 从0到1学习计算机视觉技术
从0到1学习计算机视觉技术
叶聪, 现任腾讯云AI产品中心高级研发工程师,前美国亚马逊 AWS 人工智能技术经理,负责领导开发了 Amazon Alexa 智能语音助手背后的AI云服务Lex。在多年的云计算系统研发经历中,负责了领导了多个百万用户级产品的架构设计和开发,并且具有丰富的跨国团队和项目管理经验。美国明尼苏达大学电子工程及计算机系硕士,其后在斯坦福大学攻读研究生证书。

1
朋友圈爆款活动背后的秘密
很荣幸受到云加社区邀请来做这次分享。我们将主要分六个部分来介绍,首先我想和大家介绍一下最近风靡朋友圈的爆款计算机视觉小游戏的背后是怎么回事儿。然后会由浅入深一步步从最基础的计算机视觉技术知识,快速地带大家去了解一些学习计算机视觉技术需要哪些技术知识。之后会再谈谈计算机视觉技术的历史和最近兴起的深度学习方法。同时会告诉大家在这背后的云端AI能力是如何支撑的,最后会给不同层次的想要学习计算机视觉技术的朋友们一些技能进阶的建议。

今年我们组织了一场五四青年节的活动,大家上传自己的照片,就能匹配到民国时期的一些人物。这个应用背后就利用到了人脸匹配技术,我们会利用一些算法来匹配到跟你长相最相似的人物。这个活动当时反应可以说是非常热烈的,相信不少人也参与过这个活动。
其实类似的活动还有很多,比如军装照等,回到人脸融合等等。这些应用都是运用了人脸融合的技术。
2
计算机视觉基础知识
如果我们想要去学习一些计算机视觉技术的话,我们要先从历史上了解计算机视觉技术是如何从幕后走到台前来的。首先计算机视觉定义是怎么样的?其实从很多的书上不同的材料上都会对这些区别有不同的定义。

我比较喜欢的定义是从工程学的角度来讲,计算机视觉是使机器模仿人的视觉的能力和任务变成自动化。我们人可以通过我们的视觉去理解信息。现在的计算机视觉机器学习算法,可以把这个流程变成一个自动的形式。
计算机视觉其实呢包含很多的分支,包括比如物体识别、语义分割、运动追踪、三维重建、视觉问答(VQA)、还有动作识别等等。
随着计算机视觉算法模型的日渐强大,它的使用面越来越广,几乎在所有我们人眼可以识别的领域,计算机视觉将会逐步的一个一个的去替换掉。所以从总体来说这个场景是非常广阔的,潜力是非常巨大的。
底下有几张照片,左下角那张呢是非常经典的应用叫人脸识别(Facial Recognition),中间的是现在非常火热的无人驾驶,右边的就是是情景分割(Semantic Segmentation)。情景分割这个词其实是有一些不同的含义的,在LP领域也有情景分割这个说法,不过他是对一句话中的不同的词或词性,甚至是一些语义进行一些分割。
而计算机视觉领域的语义分割稍微有些不同,它是对一个图像里的元素进行像素层面的细致的区分。上面右边这张图我们可以看到比如植物是绿色的,道路是灰色的,人是红色的,然后汽车是蓝色的,这些都是一些非常细致的Pixel Level。

非常有意思件事是我们人类去了解一个东西的颜色,我们是可以通过我们的眼睛的视网膜成像的,但是机器它是怎么去读这个图像的呢?这就要提出一个叫做RGB的概念。
什么是RGB?RGB就是Red,Green and Blue红绿蓝三种颜色。理论上自然界的所有的色彩都可以用这三种颜色来进行描述,计算机会把每种颜色给予一个八位的一个二进制去表示,也就是25种不同的数字去描述一个像素点。
这就非常有意思了,3*8位是24位,那但是现在我们大家所说的这个真彩色是32位,那这里的八位是什么?其实它是一个叫Alpha channel。它是一个代表一个图像,某个像素是不是透明的,它是一个透明值,所以就是3×8+8,最后就是32位。 24位的颜色我们以前叫做全彩色,而32位是真彩色,现在大家只要用RGB去表示图像,那基本上我们说32位的话都是带着个八位的Alpha Channel的。
我们可以看到PPT上面右边有三张图。最上面那张就是黑白的灰度图,中间一张呢就是我们刚才说的全彩图,而下面一张就是真彩图,这张图加了八位的透明Channel在里面。

计算机视觉的素材还是非常多的,不仅仅是刚才看到那些大家用手机单反相机拍摄出来的照片,我们还有很多在大气天文医疗领域的。比如左边是航拍热成像图,中间有我们的胸的这种ct图X光图,然后还有右下角的是一些超倍显微镜看到的一些非常小的细微的人眼无法看到的图,这些都是计算机视觉可以去学习去应用的素材。接下来聊一下计算机视觉的处理的分级。

(计算机视觉处理分级)
这个分级其实是为了帮助我们更好的去理解计算机视觉所要解决的一个任务,它分为Low Level, Mid Level和High Level.听名字好像他们分别对应的就是低中高三个级别,但其实Low Level意思是我们离这个问题的细节比较近,而High Level比较远,比如像Low Level中间有降噪这一项。大家可以试想一个场景,我们离这个照片的每个细节非常近的情况下,我们才可以处理这些噪点,反过来讲High Level的话就比较高,比如像Scene Understanding就是对这个情景的理解,这种情况是需要我们要对整个图有个宏观理解才能进行处理。

我们先来看看Low Level Processing中的一些常见例子,它包括降噪,强化,压缩和标记,可以说它的使用范围已经非常广泛了。比如左边一张是我们拍的胸部的X光图。如果我们去医院拍张片子,基本上就是我们看到的是下面一张图,而不是上面那张。但上面那张其实是原片,计算机视觉的Low Level Processing可以利用各种算法对这个图片的景深进行加强,在一些暗部进行强化,在一些亮部进行减弱,从而使这张图片变得很清晰。我们由一张比较混沌的图片中间经过优化,可以看到他非常清晰的骨骼血管这些脉络,这就是图像处理的厉害的地方。
右边是一个pcb板的图,这是一个工业界的应用,原片上面充满了噪点。很多素质并不高的照相机拍出来的效果基本上就是这样,经过降噪的处理之后,它就可以变成非常清晰的pcb的图。我们可以清晰地看到每一条电路,每一个模块。
底下一张是航拍图,由于云和雾霾等各种因素,这种航拍图是非常模糊的,那经过将近十节的enhancement的强化之后,我们可以加强景深对比路,能够很清晰地看到图上对象的实体,包括建筑和机场。右边是registration,它等于把两张不同角度的图给对应上进行匹配,这也是一个很常见的应用。

