 Hinton等人新研究告诉你:标签平滑技术到底怎么用!
Hinton等人新研究告诉你:标签平滑技术到底怎么用!

【导读】损失函数对神经网络的训练有显著影响,也有很多学者人一直在探讨并寻找可以和损失函数一样使模型效果更好的函数。后来,Szegedy 等学者提出了标签平滑方法,该方法通过计算数据集中 hard target 的加权平均以及平均分布来计算交叉熵,有效提升了模型的准确率。近日,Hinton 团队等人在新研究论文《When Does Label Smoothing Help?》中,就尝试对标签平滑技术对神经网络的影响进行分析,并对相关网络的特性进行了描述。
在开始今天的论文解读之前,我们先快速了解研究中的主角和相关知识的概念:
什么是 soft target?计算方法是什么?
使用 soft target,多分类神经网络的泛化能力和学习速度往往能够得到大幅度提高。文本中使用的soft target 是通过计算hard target 的加权平均和标签的均匀分布得到的,而这一步骤称为标签平滑。
标签平滑技术有什么作用?
标签平滑技术能够有效防止模型过拟合,且在很多最新的模型中都得到了应用,比如图片分类、机器翻译和语音识别。
Hinton 的这个研究想说明什么问题?
本文通过实验证明,标签平滑不仅能够提升模型的泛化能力,还能够提升模型的修正能力,并进一步提高模型的集束搜索能力。但在本文的实验中还发现,如果在teacher model 中进行标签平滑,对student model 的知识蒸馏效果会出现下降。
研究中如何解释发现的现象?
为了对这一现象进行解释,本文对标签平滑对网络倒数第二层表示的影响进行了可视化,发现标签平滑使同一类训练实例表示倾向于聚合为紧密的分组。这导致了不同类的实例表示中相似性的信息丢失,但对模型的泛化能力和修正能力影响并不明显。

1、介绍
损失函数对神经网络的训练有显著影响。在 Rumelhart 等人提出使用平方损失函数进行反向传播的方法后,很多学者都提出,通过使用梯度下降方法最小化交叉熵,能获得更好的分类效果。但是学者对损失函数对讨论从未停止,人们认为仍有其他的函数能够代替交叉熵以取得更好的效果。随后,Szegedy等学者提出了标签平滑方法,该方法通过计算数据集中hard target 的加权平均以及平均分布来计算交叉熵,有效提升了模型的准确率。
