 DeepMind最新研究通过函数正则化解决灾难性遗忘
DeepMind最新研究通过函数正则化解决灾难性遗忘
当遇到序列任务时,神经网络会遭受灾难性遗忘。DeepMind研究人员通过在函数空间中引入贝叶斯推理,使用诱导点稀疏GP方法和优化排练数据点来克服这个问题。今天和大家分享这篇Reddit高赞论文。
这篇由DeepMind研究团队出品的论文名字叫“Functional Regularisation for Continual Learning”(持续学习的功能正规化)。研究人员引入了一个基于函数空间贝叶斯推理的持续学习框架,而不是深度神经网络的参数。该方法被称为用于持续学习的函数正则化,通过在底层任务特定功能上构造和记忆一个近似的后验信念,避免忘记先前的任务。
为了实现这一点,他们依赖于通过将神经网络的最后一层的权重视为随机和高斯分布而获得的高斯过程。然后,训练算法依次遇到任务,并利用诱导点稀疏高斯过程方法构造任务特定函数的后验信念。在每个步骤中,首先学习新任务,然后构建总结(summary),其包括(i)引入输入和(ii)在这些输入处的函数值上的后验分布。然后,这个总结通过Kullback-Leibler正则化术语规范学习未来任务,从而避免了对早期任务的灾难性遗忘。他们在分类数据集中演示了自己的算法,例如Split-MNIST,Permuted-MNIST和Omniglot。
通过函数正则化解决灾难性遗忘
近年来,人们对持续学习(也称为终身学习)的兴趣再度兴起,这是指以在线方式从可能与不断增加的任务相关的数据中学习的系统。持续学习系统必须适应所有早期任务的良好表现,而无需对以前的数据进行大量的重新训练。
持续学习的两个主要挑战是:
(i)避免灾难性遗忘,比如记住如何解决早期任务;
(ii)任务数量的可扩展性。
其他可能的设计包括向前和向后转移,比如更快地学习后面的任务和回顾性地改进前面的任务。值得注意的是,持续学习与元学习(meta-learning)或多任务学习有很大的不同。在后一种方法中,所有任务都是同时学习的,例如,训练是通过对小批量任务进行二次抽样,这意味着没有遗忘的风险。
与许多最近关于持续学习的著作相似,他们关注的是理想化的情况,即一系列有监督的学习任务,具有已知的任务边界,呈现给一个深度神经网络的持续学习系统。一个主要的挑战是有效地规范化学习,使深度神经网络避免灾难性的遗忘,即避免导致早期任务的预测性能差的网络参数配置。在不同的技术中,他们考虑了两种不同的方法来管理灾难性遗忘。
一方面,这些方法限制或规范网络的参数,使其与以前的任务中学习的参数没有明显的偏差。 这包括将持续学习构建为顺序近似贝叶斯推理的方法,包括EWC和VCL。这种方法由于表征漂移(representation drift)而具有脆弱性(brittleness)。也就是说,随着参数适应新任务,其他参数被约束/正规化的值变得过时。
另一方面,他们有预演/回放缓冲方法,它使用过去观察的记忆存储来记住以前的任务。它们不会受到脆弱性的影响,但是它们不表示未知函数的不确定性(它们只存储输入-输出),并且如果任务复杂且需要许多观察来正确地表示,那么它们的可扩展性会降低。优化存储在重放缓冲区中的最佳观察结果也是一个未解决的问题。
在论文中,研究人员发展了一种新的持续学习方法,解决了这两个类别的缺点。它是基于近似贝叶斯推理,但基于函数空间而不是神经网络参数,因此不存在上述的脆弱性。这种方法通过记住对底层特定任务功能的近似后验信念,避免忘记先前的任务。
为了实现这一点,他们考虑了高斯过程(GPs),并利用诱导点稀疏GP方法总结了使用少量诱导点的函数的后验分布。这些诱导点及其后验分布通过变分推理框架内的KullbackLeibler正则化项,来规范未来任务的持续学习,避免了对早期任务的灾难性遗忘。因此,他们的方法与基于重播的方法相似,但有两个重要的优势。
首先,诱导点的近似后验分布捕获了未知函数的不确定性,并总结了给定所有观测值的全后验分布。其次,诱导点可以使用来自GP文献的专门标准进行优化,实现比随机选择观测更好的性能。
为了使他们的函数正则化方法能够处理高维和复杂的数据集,他们使用具有神经网络参数化特征的线性核。这样的GPs可以理解为贝叶斯神经网络,其中只有最后一层的权重以贝叶斯方式处理,而早期层的权重是优化的。这种观点允许在权重空间中进行更有效和准确的计算训练程序,然后将近似转换为函数空间,在函数空间中构造诱导点,然后用于规范未来任务的学习。他们在分类中展示了自己的方法,并证明它在Permuted-MNIST,Split-MNIST和Omniglot上具有最先进的性能。
实验简介
研究人员考虑了三个持续学习分类问题中的实验:Split-MNIST,PermutedMNIST和Sequenn Omniglot。他们比较了其方法的两种变体,称为功能正则化持续学习(FRCL)。
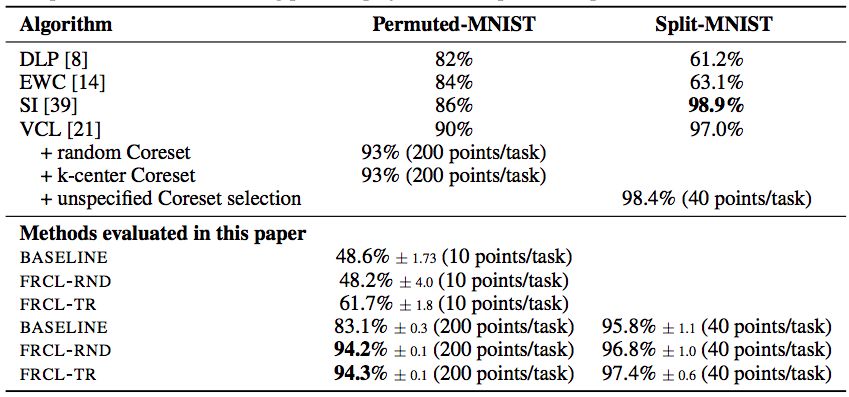
表1:Permuted-MNIST和Split-MNIST的结果。对于在这项工作中进行的实验,他们显示了10次随机重复的平均值和标准差。在适用的情况下,他们还会在括号中报告每个任务的诱导点/重放缓冲区大小的数量。
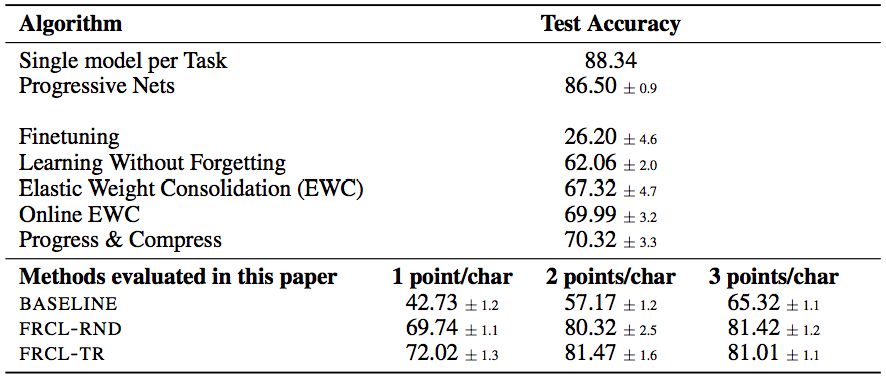
表2:Sequential Omniglo的结果。所示为超过5个随机任务排列的平均值和标准偏差。请注意,由于不现实的假设,“每个任务的单一模型”和“渐进网络”方法不能直接比较。他们将其包括在内,因为它们为其余的持续学习方法提供了性能的上限。
他们将自己的方法与文献中的其他方法进行比较,引用公布的结果,并使用与简单的重放-缓冲方法相对应的附加基线(BASELINE)进行持续学习。对于所有实现的方法,即FRCL-RND,FRCL-TR和BASELINE,他们不在共享特征向量参数θ上放置任何额外的正则化器(例如“2惩罚”或批量规范化等)。
鉴于Permuted-MNIST和Omniglot是多类分类问题,其中每个第k个任务涉及对Ck类的分类,他们需要推广模型和变分方法来处理每个任务的多个GP函数。正如他们在补充中详述的那样,这样做很简单。FRCL方法已使用GPflow实现。