Mid Level Processing包括Classification、Segmentation这些。我很喜欢左下角这张图,这张图是来源于斯坦福大学李飞飞教授的一门计算机视觉的入门课程,最左下角的这张图计算机识别处理叫分类(Classification),它仅仅从图片上识别出来这里有一只猫,并不知道这个猫的位置或者这只是什么猫,这是一个分类的问题,是属于Classification。
进一步的第二张图有个红色的框框,这个就是已经对图上的猫进行了一个定位,是Classification加上Localization,就是对图上的对象的定位。再进一步的话,我们从图上不仅看到了有猫,还有狗,还有小鸭子。整张图所有的对象都被识别出来了,这是一个典型的Object Detection场景,也就是对象检测。我们把图片上所有的对象很清晰地识别了出来。再进一步的话叫对象检测Instance Segmentation,这个意思就是我们不单知道图像上有哪些对象,我们还把它进行了一些划分。 划分的意思就是把一张图上的不同的元素可以区分出来并标注。
右边是我刚才我们之前复用的一张情景识别的图,它包括了行人,还有各种车辆。情景识别其实是左边所有的这个应用的一个更高层次的进化。从左到右可以看出,我们从只知道这个图上有什么发展到了我们能知道这个图上有所有的东西,包括在什么位置都可以知道,这就是我们在Mid Level Processing中是怎么一步一步的把一个图的所有信息给挖掘出来。

接下来我们会聊一下High Level Processing,这也是目前最火热的一个部分,包括左边的人脸识别。人脸识别其实就是根据我们人脸的一些模型,从脸上寻找到很多的特征点,即关键点,包括呢眉毛,眼睛的边框,然后对它进行匹配建模。
人脸底下是非常经典的人无人驾驶的图,这方面有非常多不同的实现方式,总体来说包括用激光雷达和无激光雷达两种,无人驾驶也是未来的一个趋势。现在全世界范围内做无人驾驶的公司非常多,国外比较出名的包括特斯拉,这是一家非常执着于不使用激光雷达,只是用计算机视觉方式去解决无人驾驶问题的公司。其他用雷达公司就非常多,比如通用汽车福特,包括欧洲的一些公司,国内的话也有很多。
中间这张呢是Scene Understanding,它其实就是对画面里的所有的元素和它们之间的关系以及他的行为进行全面识别。,和之前识别小猫小狗的区别在于,这张图片上面呢我们不仅识别到了有两个孩子,我们还识别到了他们手上拿的是什么,以及他在什么地方,甚至还有他们要做什么这一系列信息,,并把这些信息形成了一个对象树,上面不同的颜色代表不同的词性,比如谁在什么地方做什么,这些东西我们都从这个图上获得了。
这就是High Level Processing我们希望得到的一个结果。它不是简单的对一个图片或是单纯的对象的一个匹配和识别,而是对整张图片有一个全面的了解。
最右边一张是医学上心脏血管的这个造影图,这好像是英国某大学和英国皇家医学会合作做的一个项目。利用计算机识别的成像,可以在手术前让医生对患者的整个心血管有非常清晰的了解。因为它可以知道每个血管的血宽,在哪里可能有风险,利用这个技术的话,医生在做手术就可以大大的降低手术失败的风险,也可以大大的降低后续并发症的影响。这些都是High Level Processing的一些应用。

其他常见的计算机视觉的例子有人脸识别,OCR文本的识别,图上展示的是一个比较老的技术,它是用一个激光笔,可能比较老的一些公司会使用这种方式。用激光笔去扫描文字,然后把扫描的文字转换成文本。现在基本上已经不需要这种方法了,因为OCR技术已经非常成熟,只要大家清晰的拍一张照片,不管是中文还是英文,它都可以转换成一段非常清晰的文字,并没有任何什么问题,而速度会非常快。
右边的车牌识别,就是大家如果吃罚单但没看到交警,很多时候是由于这个技术。

接下来聊一个比较有趣的话题——目标跟踪。我对它评价是Full of potentials, but chanllenged.这个技术本身我觉得是非常有前景的,但是非常难。因为中间过程会有很多的因素影响最后的效果,所以目前来说这是一个很多人都在研究的热点,并且目前还没有。
首先我们上面看到这是一场NBA球赛的视频的截图,假如我们想追踪其中某一个球员的话,它会出现什么问题呢?首先它是在不断的移动的,对于摄像头而言它的位置是不断在变化的,所以会出现各种不同的形变,运动员的姿势也是在变的。
右边这张图也是由于各种灯光角度的照射强弱的问题,运动员在视频的截图上的看起来的样子是不一样的,它的光感也是不一样的,这也是一个匹配的难点。然后底下几张图显示图上可能会出现什么问题,比如人在快速移动的时候,视频中间会出现模糊,这是一个非常常见的现象,然后由于背景色可能跟前景色太过接近,背景可能会影响到前景色产生干扰,这也是非常常见的,那这几种情况呢都会影响目标跟踪的效果。
右边则是一些其他的例子,比如不同的角度,人的头可以旋转,可以遮挡,甚至在有些时候它会出在画面之外,这些情况都可以让一个目标跟踪算法的失败。如果大家对这个领域很有兴趣的话,可以考虑一下在这个领域做一些研究,因为目前来说并没有某一种算法可以很好很完美地解决这些问题,也说明这个方向的研究的潜力还是比较大的。