标签平滑技术在图片分类、语音识别、机器翻译等多个领域的深度学习模型中都取得了很好的效果,如表1所示。在图片分类中,标签平滑最初被用于提升 ImageNet 数据集上Inception-v2 的效果,并在许多最新的研究中得到了应用。在语音识别中,一些学者通过标签平滑技术降低了 WDJ 数据集上的单词错误率。在机器翻译中,标签平滑帮助小幅度提升了 BLEU 分数。

表1 标签平滑技术在三种监督学习任务中的应用
尽管标签平滑技术已经得到了有效应用,但现有研究对其原理及应用场景的适用性讨论较少。
Hinton 等人的这篇论文就尝试对标签平滑技术对神经网络的影响进行分析,并对相关网络的特性进行了描述。本文贡献如下:
基于对网络倒数第二层激活情况的线性映射提出了一个全新的可视化方法;
阐释了标签平滑对模型修正的影响,并指出网络预测结果的可信度更多取决于模型的准确率;
展示了标签平滑对蒸馏的影响,并指出该影响会导致部分信息丢失。
1.1 预备知识
这一部分提供了标签平滑的数学描述。假设将神经网络的预测结果表示为倒数第二层的激活函数,公式如下:
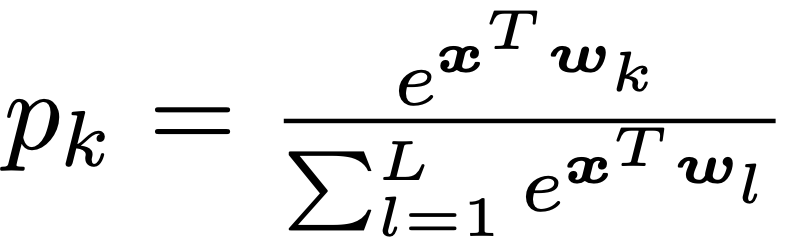
其中 pk 表示模型分类结果为第 k 类的可能性,wk 表示网络最末层的权重和偏置,x 是包括网络倒数第二层激活函数的向量。在使用hard target 对网络进行训练时,我们使用真实的标签 yk 和网络的输出 pk 最小化交叉熵,公式如下:
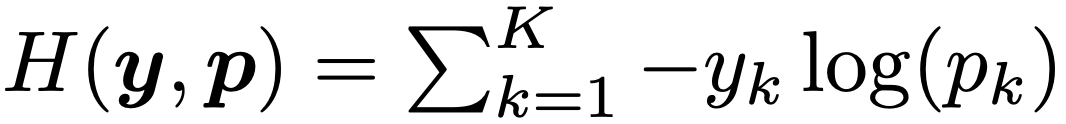
其中当分类为正确时, yk 值为1,否则为0。对于使用参数 a 进行标签平滑后的网络,则在训练时使用调整后的标签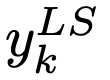 和网络的输出 pk 计算并最小化交叉熵,其中,
和网络的输出 pk 计算并最小化交叉熵,其中,
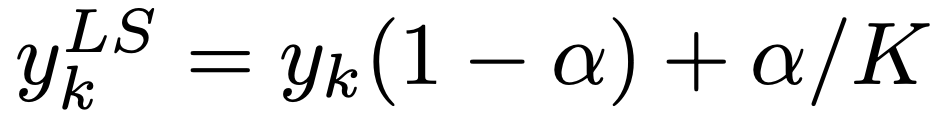
2、倒数第二层的表示
