 Analytics Zoo: 统一的大数据分析+AI 平台
Analytics Zoo: 统一的大数据分析+AI 平台
5月25日-26日,由中国人工智能学会主办,南京市麒麟科技创新园管理委员会与京东云共同承办的2019全球人工智能技术大会(2019 GAITC)在南京紫金山庄成功举行。
在第一天的主论坛上,英特尔高级首席工程师、大数据技术全球 CTO戴金权发表了主题为《Analytics Zoo: 统一的大数据分析+AI 平台》的精彩演讲。
戴金权
英特尔高级首席工程师、大数据技术全球 CTO
以下是戴总的演讲实录:
在英特尔如何构建统一的大数据分析+AI 平台(我们称为开源项目),帮助客户更高效地开发大数据、大规模深度学习的应用。英特尔致力于提供端到端,从设备端到边缘,再到数据中心云端完整的计算架构,比如在数据中心,今天英特尔志强服务器是 AI 应用分析的基础架构,月提供了多种像神经网络处理器等丰富的硬件架构。同样在软件上,我们也是致力于提供全站的解决方案,从最底层的核心算子开源项目可以帮助用户更高效开发他们的计算库;再到上层各种机器学习或者深度学习的框架,比如对开源的 Analytics Zoo,深度学习做了大量的优化工作;再到最上层,也提供了一些开源工具包,目的是帮助应用开发人员更高效地开发基于深度学习的应用。
今天在这里着重分享的是基于大数据分析处理的框架上开发并且开源的两个项目,一个是 BIGDL,是我们两年半以前开源的一个深度学习的框架;在这个基础上,去年又开源了 Analytics Zoo,构建一个端到端的大数据分析 + 深度学习的平台。为什么在英特尔开发,并且开源基于大数据平台上的大数据分析 +AI 的平台工具?
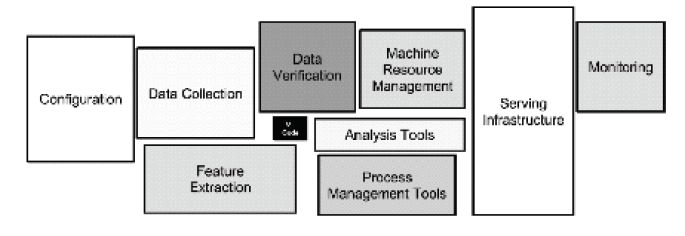
下图中黑色的小框代表机器学习或者深度学习的模型,它很关键,从某种意义上决定了硬件有怎样的功能,做到怎样的事情。但是会发现,当想把这样一个深度学习、机器学习模型应用到实际场景,从实验室搬到现实工业级机器学习中,构建这样的端到端应用是非常复杂的,要有大量的其他模块,比如怎样收集数据、处理数据和验证数据,包括资源管理、集群监控等。整个端到端的流水线是由一个非常多的模块组成的,一个端到端大数据处理分析再加上深度学习、机器学习的流水线。
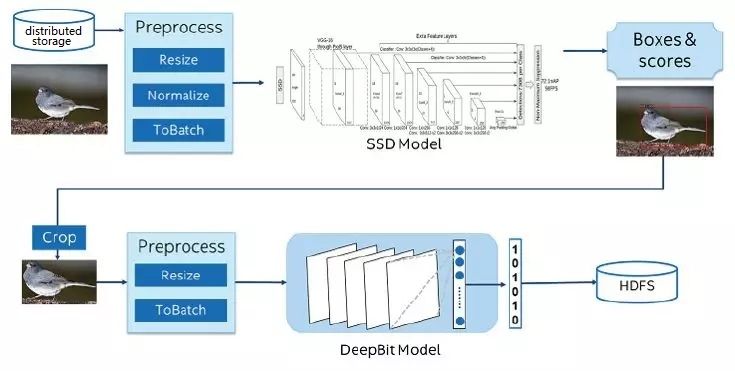
下图是我们在两年前和京东的一个合作。京东带来的几亿张图片,存储在一个大规模分布式大数据集群里,我们做的事情是要对这些图片——识别物品。比如,这张图片上是一只鸟,然后提取特征。从深度学习、机器学习来说,不是特别复杂的应用,做物品识别、提取持证就可以了。但是事实上发现,在对大规模的图片读取数据,对图片进行分布式处理,再进行模型推理;当识别物品时,对物品进行抽取,再进行处理,再提取特征等,把整个端到端流水线在大规模的图片里是跑不好的。当要把这些机器学习、深度学习等技术应用到实际应用中,会有一个比较大的断层,今天很多的科学家做了非常多的深度学习、机器学习的有效工作,但是如何将新技术、新创新应用到现实环境中,特别是在一些非常大规模、大数据生产系统中,从软硬件架构上有非常大的一个断层。这就是为什么我们会去开源,像BIGDL,特别是 Analytics Zoo 平台,能够将不同的模块不管是用 TensorFlow 还是用Keras,将这些不同模块的程序能够无缝运行在端到端流水线上,大大提升开发效率。
总之,我们开发并且开源的目的是让大家更加方便开发大数据、大规模深度学习的应用。通常很多用户开始开发应用时,可能在一个笔记本上构建一个简单原形,当你觉得原形看还不错时,希望可以跑历史数据,对过去几个月或者几年的数据进行一些验证,为端到端的流水线构造原形。在实验上觉得效果还不错,就希望部署到生产系统中,可能进行上线。同时也是大规模、大数据处理的流水线,可以让你的程序运行在一个大标准集群里,直接利用现有的大数据集群、大数据计算资源运行你的程序,从而能够提高你进行开发并且部署深度学习应用的效率。
有关 Analytics Zoo 一些技术细节的构成。总的来说,构建在很多不同底层计算的库和框架上,在上面构建一些丰富的流水线支持;再上面也提供了一些解决方案,包括预定模型。
下面来看一下具体的例子。有人和我说不要放太多代码在里面,用 Spark 构建一个 RDD,对大规模数据进行分布式处理。对各种各样的数据源,不管是数据仓库的方式,还是读写数据库,或者是读写各种各样的分布式文件系统,可以直接使用 Spark Dataframe。下面的图片是说,如能够使用刚才训练的模型,就可以使用我们的模型推理进行大规模分布式应用,在自己 Keras 等框架内都很容易将我们深度学习模型集成在这些流水式处理或者在线处理中,而且在这个背后也可以透明地使用像 Analytics Zoo 的工具,对模型进行压缩加速,包括至强深度学习加速指令对它进行加速;同时可以跑在大规模集群上进行分布式推理。