其实不仅是一个问题,我把这类问题统称为多模态问题——Multi-modal Problem.意思就是在解决问题的时候,我们需要不止一种机器学习的能力,还需要结合多种能力去实现。比如左边那个VQA,就是我们给出一张图片,任何的人可以去问一个问题,我们的模型要从图片中去识别,针对我们问的问题给出一个合理的答案。
比如这个右上角有两个宝宝,一个坐在冰箱里,一个在妈妈的怀抱里。 那如果我们问这个孩子坐在哪?首先第一步要有一个情景识别的一个引擎去理解这个图片,知道这图片里面有什么,比如有孩子,他在干什么,他坐在什么上,坐在冰箱里或者坐在妈妈怀抱里。另外呢还要有一个模型能去理解我们的这个问句,这个问题是什么?问的是在哪里?不是问是谁也不是问怎么样。而且对象是这个孩子,需要知道他在哪里坐着。这个例子等于需要两个模型来解决我们的问题,一个理解图,一个理解文字,还需要去匹配他们,它是一系列的不同的模型结合在一起,一个这个图像的识别的引擎,加上一个NLPU识别的引擎,还有一个匹配引擎,一起去协作才能解决这个问题。这就是很典型的一个多模态问题。
右边是Caption Generation的示例。 Caption Generation.就是根据图像自动生成一段描述该图像的文本语言。上面的这两张图片左边是一个女士在一个沙滩边散步,根据我们不同的情况,, 输入了不同的训练文本,我们就可以生成一些话去描述这个情景,右边是在公园也是一样的,后面我可以详细再聊一下机器是如何实现。
如果要想了解到机器学习每一步的发展,首先我们就要聊一聊一些为我们实现这个目的一些算法,也就是机器学习的图像应用的传统方法。
3
曾经的图像处理- 传统方法

首先我们要去做图像处理的时候,机器去理解图像的时候无法像人类一样去读取信息,我们必须要把它转化成机器能理解的这些数据,那应该怎么做呢?

首先我们就需要用一些滤波器从这图片中提取信息,把模拟的信号转换成数字信号。这些滤波器并不仅仅是使用在图像处理这个领域,包括信号处理,还有一些其他语音处理中间都会使用。常见的滤波器有几种,比如空间,傅里叶,还有小波滤波器等等,这几种是比较常见的。
那如果我们想要去对图像进一步的利用,我们还需要什么呢?首先我们要能够理解到这个图片中间它到底是怎么回事,达到这个目的的方式,就是我们要从这个图片中抓取一些特征,我们首先要设计这个特征。设计特征的方法有很多种,包括比如像SIFT,对称特性还有HOG。
拿到所有图片的特征以后,我们会做进一步的处理,使用的传统方法包括,比如SVM,AdaBoost,Bayesian等等。这些算法本身也不是图像识别领域而独有的,也是在长时间的过程中间,我们在不同的领域,包括语音LP我们都会去使用这种类似的方法。
大家会发现最终我们解决问题是可以归纳成一些比较统一的问题的,再进一步的话我们需要做这个图像对象的划分,还有识别的时候,还有一些很经典的一些算法。

这是一个非常好用也非常简单的一个提取图像特征的方法,叫做Edge Detection边缘检测,比如说左边这张图片是一个很多硬币的照片,我们可以其中提取到整个硬币的边缘,还有它其中花纹的边缘,这样我们就把这个图片的最重要的信息提取出来了。

这个叫Haar特征,Haar特征适用的场景会跟精确一些,整张图片在不同的地方会有不同的灰度变化,Haar特征其实就是描述反应灰度变化的。
它一般会分为几种描述的特征,包括边缘特征,线性特征,还有中心和对角的特征,这种特征会用黑和白来表示。一般定义的这种模板特征,白色减去黑色就是它的特征值相似和。整个Haar特征其实是反映这个图片的灰度变化的。
可能有人就会问了,说那很多时候图像的灰度变化并不完全是水平和垂直,所以Haar特征其实有一个进化的算法就是Haar like呢就是加入了45度角这个特性。
不管如何,它是有限度的方向,所以这就引出来后面几种算法,在Haar特征的解决不了问题或者效果不好的情况下,这些算法可以发挥效果。

比如像这种叫Local Symmetric局部对称性算法。局部对称性算法可以解决很多Haar特征提取效果不好的情况。它是根据我们一个对象的重心点的位置,越靠近重心点的越亮,越靠近边缘的话越暗,用一个重心的这个特征去代表这个对象。很多图片实际上是有一定的对称性的,比如像我们拍照的人,拍摄的一些房子,在物理上它都是有对称的特性的。所以利用这种局部特征对称性,就很容易提取这些照片中的一些有效信息。

下面聊聊到一个非常经典的算法叫尺度不变性,这里可能就要牵扯到一个尺度的概念。
什么是尺度?尺度空间其实是描述我们人从远到近看待事物的一个过程。比如我们看一片树林,我们只能看到树的轮廓,我们看不到每片叶子。但如果我们慢慢的靠近这个树,我们就能看到每个叶片,甚至能看到两片叶片的区别,看到叶片上的纹路是什么样的。其实这整个的变化就是一个尺度的一个变化。
尺度不变特性的使用方式是,我们会在这个图片上面去提取一些关键的尺度的点,在变化的时候,我们就尝试用这些不变的点去做匹配,在每个方向向量上去获得一些参数。然后利用这样的情况我们就可以去识别一些角度或是旋转之后都不太一样的照片。即使这个图片可能会有一些遮挡,只要它的尺度性的那个点没有被遮蔽,我们一样是可以去得获得识别的这种效果的。

还有一种跟灰度有关的方法叫HOG方向梯度直方图,它也是利用灰度的原理,把整个图形分成很多块,描述里面灰度变化最小的或者最大的。一般选用最小的方向。好处是它计算起来的成本比较靠谱的,比如这张图上,人穿黑色的衣服,所以在黑色衣服上它的灰度变化最小一定是垂直的。到了旁边白色背景可能就是水平的。利用它这个HOG的梯度图的方向,很容易把这个人从背景中间区分出来。
这个和刚才我们聊到的海尔特征区别在于,它其实对整个图像进行了一个全面的一个扫描。我们对图像进行扫描以后,就可以清楚地得到一个图像的灰度变化曲线。比如像这个图上的人,一般情况下同样一个类别的对象,他身上的灰度相对来说比较统一的。我们就把灰度变化最小的方向作为这个梯度的方向。这样的话这个图上的不同区间就会得到很好的划分。比如像人那他从他的臂膀到他的腿,整个的话都是一个灰度,基本上是不变的,在人身上的梯度的方向就是垂直的。
背景由于打光的各种的原因,它的方向一般是比较分散的,在各个方向都有。这样的话呢我们根据它梯度的变化方向,我们就可以把这个人从背景中很完美的抠出来,也就能识别到这个人。所以其实对象检测整个过程呢就是第一是要设计这个特征,第二呢就是做分类。把两个结合起来,我们就能实现对象检测的这个目的。
在对象检测之下,我们可能想要做分割,或者是其他的一些更高级一点的应用,那我们应该怎么办呢?