对于使用参数 a 对网络进行标签平滑后的神经网络,其正确和错误分类的 logit 值之间的差会增大,改变程度与 a 的值相关。在使用硬标签对网络进行训练时,正确分类的 logit 值会远大于错误分类,且不同错误分类的值之间差异也较大。一般而言,第 k 个类别的 logit 值可以看作网络倒数第二层的激活函数 x 和标准 wk 之间的欧式距离的平方,表示如下:
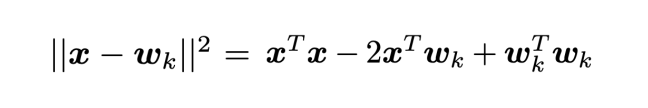
因此,标签平滑会使倒数第二层的激活函数与正确分类间的差值减小,并使其与正确和错误分类的距离等同。为了对标签平滑的这一属性进行观察,本文依照以下步骤提出了一个新的可视化方式:(1)选择三个类别;(2)找到这三个分类的一个标准正交平面,(3)把实例在倒数第二层的激活函数投射在该平面上。
图 1 展示了本文在 CIFAR-10, CIFAR-100 和 ImageNet 三个数据集上进行图片分类任务时,网络倒数第二层的激活函数的情况,训练使用的网络架构包括 AlexNet, ResNet-56 和 Inception-v4 。其中,前两列的模型未进行标签平滑处理,后两列使用了标签平滑技术。表2展示了标签平滑对模型准确率的影响。
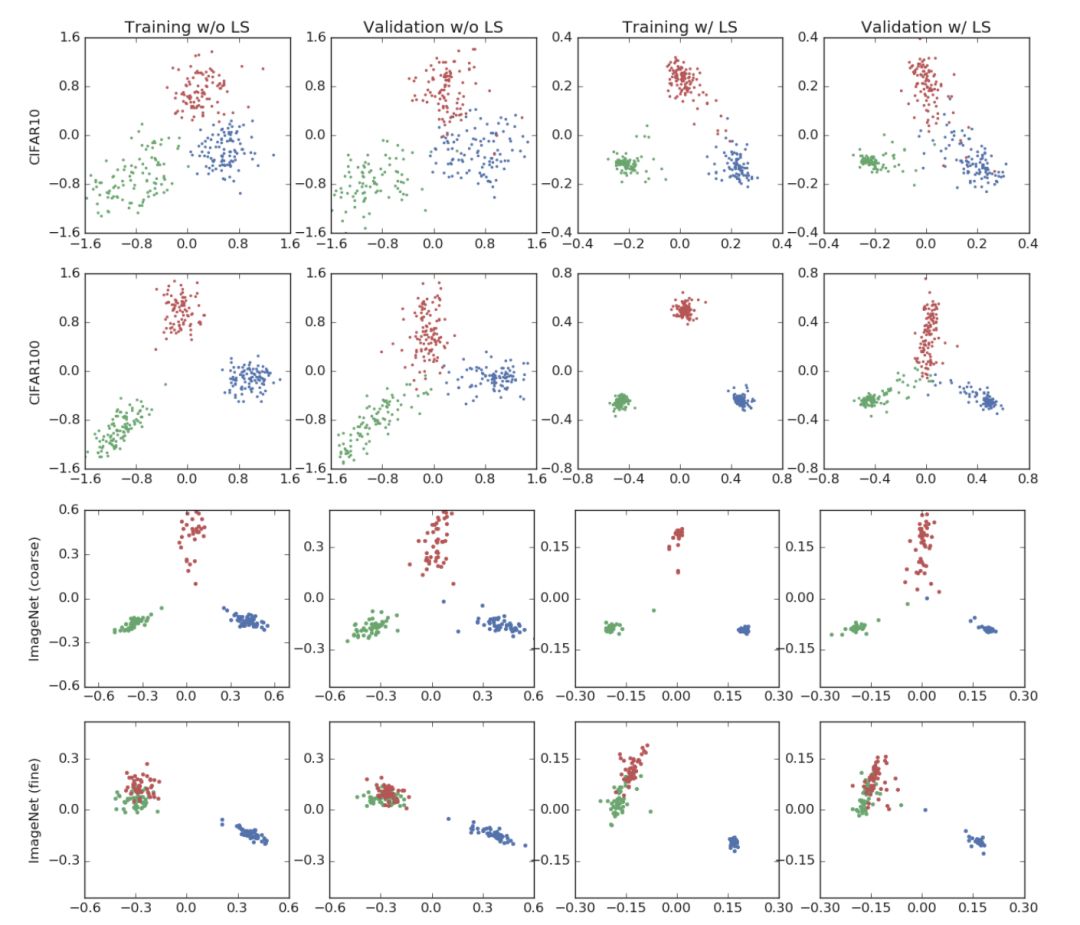
图 1 图片分类任务可视化情况

表2 使用和未使用标签平滑技术的模型的最高准确率
第一行可视化使用的数据集为 CIFAR-10 ,标签平滑的参数值为 0.1 ,三个图片分类分别为“airplane”,“automobil”和“bird”。这些模型的准确率基本相同。可以发现,在使用标签平滑的网络中,聚类更加紧凑。
第二行可视化使用的数据集为 CIFAR-100,模型为 ResNet-56 ,选择的图片分类为“beaver”,“dolphin”,“otter”。在这次实验中,使用标签平滑技术的网络获得了更高的准确率。
最后,本文使用 Inception-v4 在 ImageNet 数据集上进行了实验,并使用具有和不具有语义相似性的分类分别进行了实验。其中,第三行使用的分类不具有语义相似性,分别为“tench”,“meerkat”和“cleaver”。第四行使用了的两个具有语义相似性的分类“toy poodle”和‘miniature poodle“以及另一个不同的分类“tench, in blue”。对于语义相似的类别而言,即使是在训练集上都很难进行区分,但标签平滑较好地解决了这一问题。
