 能生成Deepfake也能诊断癌症,GAN与恶的距离
能生成Deepfake也能诊断癌症,GAN与恶的距离
GAN可能是最近人工智能圈最为人熟知的技术之一。但是它的爆火不仅是由于这个技术出神入化的好用,还因为由他催生的相关应用导致了各种伦理道德问题。
最受关注的当然是Deepfake(深度伪造),这款操作容易且效果完美的换脸应用,让人们谈“GAN”色变。
而近期,Deepfake甚至有了升级版,走红网络的一键生成裸照软件DeepNude,只要输入一张完整的女性图片就可自动生成相应的裸照,由于广泛传播而造成了预料之外的后果,开发者最终将APP下架。
被一键脱衣的霉霉
相关技术引发了一系列社会后果,并且引发了政府立法部门的重视。2019年6月13日,美国众议院情报委员会召开关于人工智能深度伪造的听证会,公开谈论了深度伪造技术对国家、社会和个人的风险及防范和应对措施。
让人嗤之以鼻的同时,真正的研究者们也在用GAN推动人类社会的发展。据《MIT科技评论》报道,吕贝克大学研究人员近期刚刚利用deepfake背后同样的技术,合成了与真实影像无异的医学图像,解决了没有足够的训练数据的问题,而这些图像将可以用于训练AI通过X光影像发现不同的癌症。
那么,技术本身就存在原罪么?又是哪里出了错呢?
让我们回到GAN诞生的那天,从头回顾这一让人又爱又恨的技术发展的前世今生。
GAN的诞生故事:一场酒后的奇思妙想
时间拉回到2014年的一晚,Ian Goodfellow和一个刚刚毕业的博士生一起喝酒庆祝。在蒙特利尔一个酒吧,一些朋友希望他能帮忙看看手头上一个棘手的项目:计算机如何自己生成图片。
研究人员已经使用了神经网络(模拟人脑的神经元网络的一种算法),作为生成模型来创造合理的新数据。但结果往往不尽人意。计算机生成的人脸图像通常不是模糊不清,就是缺耳少鼻。
Ian Goodfellow朋友们提出的方案是对那些组成图片的元素进行复杂的统计分析以帮助机器自己生成图片。这需要进行大量的数据运算,Ian Goodfellow告诉他们这根本行不通。
边喝啤酒边思考问题时,他突然有了一个想法。如果让两个神经网络相互对抗会出现什么结果呢?他的朋友对此持怀疑态度。
当他回到家,他女朋友已经熟睡,他决定马上实验自己的想法。那天他一直写代码写到凌晨,然后进行测试。第一次运行就成功了!
那天晚上他提出的方法现在叫做GAN,即生成对抗网络(generative adversarial network)。
Goodfellow自己可能没想到这个领域会发展得如此迅速,GAN的应用会如此广泛。
下面我们先来看几张照片。
如果你没有亲眼看到我去过的地方,那就可以认为这些照片完全是假的。
当然,我并不是说这些都是ps的或者CGI编辑过的,无论Nvidia称他们的新技术是如何了得,那也只是图片,不是真实的世界。
也就是说,这些图像完全是用GPU计算层层叠加,并且通过烧钱生成的。
能够做出这些东西的算法就是对抗生成网络,对于那些刚开始学习机器学习的人而言,编写GAN是一个漫长的旅途。在过去的几年中,基于对抗生成网络应用的创新越来越多,甚至比Facebook上发生的隐私丑闻还多。
2014年以来GANs不断进行改进才有了如今的成就,但是要一项一项来回顾这个过程,就像是要重新看一遍长达八季的“权力的游戏”,非常漫长。所以,在此我将仅仅重温这些年来GAN研究中一些酷炫成果背后的关键思想。
我不准备详细解释转置卷积(transposed convolutions)和瓦瑟斯坦距离(Wasserstein distance)等概念。相反,我将提供一些我觉得比较好的资源链接,你可以使用这些资源快速了解这些概念,这样你就可以看到它们在算法中是如何使用的。
下文的阅读需要你掌握深度学习的基础知识,并且知道卷积神经网络的工作原理,否则读起来可能会有点难度。
鉴于此,先上一张GAN发展路线图:
GAN路线图
图中的过程我们将在下文一步一步地讲解。让我们先来看看内容大纲吧。
GAN:Generative Adversarial Networks
DCGAN:Deep Convolutional Generative Adversarial Network
CGAN:Conditional Generative Adversarial Network
CycleGAN
CoGAN:Coupled Generative Adversarial Networks
ProGAN:Progressive growing of Generative Adversarial Networks
WGAN:Wasserstein Generative Adversarial Networks
SAGAN:Self-Attention Generative Adversarial Networks
BigGAN:Big Generative Adversarial Networks
StyleGAN:Style-based Generative Adversarial Networks
GAN:Generative Adversarial Networks
看到这张图你首先想到的是什么,是不是觉得这像素也太低了,还看得人难受,尤其是对于密集恐惧症患者来说,这张图片看起来像是某个数学书呆子在excel表中放大了一张缩小的照片。
我们来看看这图片究竟是什么?