我们真正的用户是怎么具体使用的?解决他们什么问题?下图是我们和美的的合作,他们希望通过计算机视觉将其生产线生产出来的产品自动识别瑕疵、没有贴标签等。

工业机器人接上摄像机,对流水线出来的产品进行拍照,拿到照片后进行识别,产品上是不是有缺陷。比如,下图中可以看到空调上少了一个螺丝。上图中,粉红色是对大规模图片进行处理;黄色是 SSDLite这样的一个模型,使用 Analytics Zoo API和 Spark 数据可以整合起来,在 Spark 上进行训练。
下面这个例子是我们和微软中国团队的合作,他们希望给大家提供客户。比如,他们有一个微信公众号,在他们的微信公众号上可以提问题,如怎么联不上我的虚拟机、怎么重启我的虚拟机、怎么开发票等。原来他们的做法是,在特定领域完成特定任务的对话。上午的报告中有很多专家提到,在垂直领域定义模版。他们有很多定义好的流程,可以随着流程走。现在很多人不随着流程走,随便问一些问题,怎么开不了发票?因为内部有大量知识库和准备好的问答,通过关键词的匹配可以帮你去搜索,搜索出一些文章,希望满足你的问题。这里,希望我们帮他做一些问答匹配,把相关的回答反馈给用户,用户看到这些问题后,可能解决了他的问题或者没有;如果没有解决,就要转人工处理。转人工处理是非常昂贵的事情,不同的问题要转到不同的后台,所以要有对意图进行分类的模块,将问题做一些分类,到底是财务的问题,还是网络的问题,还是虚拟机的问题。
Office Depot,卖办公用品的一个电商,做一些产品的推荐,当把一个物品加入到购物车后,根据你的行为推荐一些相关的物品。这是一个跑在云上的应用,使用 Spark 和 Analytics Zoo 上进行训练,使用 mleap 就可以直接将 pipeline 模型保存下来,训练出来的模型直接部署在 AWS S3,通过 BigDL 把它部署在一个 DNN 进行在线推理。
万事达,希望给大家推送一些促销信息,到哪里去购物,我给你一个立减等类似的优惠,希望把这些推送到相关的客户,客户收到这些信息后会买东西。但是有一个特别的问题,我们会根据用户过去购买行为进行分析,将用户过去的购买行为、交易的数据是放在数据库里的,怎样能够在Apache Hadoop 现有集群上运行这些新的深度学习应用?这时就可以使用 Analytics Zoo 深度学习框架,可以在现有大数据分析集群上,和其他的业务共享同一个集群,来运行这些新的深度学习应用。
CENR,欧洲的盒子研究中心,他们每天都在进行每秒大约 4 000 万原子对撞,产生 1 TB 数据,他们希望把这些数据存下来;希望有一个过滤机制,将有用的事件保留、存储下来。这样做可能每秒只存不超过 10 GB 的数据,这些数据可以用于以后的分析。他们希望过滤的越准确越好,因此分为三种事件,构建了一个深度学习模型,通过深度学习进行学习分类,将这些数据精确分析,用于以后的工作中。你可以很方便地在 Analytics Zoo 在单机上进行验证,直接运行在一个分布式环境里进行训练,最后训练出结果。因为每秒都会产生 1 TB 数据,所以需要一个在线的、类似于像流式处理的平台,这里他们用了 Spark DataFrame 进行在线预测,对原子对撞事件进行分类。
怎么应用 Analytics Zoo ?比如在阿里云上面部署 EMR,使用 Analytics Zoo。
最后总结一下。我们之所以构建Analytics Zoo 这样的统计大数据分析 +AI平台,就是希望能够让用户在现实的生产环境中可以更方便构架深度学习的应用,将各种不同的模块、不同的框架下统一到一个端到端流水线上,大大提高客户开发部署大数据分析和深度学习的能力。
-
AI
+关注
关注
87文章
30763浏览量
268913 -
阿里云
+关注
关注
3文章
952浏览量
43010
原文标题:演讲实录丨戴金权 Analytics Zoo: 统一的大数据分析+AI 平台
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
LLM在数据分析中的作用
raid 在大数据分析中的应用
emc技术在大数据分析中的角色
云计算在大数据分析中的应用
使用AI大模型进行数据分析的技巧
IP 地址大数据分析如何进行网络优化?






 工商网监
工商网监
评论