从上述实验结果可以发现,标签平滑技术对模型表示的影响与网络结构、数据集和准确率无关。
3、隐式模型修正
标签平滑能够有效防止模型过拟合。在本部分,论文尝试探讨该技术是否能通过提升模型预测的准确性改善模型修正能力。为衡量模型的修正能力,本文计算了预期修正误差(expected calibration error, ECE)。本文发现,标签平滑技术能够有效降低 ECE ,并可用于模型修正过程。
图片分类
图2左侧展示了 ResNet-56 在 CIFAR-100 数据集上训练后得到的一个可靠性图表,其中虚线表示理想的模型修正情况。可以发现,使用硬标签的模型出现了过拟合的情况。如果需要对模型进行调整,可以将 softmax 的 temperature 调至1.9,或者使用标签平滑技术进行调整。如图中绿线所示,当使用 a = 0.05 进行标签平滑处理时,能够得到相似的模型修正效果。这两种方法都能够有效降低 ECE 值。
本文在 ImageNet 上也进行了实验,如图2右侧所示。使用硬标签的模型仍然出现过拟合情况 ,ECE 高达0.071。通过使用温度缩放技术(T = 1.4),可将 ECE 降低至0.022, 如蓝线所示。当使用 a = 0.1 的标签平滑时,能够将 ECE 降低至0.035。
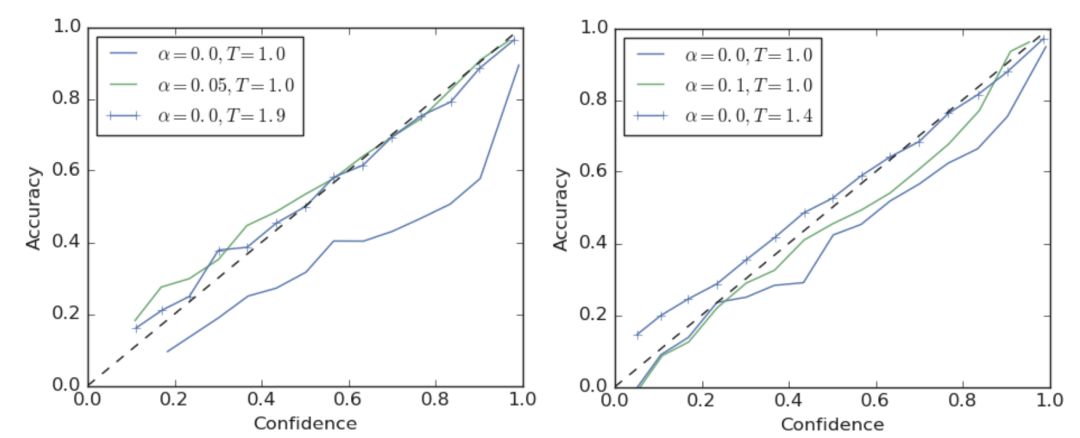
图2 可信度图表
机器翻译
本部分对使用 Transformer 架构的网络的调整进行了实验,使用的评测任务为英译徳。与图片分类任务不同,在机器翻译中,网络的输出会作为集束搜索算法的输入,这意味着模型的调整将对准确率产生影响。
本文首先比较了使用硬标签的模型和经过标签平滑(a = 0.1)的模型的可信度,如图3所示。可以发现,使用标签平滑的网络的调整情况优于使用硬标签的网络。
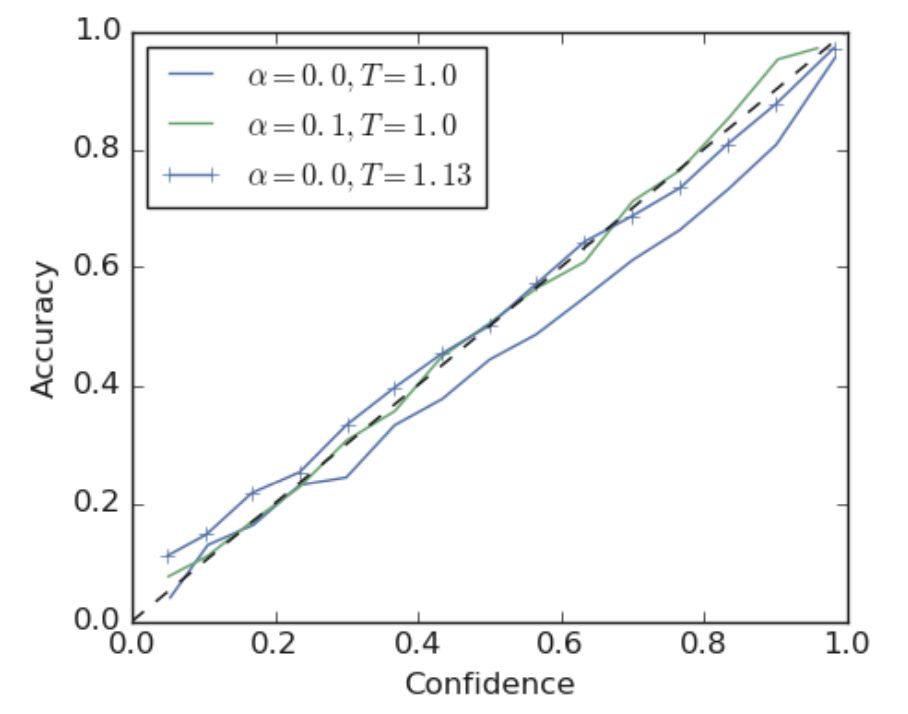