看完视频是不是发现除了Excel,其他都猜对了。
早在2014年,Ian Goodfellow提出了这个革命性的想法——让两个神经网络互相竞争(或合作,这是一个视角问题)。
感兴趣的同学可以查看Ian Goodfellow 提出GAN时的原文。
论文链接:
https://arxiv.org/abs/1406.2661
代码链接:
https://github.com/goodfeli/adversarial
作者相关论文链接:
https://arxiv.org/abs/1701.00160
一个神经网络试图生成真实数据(注意:GAN可用于给任何数据分布建模,但近来其主要用于图像),而另一个神经网络则试图判别真实数据和生成器网络生成的数据。
生成器网络使用判别器作为损失函数,并更新其参数以生成看起来更真实的数据。
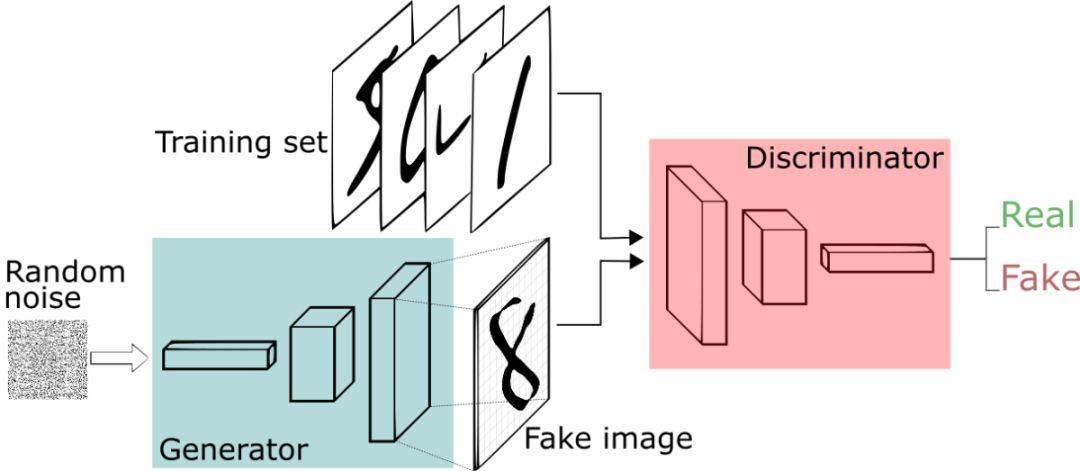
另一方面,判别器网络更新其参数以使其更好地从真实数据中鉴别出假数据,所以它这方面的工作会变得更好。
这就像猫和老鼠的游戏,持续进行,直到系统达到所谓的“平衡”,其中生成器能够生成看起来足够真实的数据,然后判别器则轻易就能正确判断真假。
到目前为止,如果顺利的话,你的代码无误,亚马逊也没有毙掉你的spot实例(顺便说一句,如果使用FloydHub就不会出现这个问题,因为他们提供了备用的GPU机器),那么你现在就留下了一个能从同样的数据分布中准确生成新数据的生成器,它生成的数据则可以成为你的训练集。
这只是非常简单的一种GAN。到此,你应该掌握GAN就是使用了两个神经网络——一个用于生成数据,一个是用来对假数据和真实数据进行判别。理论上,您可以同时训练它们,然后不断迭代,直至收敛,这样生成器就可以生成全新的,逼真的数据。
DCGAN:Deep Convolutional Generative Adversarial Network
论文:
https://arxiv.org/abs/1511.06434
代码:
https://github.com/floydhub/dcgan
其他文章:
https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
看原文是非常慢的,看本文将为您节省一些时间。
先来看几个公式:
卷积=擅长图片
GANs=擅长生成一些数据
由此推出:卷积+GANs=擅长生成图片