图1:左栏中的面板显示随机诱导点(BASELINE&FRCL-RND;见顶部图像)和相应的最终/优化诱导点(FRCL-TR);请参阅Permuted-MNIST基准测试的第一项任务。诱导点的数量限制为10个,每行对应于不同的运行。右栏中的面板提供随机诱导点的tsne可视化,最终/优化的那些将一起显示所有剩余的训练输入。为了获得这种可视化,他们将tsne应用于训练输入的完整神经网络特征向量矩阵ΦX1。
讨论与未来研究
研究人员引入了一种用于监督连续学习的函数正则化方法,该方法将诱导点GP推理与深度神经网络相结合。该方法构造特定于任务的后验信念或总结,包括对函数值的诱导输入和分布,这些函数值捕获了与任务相关的未知函数的不确定性。随后,任务特定的总结使他们能够规范持续学习并避免灾难性的遗忘。
关于使用GPs进行在线学习的相关工作,请注意先前的算法是以在线方式学习单个任务,其中来自该任务的数据依次到达。相比之下,论文提出了一种处理一系列不同任务的连续学习方法。
未来研究的方向是强制执行固定的内存缓冲区,在这种情况下,需要将所有先前看到的任务的总结压缩为单个总结。最后,在论文中,他们将该方法应用于具有已知任务边界的监督分类任务,将其扩展到处理未知任务边界,并考虑在其他领域的应用,如强化学习。
-
神经网络
+关注
关注
42文章
4772浏览量
100793 -
函数
+关注
关注
3文章
4332浏览量
62645 -
DeepMind
+关注
关注
0文章
130浏览量
10869
原文标题:Reddit热议!DeepMind最新研究解决灾难性遗忘难题
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
*** 灾难性故障,求救,经验分享
未来的AI 深挖谷歌 DeepMind 和它背后的技术
如何创建正则的表达式?
AD画图出现“灾难性故障 (异常来自 HRESULT:0x8000FFFF (E_UNEXPECTED))”
DeepMind破解灾难性遗忘密码,让AI更像人
Batch的大小、灾难性遗忘将如何影响学习速率
在没有灾难性遗忘的情况下,实现深度强化学习的伪排练

实现人工智能战略性遗忘的三个方法
python正则表达式中的常用函数
基于先验指导的对抗样本初始化方法提升FAT效果
准确性超Moshi和GLM-4-Voice,端到端语音双工模型Freeze-Omni






 工商网监
工商网监
评论