有一些比较经典算法,比如像分水岭算法,它其实也是基于一个灰度的变换的。我们会对整个图像进灰进行度扫描以后,可以把灰度深的地方想象成一个比较深的水沟,灰度浅的地方变成一个比较浅的水沟。在相邻的两个区域之间灰度联通的地方,我们可以去建一个水坝把他们给隔开。大家可以想象一幅图转换成了好多不同盆地的曲线图,然后我们慢慢往里面灌水。
应该说所有区域都是分开的,虽然我们灌水的程度慢慢变多,总会有两个相邻的区域相对来说要变连通,那这种情况我们需要在其中建一个大坝,然后把这个本来要连起来的区域我们人为隔开,然后我们继续往里灌水,就会有新的区域又被联通,然后我们再把它隔开。其实我们在放这个水坝隔开这个区域的时候,我们就把这个图片上的一个区域给分开了,这就是分层与算法也非常巧妙。
还有一个做对象检测的算法叫做ASM主观形状模型。

它就是把一个我们想要匹配对象的轮廓全部识别出来以后,进行各种的形变。然后尝试和我们一个想要去核对的一个目标进行匹配。但大家也能很容易想到说,有的时候我们往往两个想要匹配的图片并不完全是同样一个方向的,他可能在侧面或者说他的表现不一定完全一样,这种情况下面这个模型就很容易失败。这也是为什么很多传统的图像识别的方法的效果并不是特别好,而到了深度学习的兴起以后,整个领域才变得这个突飞猛进起来,因为它使用场景是有局限性的。
下面我们聊一下关于深度学习的图像处理,什么是深度学习?

4
图像处理的爆发——深度学习
下面我们聊一下关于深度学习的图像处理,什么是深度学习?
其实所谓深度学习就是深度神经网络,我们首先了解一下神经网络到底是怎么回事。

神经网络本身并不是一个全新的技术,它大概在三四十年前就存在了。我们人脑是是由一个神经网络来形成的,我们的各种神经元激凸通过之间的互相的传导信息,让我们人可以去理解这个世界。那大家就在说我们有没有可能去模拟这个过程,就有人发明了这个神经网络。
图上左右边其实都是非常简单的神经网络,左边是一个两层的神经网,这里大家注意一下,就是一般我们说神经网络时候是不算输入层的,这里一个是两层的神经网络,右边那个是个三层的那最开始的一层,我们一般叫Input Layer输入层,我们可以直接拿到结果的一般叫做Output Layer,就是输出层。除了输入和输出场的都叫Hidden Layer隐藏层。
那是不是神经网络就是一个全新的东西?其实并不是的。如果大家熟悉逻辑回归和支撑向量积的话可以试着匹配一下,会发现其实逻辑回归和支撑向量是非常特殊例子上的单层的神经网络。
神经网络其实有的时候并没有那么玄幻,它很多时候也是一步步随着我们类去了解,去使用机器理解一些事物的过程中间慢慢的进化出来。

刚才我们看到的这个神经网络是非常简单的,那实际应用中间我们如果想要去做一个人脸匹配,比如像人脸门禁,我们需要的网络是更复杂的,比如像上图这样。
它的input layer首先可能就有很多层,因为为了提取不同的图片里面的特征,hidden layer整个的计算层又分很多层,可能不同的层中间还有不同的目的。有的时候识别病人特征,有的时候是去识别一些特殊的特征。整个output layer也可能分很多层,因为他要进行一些数据拟合,然后分类结果的合成这样一些东西。

其实神经网络并不仅仅有刚才我们就是看到的那些类型,,并不完全是一个金字塔型的。其实很多网络的形式是有多样性的。比如像上图这个。它就是很多不同神经网络一个综合的图,包括感知器,应该是最原始的神经网络样子。其实我们还会有一些像梯形的神经网络,然后网状的神经网络,矩形神经网络,这些都有属于他们自己的名字,他们都能解决一些特定的问题。
传统机器学习方法是去理解我应该用什么样的一个模型去解决问题,要什么样的一个算法,是用支撑向量机还是用逻辑,大家想的是这个问题。
到了深度学习时代科学家们想的问题是我应该要用什么网络去解决问题,比如我选择了一种网络中介,我应该怎么去细化这个网络结构,每一层应该怎么去设计,我的那个激活因子应该选哪一个,是利用这种方式。其实思维模式是产生了变换,所以从传统机器学习的人去转换成一个学深度学习,有的时候他能够重新利用的信息知识并没有很多,所以深度学习往往是一个新的开始。

深度学习去做图像类的应用。它常用的一个网络叫做卷积神经网络。那为什么叫卷积神经网络?为什么要使用卷积?
大家如果有一定数学基础的话,可能会了解。我们使用卷机去对一个图片进行处理,其实是想要对这个图片中的信息得到一个全方位的一个了解。就比如我想要去识别图片上的一条狗,那他有可能在这个图片的任何一个位置以任何一个大小任何一个角度来呈现。所以我想尽量多的去图片上抓到可能的信息,那我就会采用卷积这种方式。
一般一个经典的这个卷积神经网络图是什么样的?就是上图这样的。
首先会有卷积层,整个图片的所有的信息获取是来源于这个卷积层的(Convolution layer)。第二步我们会在学习过程中间要尽量的去减少数据量,因为如果我们把图片整个Convolution layer出来的数据从头带到尾,不去做任何的降维的话,这个数据量是海量的,可能我们的机器根本就无法承载。而往往这个其中的很多信息在后续的学习中并没有这么重要。那怎么办?
我们就会采用一个叫池化层(Pooling Layer),在这过程中对我们一些矩阵进行采样,只使用其中的一些关键信息,或者把一些并不关键的信息给合并成一个比较关键的信息,把它作为特征值再进行下一步传递。这样的话呢就大大降低了我们整体的运算量,也让神经网络变得比较可行。
最后为了输出结果,我们一般还会有一个叫全连接层(Full Connection Layer)。全连接层就是把之前所有层的信息进行全部的连接,然后产生一个结果。有点相当于我们在做逻辑回归时的那个softmax。它其实是一个历史遗留产物,是从经典机器学习中间牵引过来的。所以现在也有很多人在挑战这一点,说我们为什么需要一个全连接层。往往在一个网络中间,全连接层可能会占整个网络中间80%的神经元的量。 它一大部分网络是在生成一个结果。很多人就会在这说我们为什么要这么做?我们能不能不要这个权力阶层,这样可以把这个网络变得简单很多。就会有人开始把全连接层的工作慢慢的分散在不同的层,分别去做。不是一次性的把所有层进行连接,而在过程中间逐层的去做连接,去降维,去产生一定的中间结果。这也是现在很流行的一个趋势。上图是一个很经典的一个CNN的图,但已经不是我们现在使用的图的样子。