图3 基于英译徳任务训练的Transformer 架构的可信度图表
尽管标签平滑能够获得更佳的模型调优和更高的 BLEU 值,其也会导致负对数似然函数(negative log-likelihoods, NLL)的值变差。图4展示了标签平滑技术对 BLEU 和 NLL 的影响,蓝线代表 BLEU 值,红线代表 NLL 值。其中,最左侧的图为使用硬标签训练的模型的情况,中间的图为使用标签平滑技术训练的模型的情况,右侧的图则展示了两种模型的 NLL 值变化情况。可以发现,标签平滑在提高 BLEU 分数的同时,也导致了 NLL 的降低。
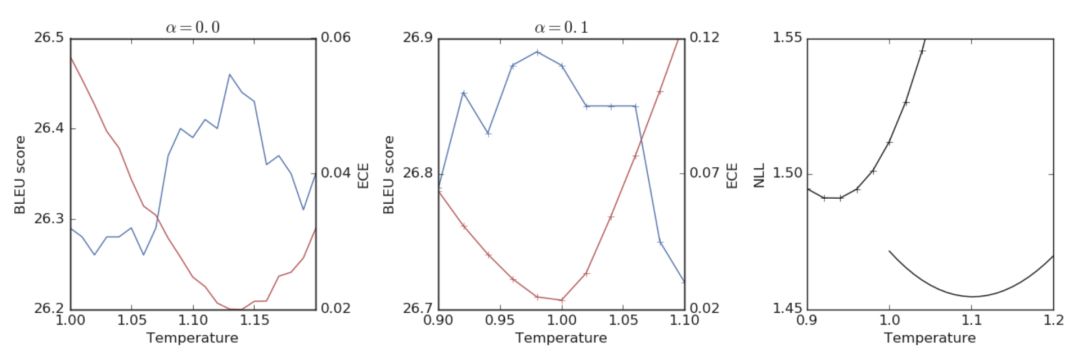
图4 Transformer 网络调优对 BLEU 和 NLL 的影响
4、知识蒸馏
本部分研究了在teacher model 对student model 的知识蒸馏中标签平滑的影响。本文发现,尽管标签平滑能够提升teacher model 的准确性,但使用标签平滑技术的teacher model 所产生的student model 相比于未使用标签平滑技术的网络效果较差。
本文在 CIFAR-10 数据集上进行了实验。作者训练了一个 ResNet-56 的teacher model ,并对于一个使用 AlexNet 结构的student model 进行了知识蒸馏。作者重点关注了4项内容:
teacher model的准确度
student model的基线准确度
经过知识蒸馏后student model的准确度,其中teacher model使用硬标签训练,且用于蒸馏的标签经过温度缩放进行调整
使用固定温度进行蒸馏后的student model的准确度,其中 T = 1.0 ,teacher model训练使用了标签平滑技术
图5展示了这一部分实验的结果。作者首先比较了未进行蒸馏的teacher model 和student model 的效果,在实验中,提高 a 的值能够提升teacher model 的准确度,但会轻微降低student model 的效果。
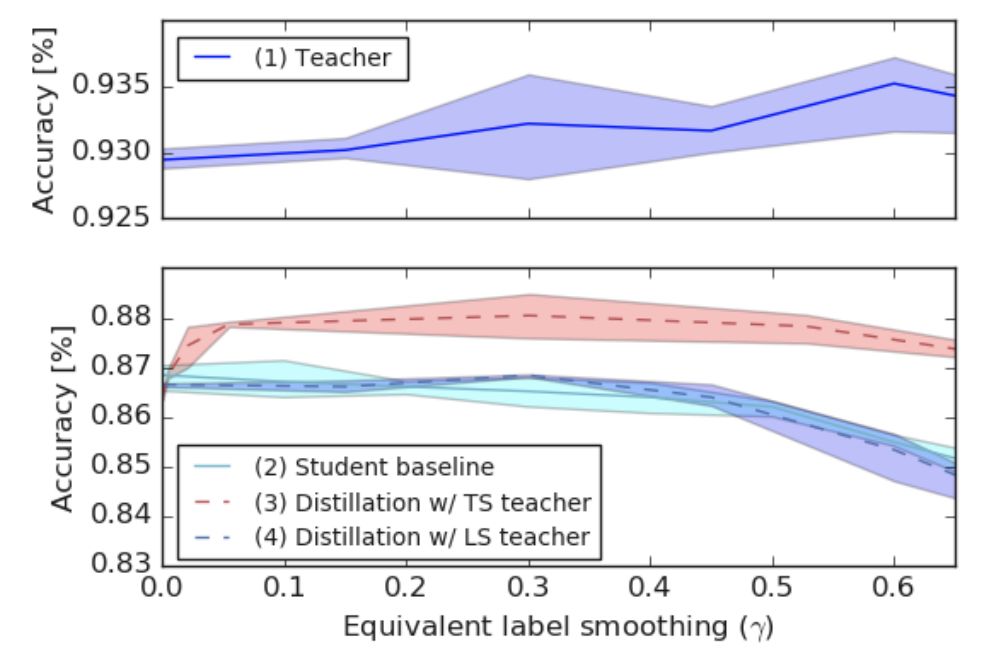
