颈并行的残余连接),这使得能够更好地控制解码器熵、并简化优化过程。他们的模型只需要在一种语言中使用未标记的数据:即用语言来解释句子。
研究人员在论文中解释道:“与连续自动编码器相比,我们的方法允许从输入句子生成多样化、但语义上接近的句子。”
在研究中,Roy和Grangier将他们的模型表现与其他基于MT的方法在复述识别、生成和训练增强方面的表现进行了比较。
他们特别将这种方法,与在平行双语数据上训练的监督翻译方法、以及在两种不同语言的非平行文本上训练的无监督翻译方法进行了比较。
研究人员发现,他们的单语方法在所有任务中均优于无监督翻译技术。另一方面,他们的模型和监督翻译方法之间的比较产生了混合的结果:单语方法在识别和增强任务中表现更好,而监督翻译方法在复述生成方面表现更好。
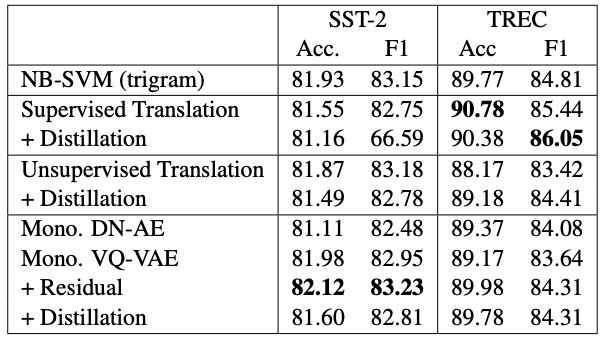
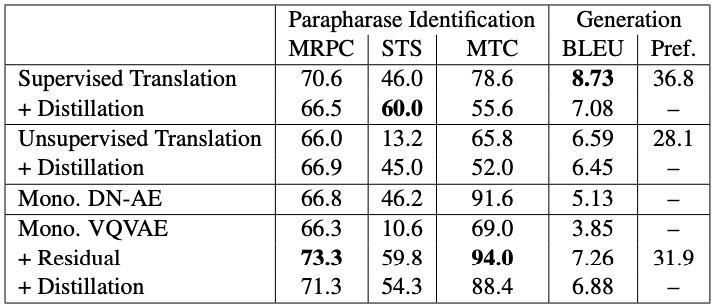
研究人员总结道:“总的来说,我们发现在进行复述识别和数据增强方面,单语模型可以胜过双语模式。单语模型的生成质量要高于基于无监督翻译的模型,但并不高于基于有监督翻译的模型。”
Roy和Grangier的研究结果表明,虽然使用双语并行数据(即文本及在其他语言中的可能翻译)在产生复述能够得到更卓越的表现。然而,在双语数据不易获得的情况下,谷歌研究院提出的单语模型可能是一种有用的资源或替代解决方案。
-
解码器
+关注
关注
9文章
1225浏览量
43769 -
谷歌
+关注
关注
27文章
6259浏览量
111978 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:谷歌NLP新方法:无需翻译,质量优于无监督翻译模型
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
无刷直流电机反电势过零检测新方法
NLPIR语义分析是对自然语言处理的完美理解
深入挖掘通用句子编码器的每个组成部分
一种改进的句子相似度计算模型
英汉机器翻译中基于模式的译文生成
汉语句子联想生成器
以语义、句式以及变量为基础的翻译方法
基于分层组合模式的句子组合模型
基于LDA模型的句子主题特征
句子相似度计算方法
自然语言的语义表示学习方法与应用
脑机接口最新研究能将神经信号直接映射为句子
一种无监督下利用多模态文档结构信息帮助图片-句子匹配的采样方法



评论