事后看来,正如Ian Goodfellow自己在与Lex Fridman的播客中指出的那样,将这个模型称为DCGAN(“深度卷积生成对抗网络”的缩写)似乎很愚蠢,因为现在几乎所有与深度学习和图像相关的内容都是深度的(deep)和卷积的(convolutional)。
此外,当大多数人了解到GANs时,都会先学习“深度学习和卷积”(deep and convolutional)。
然而,有一段时间GANs不一定会使用基于卷积的操作,而是依赖于标准的多层感知器架构。
DCGAN通过使用称为转置卷积运算(transposed convolution operation)来改变了这一现状,它还有个不太好听的名字——反卷积层( Deconvolution layer)。
转置卷积是一种提升运算,它帮助我们将低分辨率图像转换为更高分辨率的图像。
但是严格来说,如果您要掌握转置卷积原理,只看上文介绍不够,是需要深入研究链接里的资源,毕竟这是现代所有GAN架构的基础。
如果你没有足够多的的时间来看,我们可以通过一个总结得很好的动画来了解转置卷积是如何工作:
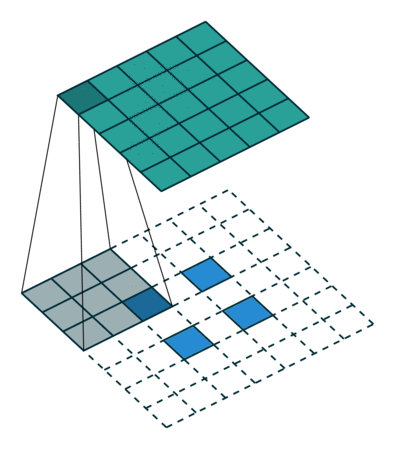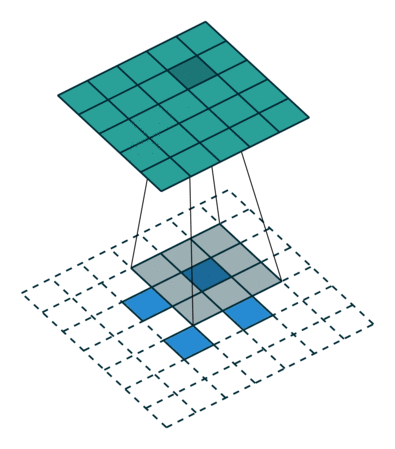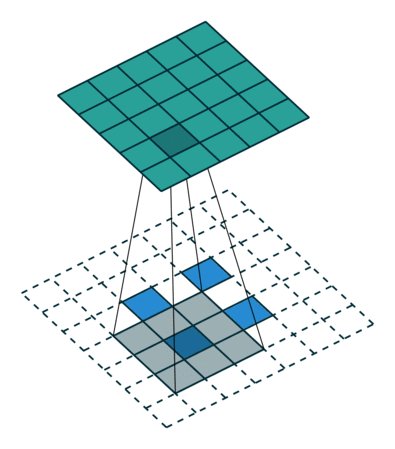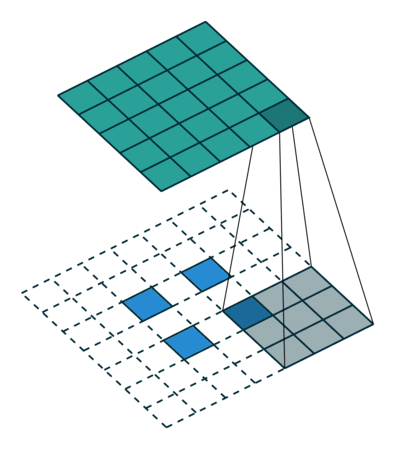
在一般的卷积神经网络中,你会用一系列卷积(以及其他操作)将图像映射到通常是较低维度的向量。
类似地,运用多个反卷积允许我们映射出单个低分辨率的阵列,并使之成为鲜明的全彩图像。
在我们继续之前,让我们尝试使用GAN的一些独特方法。
你现在的位置:红色的X
CGAN:Conditional Generative Adversarial Network
原始GAN根据随机噪声生成数据。这意味着你可以在此基础上训练它,比如狗的图像,它会产生更多的狗的图像。
您也可以在猫的图像上训练它,在这种情况下,它会生成猫的图像。
您也可以在尼古拉斯·凯奇(Nicholas Cage)图像上训练它,在这种情况下,它会生成尼古拉斯·凯奇(Nicholas Cage)图像。
你也可以在其他图像上训练它,以此类推。
但是,如果你试图同时训练狗和猫的图像,它会产生模糊的半品种。