在CNN之后非常聪明的科学家们就发现了很多可以更加优化的点,所以CNN其实只是整个深度学习做图像识别的一个起点,终点是应该远远还没有到。
CNN之后,大家想到了就是R-CNN,加入了Region Proposal Network(RPN)。大家可以这么理解,如果单纯的用神经网络去识别图片上的一些信息的话,它的起点其实是非常宽泛的,是以整个图片作为单位的。如果我们能加一个局部的一个层,我们就可以把一些根本不需要目标的区域给排除掉,可以提前缩小这个范围。 只让这个模型在这个我们确定一定会有something happen的地方去进行扫描,这样的话再做后续的处理,就大大的降低了整个神经网络的运算量,也让速度变得很快。
RCNN之后也出现了很多其他的网络,包括SPPNET,还有刚刚图上的Faster-RCNN。这些都是我们在一步步地优化网络,不断的往里面加一些东西。主要是为了两个目的,一个是降低网络的复杂度,提高运算速度,第二就是提升结果,提高这个模型算法的适应性。其实从CNN到Faster-RCNN都是同样一种解决问题的思维方式,叫Detection对象识别的方式。Faster-RCNN出现以后,有一个非常天才的人想到,也是他发明的CNN和Faster-RCNN的科学家。他就想到我们是不是一定要用对象识别的方式去解决这个问题,我们有没有可能回归到最初用分类的方式Classification去解决问题,比如对象检测这种问题。
最后呢他就想到了一种新的算法叫YOLO。这就有趣了,我们当时把这些问题分类,把分割分类,对象识别问题都拆分开,是希望可以让算法更好的为我们服务,让某一类型的算法模型解决一个类型的问题达到更好的效果。但随着技术的发展,硬件资源的提升,我们可能发现之前走不通的路变成了可能。也许大自然的规律就是如此,一切都是循环往复。
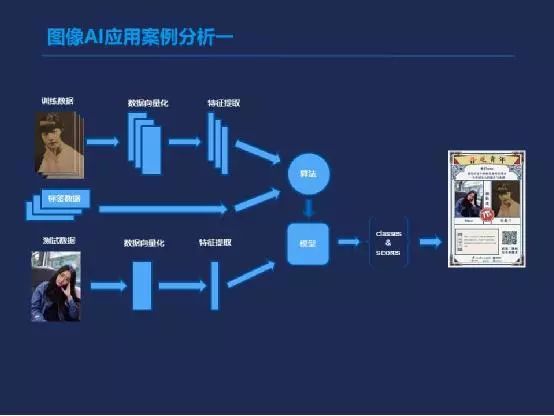
接下来谈一下在有了一个模型算法以后,应该如何做应用。
讲几个腾讯云这边支持过的AI应用的例子。首先是五四青年的活动,它是图像匹配应用的一个活动例子。那这个整个的流程大概是怎么进行的?首先我们会有一些标签好的数据,就是一些民国的人物图,包括他们的一些名称。然后我们会把这些东西送我们的模型去训练,机器会对图片本身进行一个相当于数据项量化的一个提取,把图片转换成数据向量,再用我们刚才的一些特征提取的方式把其中的特征提取出来。然后和标签匹配在一起以后,就会用我们的算法训练产生一个模型。用户在用的时候,比如小程序,可以上传我们的照片,我们的模型就会从我们的照片里面提取特征值,然后和本来预存的这些已经训练好的数据进行各种匹配。最后返回的结果一般是这种词典形式的,会有一个分类的ID加上一个置信度分数。
这个分数我们一般称之为置信度,但它其实并不是直接能代表它的准确度。假设我们返回来的数据是0.8,它是一类。然后0.7是二类这样。并不是说它们加起来总和是一,有80%可能性它是第一类的。这个只是代表我们对他比较确信,所以一般我们会返回确信度最高的那个分类作为它的主分类,然后前端上面就会去搜索这个分类上的照片,把它显示给大家,这就是整个这个应用的流程。

第二个应用也比较流行:人脸融合的一个应用。类似军装照这类,但它使用的方式和思维模式是截然不同的。
首先我们会有一个模板图,还会有大家上传的照片图。前一半是处理我们用户上传的照片,后一半做我们两个照片的融合。大家上传完照片以后,我们的模型会对人脸的关键点进行一个定位,但往往大家上传的照片的这个角度或者图片并不是正中的,有可能左30度角右30度角。这种情况我们会对图片进行一定程度的旋转,让它达到居中。下一步我们会把人脸非常完整的抠出来,再和我们的模板图进行一个匹配。而这个匹配只是初步的匹配,它只是看起来好像是两个东西合成一个了,但实际上图片的边缘,包括色差光影都并不完美。
很多的工作其实是在最后一步——图片校正。在这个领域要把两个图片要调成同样色调,光线也要重新调整,其他的一些细节我们都会去做一些调整。
经过这一系列完整的过程,我们就可以拥有一个非常完美的人脸融合的照片。

另外一个应用是我之前提到的一些照片,比如给出一个图片,最后摘取了一段文字的。
图上这个是我之前在斯坦福的时候做的一个项目,就是给出一个图片以后,我们会根据这个图片讲一段故事,这个可以帮助一些像有抑郁症的孩子,或是一些老人。我们可以传个图片,然后我们的story teller就会生成一段故事。而且这个故事是非常符合情景的,能够反映图片上的信息的。这就是一个多模态应用的一个例子。
整个这个项目中间基本上都是无监督学习。这里跟大家聊一下监督有监督学习无监督学习。
比如我们人脸匹配的这些应用,其实它都是一个有监督学习,我们模型在生成的时候都是有已经标注好的数据去生成的这个模型。
像这个应用的话,除了我们的文字库训练的时候用的是一个有监督的,其他比如图片的理解什么都是无监督的,所以它的适用场景是非常广泛的。而通过我们调整输入文本的不同的类型,比如我们的文本库,从浪漫小说改成科幻小说,那我们的文本生成器生成的文本就会从浪漫范变成了一个科幻范,它的灵活性弹性是非常强的。