图5 基于 CIFAR-10 数据集从 ResNet-56 向 AlexNet 进行蒸馏的效果
之后,作者使用硬标签训练了teacher model 并基于不同温度进行蒸馏,且分别计算了不同温度下的 y 值,用红色虚线表示。实验发现,所有未使用标签平滑技术的模型效果都优于使用标签平滑技术的模型效果。最后,作者将使用标签平滑技术训练的具有更高准确度的teacher model 的知识蒸馏入student model ,并用蓝色虚线进行了表示。可以发现,模型效果并未得到显著提升,甚至有所降低。
5、结论和未来展望
尽管很多最新技术都使用了标签平滑方法,该方法的原理和使用情形并未得到充分讨论。本文总结了解释了在多个情形下标签平滑的应用和表现,包括标签平滑如何使得网络倒数第二层激活函数的表示的聚类更加紧密等。为对此问题进行探究,本文提出了一个全新的低纬度可视化方法。
标签平滑技术在提升模型效果的同时,也可能对知识蒸馏带来负面的影响。本文认为造成该影响对原因是,标签平滑导致了部分信息的丢失。这一现象可以通过计算模型输入和输出的互信息来进行观察。基于此,本文提出了一个新的研究方向,即标签平滑和信息瓶颈之间的关系。
最后,本文针对标签平滑对模型修正的作用进行了实验,提升了模型的可解释性。
-
神经网络
+关注
关注
42文章
4840浏览量
108141 -
数据集
+关注
关注
4文章
1240浏览量
26259 -
标签
+关注
关注
0文章
159浏览量
18669
原文标题:Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用?
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
用于光谱色散平滑技术的双通调制器实验研究
小编告诉你:嫁给电子男的N多好处!
资深物联网产品经理告诉你:如何不花冤枉钱,善用无线接入?
无源标签系统研究
STM32 3993读取标签无法操作是什么原因造成的?
GB29768的标签在库存时,提示无法读取标签怎么解决?
通用多协议标签交换技术研究

RFID标签天线制造技术研究

AI教父Geoff Hinton和深度学习的40年
交互设计到底是什么?这篇文章告诉你!



评论