CGAN旨在通过只告诉生成器生成一个特定物种的图像来解决这个问题,比如一只猫,一只狗或一个尼古拉斯·凯奇。
具体地来说,CGAN将单编码向量yy连接到随机噪声向量zz,产生如下所示的体系结构:
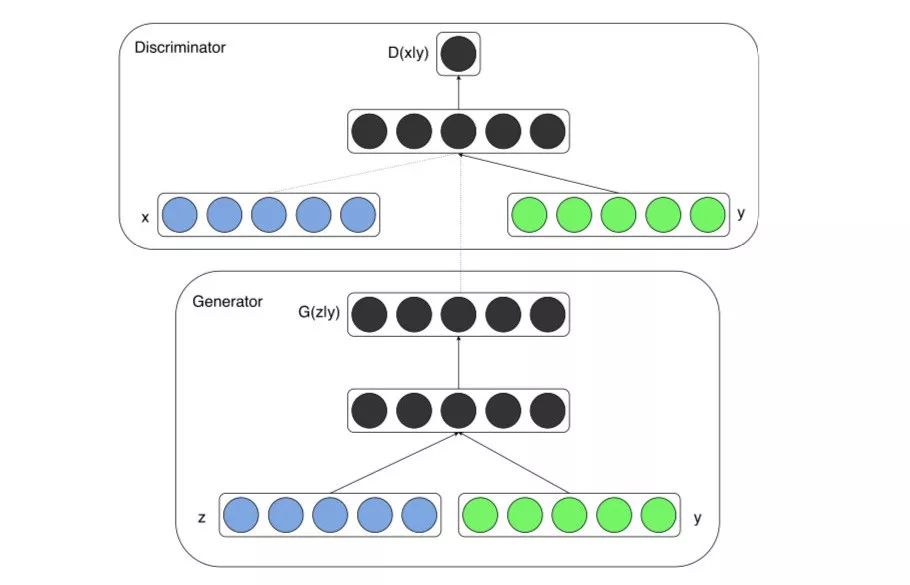
现在,我们可以用同一个GAN同时生成猫和狗。
CycleGAN
GANs并不仅仅用于生成图像。他们还可以创建“马+斑马”这样的新生物,如上图所示。
为了创建这些图像,CycleGAN旨在解决“图像到图像”转换的问题。
CycleGAN并不是一个推动艺术图像合成的新GAN架构,相反,它是使用了GAN的智能方式。因此,您可以自由地将此技术应用于您喜欢的任何架构。
此时,我会建议你阅读一篇论文(https://arxiv.org/abs/1703.10593v6)。写得非常好,即使是初学者也很容易理解。
CycleGAN的任务是训练一个网络G(X)G(X),该网络会将图像从源域XX映射到目标域YY。
但是,你可能会问:“这与常规的深度学习或样式迁移有什么不同。”
嗯,下面的图片很好地总结了这个问题。CycleGAN将不成对的图像进行图像平移。这意味着我们正在训练的图像不必代表相同的东西。

如果我们有大量的图像对:(图像,达芬奇的绘画图像)(图像,达芬奇绘画图像),那么训练达芬奇的绘画图像就会(相对)容易一些。
不幸的是,这个家伙并没有太多的画作。
然而,CycleGAN可以在未配对的数据上进行训练,所以我们不需要两个相同的图像。
另一方面,我们可以使用样式迁移。但这只会提取一个特定图像的风格并将其转移到另一个图像,这意味着我们无法转化一些假设性事物,如将马转化为斑马。
然而,CycleGAN会学习从一个图像域到另一个域的映射。所以我们就说一下所有的莫奈画作训练。

他们使用的方法非常优雅。CycleGAN由两个生成器GG和FF,以及两个判别器DXDX和DYDY组成。
GG从XX获取图像并尝试将其映射到YY中的某个图像。判别器 DYDY预测图像是由GG生成还是实际在YY中生成。
类似地,FF从YY接收图像并尝试将其映射到XX中的某个图像,而判别器DXDX 预测图像是由FF生成还是实际上是在XX中。
所有的这四个神经网络都是以通常的GAN方式进行训练,直到我们留下了强大的生成器GG和FF,它们可以很好地执行图像到图像的转换任务,乃至愚弄了DYDY 和DXDX。
这种类型的对抗性损失听起来是个好主意,但这还不够。为了进一步提高性能,CycleGAN使用另一个度量标准,循环一致性损失。