这后面有几个例子,像刚才两张照片,一个是在在海边散步的,还有公园的。底下的文字都是非常完美的反映了图上的情景,还有写诗一样的意境在。

那如果大家想要去做一些研究,去了解最新的计算机视觉,或者是其他的整个机器学习人工智能领域一些东西,我应该去哪里去看?除了看公众号以外,有没有一些更专业的地方?
那这里跟大家推荐一个很好的论文库,叫Arxiv。这个论文库跟我们平常的这些论坛期刊有什么不同呢?Arxiv上面所有的论文都是最新的。这个论文库之所以存在,其实是因为很多的科学家他们在研究出来一个东西以后,由于期刊发表或者会议发表的审稿周期的很长。他们研究的东西还没有让全世界人知道之前,就有人也在同样的时候差不多时间也研究出来了,早他们一步发表。这样的话他们一下子从全世界第一个发现第一个做好的人变成了一个追随者。
所以康奈尔大学就支持了这个project,这是一个让大家可以第一时间不经过复杂的审稿机制,就可以发表自己论文的地方,就是这个Arxiv数据库。所有人都可以访问,没有密码也不需要钱。而且大家不用担心上面的论文的质量,都是非常高的。在上面发表论文的很多科学家都是世界最顶级的科学家,他们把所有论文都丢进去就是希望让全世界人知道我是第一个把这东西做出来的。

我最近读到一篇非常有意思关于无人驾驶的论文。我们知道全世界范围内,做无人驾驶的公司一般有两种流派,一种是用激光雷达,还有一种呢是坚信不用激光雷达,单纯的用机器视觉的方式,我们就可以实现这个目的。因为激光雷达成本还是比较高的,所以但很多车厂在使用激光雷达的时候还是非常的谨慎。一旦装了激光雷达车的价格就会很高,那销量就很难提高上去,所获得数据量也会受到影响。
特斯拉是非常坚定支持不用激光雷达的,它也是世界上目前生产有L3或者以上潜力的无人驾驶能力汽车最多的一个公司。他当时不使用激光雷达,原因就是马斯克是坚定地觉得不使用激光雷达的机器识别的算法也是实现的。目前看来是有可能的,我们要使用激光雷达是想要实现一个什么目的?是希望得到整个汽车运行场景的一个鸟瞰图。比如从上往下看,我们周围的对象在什么位置?它的大小是怎么样?激光雷达由于它本身的扫描特性和在车顶的这个高度,它是可以得到一个多维度的一个场景的绘制图。
而如果是一张单纯的照片,就像我们摄像头车上摄像头拍的照片,它只是一个二维的图,本质上来说是得不到距离的信息的和东西相对之间距离的。
那有没有方法可以帮助我们从一个二维图中获得三维地址信息呢?这篇论文就非常有意思地阐述了一个算法,就是去模拟人眼去理解二维图的方式。比如我们人去看个二维图的时候,其实我们能够把它想象成一个三维图的。 我们会根据一个图片的景深和他们物体之间的形变,在脑子中间会对这个图片上的对象进行三维建模。虽然我们看的是二维的,但在我们脑中它其实形成了一个三维的形象,这个算法就是模拟。
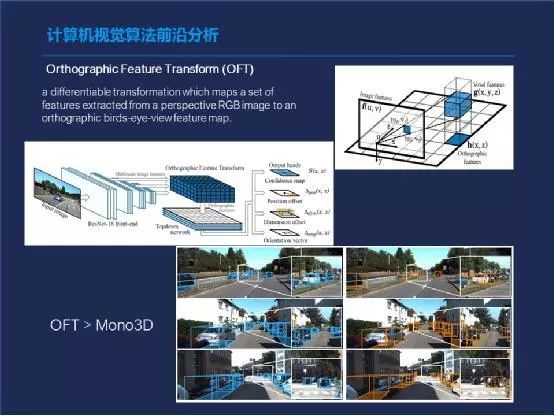
它其中的关键点是一个叫正交变换。就是他会拿了一张图以后,利用几何学的一些方式,从中去提取特性,然后把两个相邻的对象之间的距离关系和位置关系给模拟出来。
上面这几张图相当于是其中一些过程,大概的意思就是说先提取所有东西之间相对位置的一些信息,然后利用这个位置信息倒推出,它如果在三维图上的位置应该是怎么样的?其中分分了大概四个步骤,这种方式目前的效果是超过了业界使用2D图模拟3D图的算法叫Mono3D。
这个OFT的方法目前的性能是全面的已经超过Mono3D,我觉得这个算法的应用可能会为用2D摄像头的无人驾驶汽车公司技术实现一个小飞跃。
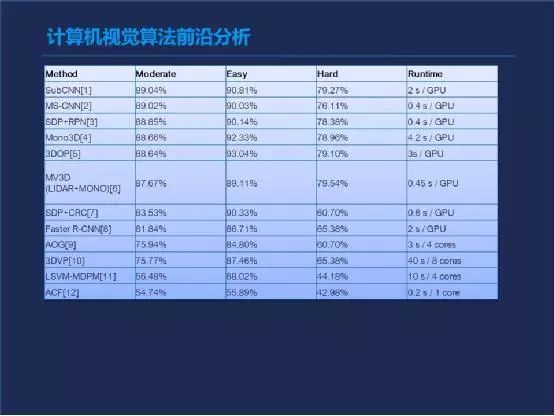
上图是一个比较图,不包括刚才我提到的OFT的算法。是目前所有2D实现3D模拟图的算法的性能,但目前为止,OFT超越了这里面所有的算法。
5
解析云端AI能力支撑

刚才我们聊了很多的这种机器学习图像方面的一些算法,包括传统的和深度的。那如果我们想要拥有或者自己可以搭建一个机器视觉的应用,不管是小程序,还是网站什么的,我们需要什么?

