 视觉对话能力让AI迈上新台阶
视觉对话能力让AI迈上新台阶
正如《2001太空漫游》《流浪地球》等科幻大片中无障碍的人机对话系统所描绘的那样,拥有智能视觉对话能力的AI随着技术的不断突破,正在向我们走来。
每个人都有这样的回忆,小时候语文老师教我们看图说话,许多小朋友脑洞大开,说出来的答案让人啼笑皆非。实际上,看图说话的能力在年幼时期需要训练,而对于大一点孩子来说就不成问题了。如今,机器人也能做到看图说话了。
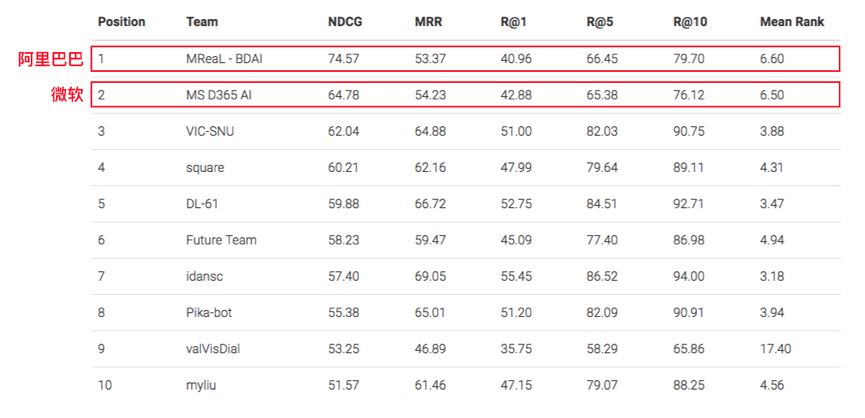
近日,来自中国AI在这项能力上已经打破了世界纪录。在第二届全球AI视觉对话竞赛(Visual Dialogue Challenge)中,阿里AI击败了微软、首尔大学等十支参赛队伍,一举获得冠军。
阿里AI在视觉对话竞赛中得冠
会“看图说话”的AI有多聪明?
这场视觉对话竞赛由美国佐治亚理工大学、Facebook人工智能实验室(FAIR)等机构联合全球视觉技术领域顶级学术会议CVPR发起,是目前视觉对话领域最权威的竞赛之一。
该竞赛要求参赛的AI在看完近万张图片后,回答出人类对于任一图片任一内容的提问。这要求AI不仅能够描述出图片中内容的概况,还要经得起人类对图片各种细节的追问。比如,在一张撑着雨伞的人物图片中,说出伞是什么颜色的,有多少人在图中,附近有什么物品和建筑物等等信息。
视觉对话中AI可以从容应对人类提问(左为AI、右为人类)
竞赛结果显示,阿里AI以74.57%的准确率获得冠军,将上一届比赛的纪录提高了16.82%,并且超过微软AI的64.78%的准确率。而在相同的数据集中,人类的准确率仅为64.27%,AI甚至胜过了人类。
传统的视觉AI主要针对目标的检测和识别,但对复杂场景中目标之间的逻辑关系理解、推理能力较弱,无法回答表达图片对象直接关系的复杂问题,也难以将图片信息转化为人类理解的语言输出。
这意味着,要实现视觉对话能力,传统的视觉AI在学会“看图”之后,还要有一种语言模型来支撑它“说话”。阿里AI的突破就在于提出了“递归探索对话模型”。
视觉对话AI与用户交流图像内容
这一模型通过标注信息学习出模仿人类认知复杂场景的思维方式,能识别图片里的实体以及它们之间的关系,推理出图片所描述的事件内容,并通过对上下文进行有效建模,综合集成了图像识别、关系推理与自然语言理解三大能力,能理解人类提出的问题及真实意图,给出自然准确的回复。
视觉对话能力让AI迈上新台阶
AI能“看图说话”,这样的应用其实距离我们并不遥远,微软之前推出了一款年龄测试工具How-old.net ,曾经刷爆微博和朋友圈,所应用的就是这一技术的应用。
目前微软还开放了能“看图说话”的AI系统,用户进入官网上传图片,稍等一会,就能看到系统对于图片的描述。其准确率虽然不低但依旧有待提升,以一张曾经广为流传的黑人问号表情图片为例,AI很快给出了客观的回答:“我觉得这是篮球队员尼克·杨露出牙齿微笑。”
AI视觉对话识别图片信息
以“看图说话”为代表的视觉对话是近年来快速崛起的AI研究方向,目的在于教会机器用自然语言与人类讨论视觉内容,这能够使机器拥有了对真实视觉世界的理解与推断能力,也意味着AI的认知能力将迈上新的台阶。
可以预见,这项技术未来将被应用在人机交互诸多场景:
在火灾、地震后在废墟中寻找幸存者的救援机器人,能够代替人类之眼,深入危险的现场,及时、高效地综合指挥指令和场景信息作出行动。
视觉对话技术有望人类提高地震救援效率
视障人士可以通过提问AI,理解图像中的内容,了解自身所处的周围环境,为其生活起居带来更多的便利。
无人驾驶车辆也可以在行驶中通过视觉对话,更加准确理解人类意图征询人类的意见,让乘客的乘坐体验更好。
正如《2001太空漫游》《流浪地球》等科幻大片中无障碍的人机对话系统所描绘的那样,拥有智能视觉对话能力的AI随着技术的不断突破,正在向我们走来。
-
机器视觉
+关注
关注
162文章
4425浏览量
120961 -
AI
+关注
关注
87文章
32069浏览量
270959
原文标题:机器人看图说话能力比肩人类!中国AI超越微软,打破世界纪录
文章出处:【微信号:jingzhenglizixun,微信公众号:机器人博览】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
天津检验中心智创团队:致力于构建全球领先的智能网联汽车测试能力
鼎捷雅典娜接入DeepSeek大模型,加速 AI 应用创新布局
HarmonyOS NEXT 应用开发练习:AI智能对话框
AI对话魔法 Prompt Engineering 探索指南

中科曙光推动液冷技术产业加速落地
对话蓝牙技术联盟首席执行官Neville Meijers
消息称苹果正在洽谈投资OpenAI
AWS与Workday深化合作,推进生成式AI功能开发
纳宏光电荣获ISO9001:2015质量管理体系认证及IATF16949:2016车规质量体系认证,品质管理再上新台阶

聆思CSK6视觉语音大模型AI开发板入门资源合集(硬件资料、大模型语音/多模态交互/英语评测SDK合集)
【AIBOX快速入门】2步玩转AI对话

台阶仪测量膜厚怎么测

华为助力电信安全公司和江苏电信实现DDoS攻击“闪防”能力

和芯星通获ISO14001环境管理和ISO45001职业健康安全管理体系认证






 工商网监
工商网监
评论