一般来说,优秀的转换应该具备以下属性,当你来回转换时,你应该再次得到同样的东西。
CycleGAN用巧妙的方式实现了这个想法,它迫使神经网络遵守这些约束:
F(G(x))≈x,x∈XF(G(x))≈x,x∈X G(F(y))≈y,y∈YG(F(y))≈y,y∈Y
在视觉上看,循环一致性如下所示:
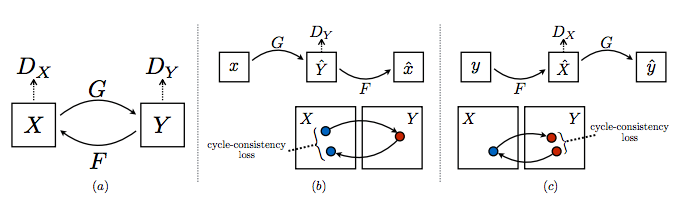
总损失函数是以惩罚网络不符合上述特性的方式构造的。我不打算在这里写出这个损失函数,因为这会破坏它在文章中汇总的方式。
好的,七龙珠还没有召唤完,让我们回到我们找寻更好的GAN架构的主要任务。
CoGAN:Coupled Generative Adversarial Networks
你知道比一个GAN更好的网络是什么吗?两个GAN!
CoGAN(即“Coupled Generative Adversarial Networks”,不要与CGAN混淆,后者代表的是条件生成对抗网络)就是这样做的。它会训练两个GAN而不是一个单一的GAN。
当然,GAN研究人员不停止地将此与那些警察和伪造者的博弈理论进行类比。所以这就是CoGAN背后的想法,用作者自己的话说就是:
在游戏中,有两个团队,每个团队有两个成员。生成模型组成一个团队,在两个不同的域中合作共同合成一对图像,用以混淆判别模型。判别模型试图将从各个域中的训练数据分布中绘制的图像与从各个生成模型中绘制的图像区分开。同一团队中,参与者之间的协作是根据权重分配约束建立的。
这样就有了一个GAN的多人局域网竞赛,听起来不错,但你怎么能让它真正起作用呢?
事实证明这并不复杂,只需使网络对某些层使用完全相同的权重。
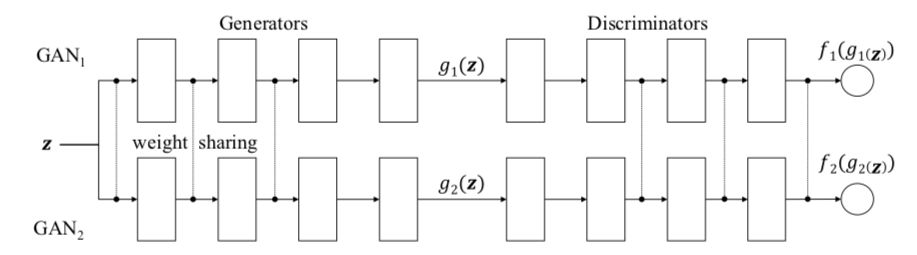
在我认为(可能不太谦虚),关于CoGAN最酷的事情不是提高图像生成质量,也不是你可以在多个图像域中进行训练的事实。
而是,事实上,你获得两张图片的价格仅是之前的四分之三。
由于我们共享一些权重,因此CoGAN将比两个单独的GAN具有更少的参数(因此将节省更多的内存,计算和存储)。
这是一种微妙技术,但是有点过时,所以我们今天看到的一些新GAN并不会使用这种技术。
不过,我认为这一想法会在未来再次得到重视。
ProGAN:Progressive growing of Generative Adversarial Networks