只有算法模型是远远不够的。像我们刚才聊到的朋友圈爆款产品的背后,其实是由我们整个的云网络在支撑的。我们使用了很多云上的一些组件和一些技术服务去支撑我们整个活动。包括我们使用SCD去做DNS的分发,ERB去做负载均衡。包括虚拟机去支撑我们的使用量,还有GPU,去快速的跑我们的模型。 我们所有的数据会存在cos的对象存储里,所有的虚拟集群都是自动可伸缩的。这就是我们整个云上去实现一个应用的背后的例子。
实际上大家看到的很多的应用只是在水面上的冰山的那个一角,但能够让我们很流畅的去使用应用,更多的是因为在背后我们看不到的部分。其实我们做了很多的工作,包括跨地域的负载均衡,因为除了考虑到全国各地的用户之外还要考虑海外的用户。同时我们做了动态的扩容,还有各种防雪崩的机制。在我们的服务热点期过了以后,我们会逐次的降级,把一些不用的机器给释放掉,这也可以是降低成本。
这就是我们支撑一个爆款应用上线和下线的整个过程背后的机制。

再来介绍一下我们腾讯云的人工智能产品的矩阵。我们大概分几个不同的领域,包括像人脸(计算机视觉)。这个里面包括人脸和声,身份证识别,还有各种基于场景的,比如智能门禁物流。语音领域,我们也有ASR(语音-文字)和TTS(文字-语音)的能力。底层我们会有积极学习的平台,还有大数据的平台去支撑。基础建设就包括我们刚才提到的CPU、GPU,还有FPGA的各种服务器,还有我们裸金属的这个黑石的服务器。所以大家如果在开公司创业时候,想要去很快的搭建底层的这些技术能力,使用它们去做你的APP,其实使用云服务是最快,也是目前最流行的方式。

我们目前计算机视觉的产品呢大概分四类,其中包括云智的慧眼,它是实名认证的身份核验的产品。神图是关于多场景的人脸的识别,比如考勤签到,还有我们支付用的人脸支付。明视是OCR的结构化,它包括我们的身份证识别,银行卡识别名片识别这些。魔镜主要是内容审核,比如识别各种视频图片的鉴黄鉴恐鉴暴等敏感信息。这就是我们产品的一个举证。

介绍一下几个例子,比如大家平时会用到人脸付款,或者去一些政府部门去签到等等都会用到。

图上这是1比N的一个人脸检测。这个场馆领域,可以去寻找走失人口,或是运用在一些公安体系上。这个就类似在海量人中间去匹配少量的人,即1:N的人脸算法模型。目前的场景使用也非常多。

OCR我就不细说了,像快递单这些,我们大家每天都会用到,基本上是已经离不开了。

除此之外我们还有一个私有化的视频管理平台,叫云智平台(TIMatrix)。它是针对各种智能楼宇园区的一个产品。它可以帮助一个主题公园,一个厂区或者一个公司快速地搭建起一整套的视频监控体系。我们背后也有各种的A.I.引擎去做大数据的分析,客户画像热力图等等非常适合to B的一些场景。
6
技能进阶建议

然后聊完我们今天这些话题以后,可能有些小伙伴会问如果我想要做一些东西,但目前好像会的并不是很多的话,我应该怎么样去学习?这里会给出一些小建议小tips

我们可以把AI领域分成几层。首先是算法,这大家都知道,我们要怎么样写模型,怎么样去选择不同的神经网络,怎么样去用传统机器学习方法,怎么样去做Feature Design,怎么样去把这个模型给搞出来,这是算法研究方向。
其实这个并不是完整的A.I.的版图的样子,只是有算法离落地AI场景其实还有非常远的距离。有了算法以后我们还需要什么?我们需要有工程实践,就要把一个算法可以真的变成一个能用的东西,不管是一个服务是个微服务,还是一个SARS软件还是一个客户端软件。我们需要有这个转换的过程,但工程实践其实非常的吃人力,它需要的人力其实是比算法更多的。
然后再上一层就是我做出了一个东西之后,那怎么去定义它,怎么做市场推广,怎么做产品定义。我把这一步叫做AI产品开发及应用,这也是另外一层。
其实大家如果想要进入AI领域,并不完全只能靠搞算法这条路,从工程实践和产品开发及应用的领域,大家一样是有这个潜力和机会可以进入AI这个领域的。
针对不同领域的人的话,我的建议是首先是,如果大家想搞AI算法的话,需要打好数学基础,积累算法的理论知识是必不可少的。同时还要锻炼自己对新学术的一些成果的快速理解和吸收的能力。不管是论文期刊,还是刚刚提到的论文库。都需要有快速的读论文,理解论文,把算法简单地从模型给实现出来的这个能力。
如果是想从工程实践方向着手,就需要锻炼逻辑算法封装的能力。比如别人给了你预算,怎么样能快速很好的把它部署成一个服务,而且可以承载海量的访问量和吞吐量。同时还要比较好的模型训练和优化的能力,这个都是可以从工程实践角度去着手提高自己的部分。
从产品角度话,如果想做一个AI的产品经理,更多时候是要提高对AI产品场景和应用的理解,去提升自己对复杂系统的构建和和理解能力。 由于人工智能的产品和场景和传统的产品和场景是不太一样的。我们理解的维度和角度其实是有很大的区别的。很多时候,传统的产品经理想要进入领域,需要对自己的很多固有观念进行一个更新,甚至是完全推翻重来。
举个简单的例子来说,比如当时国际巨头在想要进入AI领域去做智能交互,他们都从不同的角度进行切入。像苹果当时做了siri智能助手,谷歌则是做了Google Assistant嵌入到了一个当时美国很流行的温度的控制器上面。微软是从操作系统着手,把??加入到了Windows操作系统里面,但事实证明这些都并不是很成功。最成功的是亚马逊,它做了一款智能音箱,也是目前全世界第一款智能音箱,叫Amazon Echo。从此开启了AI到底如何跟人交互的答案。其实这么多全球巨头在寻找一个场景的时候,花了多少时间,走了多少弯路,所以很多时候对一个AI产品的定义是可以直接决定他的这个产品的最终的结局和生死的。
所以如果大家想往AI产品方面去发展转,这里面的空间也非常大,有很多的资料可以去学习,有很多的场景可以去考虑,有很多国家的公司的一些竞品可以去研究。,我觉得这都是非常有意思的。