训练集GAN存在许多问题,其中最重要的是其不稳定性。
有时,GAN的损失会发生振荡,因为生成器和判别器会消除对方的学习。也有时,错误会在网络收敛后立即发生,这时图像就会看起来很糟糕。
ProGAN是一种通过逐步提高生成图像的分辨率来使其训练集稳定的技术。
常识认为,生成4x4的图像比生成1024x1024图像更容易。此外,将16x16的图像映射到32x32的图像比将2x2图像映射到32x32图像更容易。
因此,ProGAN首先训练4x4生成器和4x4判别器,并在训练过程的后期添加相对应的更高分辨率的层。我们用一个动画来总结一下:
WGAN:Wasserstein Generative Adversarial Networks
这篇文献可能是此列表中最具理论性和数学性的论文。作者在文中用了一卡车的证据、推论以及另一种数学术语。因此,如果积分概率计量和Lipschitz连续与你无关,我们也不会在这个上花太多时间。
简而言之,WGAN('W'代表Wasserstein)提出了一个新的成本函数,这些函数在纯数学家和统计学家中风靡一时。
这是GAN minimax函数的旧版本:
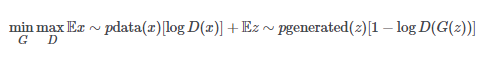
这是WGAN使用的新版本:
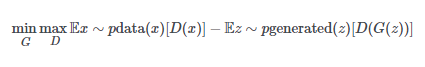
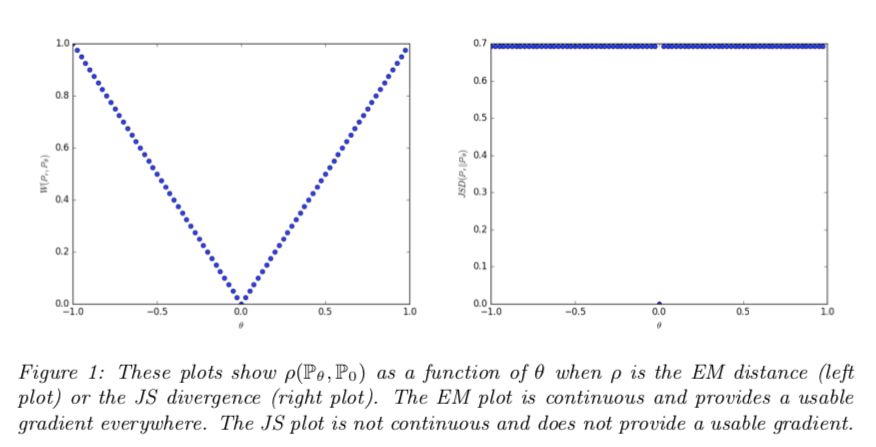
在大多数情况下,你需要知道WGAN函数是清除了旧的成本函数,该函数近似于称为Jensen-Shannon散度的统计量,并在新的成本函数中滑动,使其近似于称为1-Wasserstein距离的统计量。
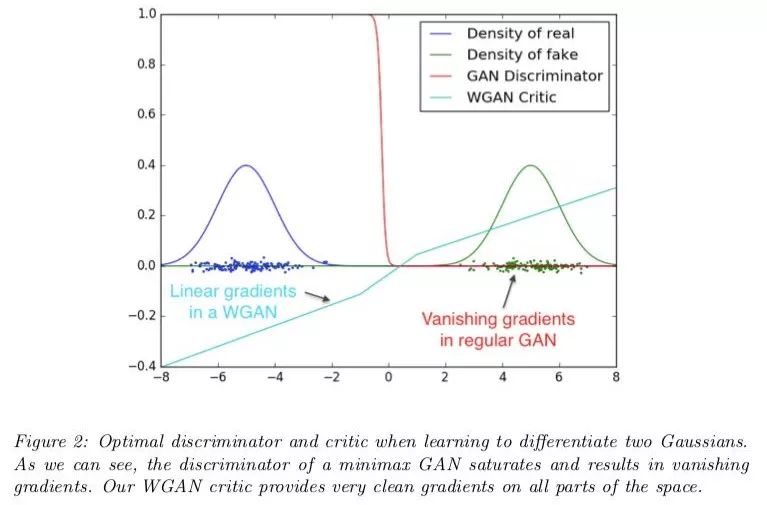
看了下图您就知道为什么要这么做。
当然,如果您感兴趣的话,接下来的是对数学细节的快速回顾,这也是WGAN论文备受好评的原因。
最初的GAN论文里认为,当判别器是最优的时,生成器以最小化Jensen-Shannon散度的方式更新。
如果你不太明白的话,Jensen-Shannon散度是一种衡量不同两种概率分布的方法。JSD越大,两个分布越“不同”,反之亦然。计算公式如下:
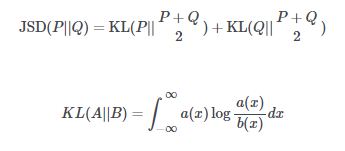
然而,把JSD最小化是最好的选择吗?