如果从技术角度入门的话,可以参考右边这张图。这个是比较常见的机计算机视觉的各种库,包括open cv,大家只要接触过一段时间都会用到的。中间一层是各种机器学习的框架,包括谷歌,Tensorflow,亚马逊支持的MX net,Facebook目前的是Caffe。底层就是各种的不同的进一步的数学库。
关于课程的话,计算机视觉领域我有几门比较推荐的课程。首先CS131,231A,231N。这几个都是斯坦福机器学习实验室一系列的课程。这个课程的老师是李飞飞教授,他的这些课程是非常系统的,如果从头到尾大家去学一遍的话,会对计算机视觉整个领域有一个清楚的脉络的认识,非常好。
而且很多的课程它是在网上是开源的,都可以免费可以看到,可能有些作业什么的不一定开源,但是基本上大家想搜都是可以拿到。其他还有一些网站,我觉得是非常好的资源汇总的地方。它把很多不同的资源放到了一个像维基百科一样的地方,大家可以快速的去找。
推荐PPT上的这几本书给喜欢读书的小伙伴们:
Computer Vision: Algorithms and Application
Computer Vision: Models, Learning, and Inference
Multiple View Geometry in Computer Vision
前两本书其实不是一个系列的,只是名字有点像是两个不同人写的,第一个相对来说比较系统,第二个会比较深入一些。第三本书书是从另外一个维度,更多的牵涉到一些数学的知识。大家有兴趣的话都可以借来看一看。
Q&A环节
Q:有人问激光雷达在识别技术上跟计算机视觉技术上有没有什么区别,哪个技术在应用上能够更准确一些?
A:首先激光雷达LiDAR在识别技术上跟计算机视觉是有很大区别的。激光雷达由于雷达的特性,它很容易把整个周围场景的3D图给建模出来,这部分对算法的要求并没有那么高,整个雷达技术已经是很成熟的。利用这种激光雷达,可以快速地把周围的场景3D的建模出来。但是如果我们想用一个2D的图片从中去获得3D的信息,这个就得纯靠算法。这里面的难度和整个的工作量就会很大。从目前的情况上来看,激光雷达更准确。毕竟它的造价很高,而且它可以直接达到识别的目的。我们用2D建3D模的方式,很多时候是一个曲线救国,是一个间接的方法。激光雷达是一个直接的方法,所以目前来说激光雷达是更好的。但我觉得最终2D的方法也会慢慢的接近激光雷达效果。
Q: 嘉宾能不能为我们简单分析一下,计算机视觉技术,未来的市场会是什么样子的?
A: 从我的理解上来看,首先计算机视觉应用目前是属于逐渐成熟的阶段。大家可能会了解到,所有的技术从萌芽到最后被广泛使用,都会经历一个Hyperloop曲线。计算机视觉已经到了趋向于成熟的阶段,它会慢慢涉及到我们生活的各个方面。基本上人脑可以通过我们的视觉去理解的东西,计算机视觉慢慢都可以代替,这个的潜力是非常大的。而且它的颠覆已经开始了,所以我觉得未来在5到10年之内,它能够颠覆的领域会非常多的,很有潜力。
Q: 除了刚刚说的一些独立的应用场景,然后我们知道腾讯有一些通用印刷体识别和通用手写体识别,因为像这种关于手写体的识别的话,它具体是怎么样进行对它进行识别的?
A: 其实本质上这种识别类的应用都是类似的。首先我们会输入很多海量不同的手写体文字。比如我们想要识别数字一的时候,我们训练集中会全世界不同的人用各种方式,各种笔写的数字一。然后等我们模型训练好以后,我们就会进行各种Classification去匹配,去分类。
由于我们有海量的数据,加上我们模型会有很强的适应性,所以大家基本上不管怎么写我们都是可以识别出来这个文字的。
Q:腾讯有图片标签识别的功能,那有没有场景识别功能,呢比如说像火灾检测,看看工人有没有安戴安全帽之类的场景,有没有这一块相关的业务是这样的?
A:我们腾讯云提供了很多最核心的基础能力,包括图片的标签识别这样的一个能力。.那这个能力在具体的场景中间可以使用的方式是非常多的。这里提到的火灾检测,是一个非常细分的场景,安全帽这个对象也是很特殊的一个对象。从技术上来说我们都是可以实现的。更多的时候是说从商业上来看客户的需求量有多大,训练集及是否充沛,这些问题解决的话,原理上来说都是可以实现的。
干货下载:添加微信好友“5834434”(必须备注“机器视觉:学校/公司+研究方向”,否则无法通过验证),合作交流或获取机器视觉教程,行业报告等资源,持续更新中。。。
热门文章推荐
回复下面数字或直接点击,获取相关文章:
001:计算机视觉领域研究资源及期刊、会议介绍
002:德国kuka机器人与世界冠军乒乓对决
003:120图勾勒全球AI产业完整图谱!
004:Facebook 开源计算机视觉系统,从像素水平理解图像(附论文及代码)
005:想成为机器学习工程师?这份自学指南你值得收藏
006:十一种通用滤波算法
007:图像处理与计算机视觉基础,经典以及最近发展
008:机器人行业深度报告(完整版)
009:从洗衣妹到谷歌首席科学家,她靠孤独改变了人工智能界!
010:工业级机器视觉行业研究报告
011:双远心工业镜头的原理简述
012:如何装备一个学术型的 iPad ?
013:机器视觉系统概述
014:德国工匠:我们没有“物美价廉”的东西
015:为什么最好的机械臂是7个自由度,而不是6个?
016:史上最给力的技术视频!
017:机器人10大流行编程语言对比,你掌握了哪种?
018:新奇复杂机械原理图!
019:机器人控制系统相关知识大汇集020:机器人的工作原理,史上最详细的解析!
021:光源选型知识点022:这才是机械手,这才是自动化,你那算什么?023:摄像机和镜头的基础知识024:物联网产业链全景图(附另13大电子行业全景图,必收藏)025:日本到底强大到什么地步?让人窒息!看后一夜未眠026:德国机械用行动惊艳全世界:无敌是多么寂寞
-
AI
+关注
关注
87文章
30664浏览量
268827 -
计算机视觉
+关注
关注
8文章
1698浏览量
45965
原文标题:腾讯AI技术专家教你从0到1学习计算机视觉技术
文章出处:【微信号:www_51qudong_com,微信公众号:机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器视觉与计算机视觉的关系简述
让机器“看见”—计算机视觉入门及实战 第二期基础技术篇

计算机视觉的发展历史_计算机视觉的应用方向
计算机视觉入门指南
计算机视觉中的九种深度学习技术






 工商网监
工商网监
评论