WGAN论文的作者认为可能不是。出于特殊原因,当两个发行版完全不重叠时,可以显示JSD的值保持为2log22log2的常量值。
具有常量值的函数有一个梯度等于零,而零梯度是不好的,因为这意味着生成器完全没有学习。
WGAN作者提出的备用距离度量是1-Wasserstein距离,也称为搬土距离(EMD距离)。
“搬土距离”来源于类比,想象一下,两个分布中的一个是一堆土,另一个是一个坑。
假设尽可能有效地运输淤泥,沙子,松土等物品,搬土距离测量将土堆运输到坑中的成本。这里,“成本”被认为是点之间的距离×土堆移动的距离×移动的土堆量。
也就是说(没有双关语),两个分布之间的EMD距离可以写成:
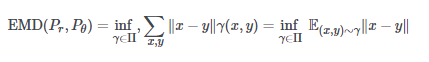
当inf是最小值时,xx和yy是两个分布上的点,γγ是最佳运输计划。
可是,计算这个是很难的。于是,我们计算完全不同的另一个值:
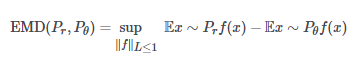
这两个方程式之间的联系一开始似乎并不明显,但通过一些称为Kantorovich-Rubenstein二重性的复杂数学(试着快读三次),可以证明这些Wasserstein / Earth mover距离的公式在试计算同样的东西。
如果你跟不上我提供的链接中的的论文和博客文章中的一些重要的数学概念,也不要过于担心。关于WGAN的大部分工作都是为一个简单的想法提供一个复杂的理由。
SAGAN:Self-Attention Generative Adversarial Networks
由于GAN使用转置卷积来“扫描”特征映射,因此它们只能访问附近的信息。
单独使用转置卷积就像绘制图片,只在画笔的小半径范围内查看画布区域。
即使是能完善最独特和复杂细节的最伟大的艺术家,在创作过程中也需要退后一步,看看大局。
SAGAN(全称为“自我关注生成对抗网络”)使用自我关注机制,由于迁移模型架构,近年来这种方式已经变得十分流行。
自我关注让生成器退后一步,查看“大局”。
BigGAN:Big Generative Adversarial Networks
经过四年漫长的岁月,DeepMind前所未有地决定与GAN合作,他们使用了一种深度学习的神秘技术,这种技术非常强大,是最先进的技术,超越了先进技术排行榜上所有其他的技术。
接下来展示BigGAN,GAN绝对没有做什么(但是运行了一堆TPU集群,却不知何故应该在这个列表中)。
开个玩笑!DeepMind团队确实在BigGAN上取得了很多成就。除了用逼真的图像吸睛之外,BigGAN还向我们展示了一些非常详细的训练GAN的大规模结果。
BigGAN背后的团队引入了各种技术来对抗在许多机器上大批量培训GAN的不稳定性。
首先,DeepMind使用SAGAN作为基线,并添加了一个称为谱归一化的功能。
接下来,他们将图片批量大小缩放50%,宽度(通道数)缩放20%。最初,增加层数似乎并没有帮助。
在进行了一些其他单位数百分比改进之后,作者使用“截断技巧”来提高采样图像的质量。
BigGAN在训练期间从z N(0,I)提取其潜在向量,如果潜在向量在生成图像时落在给定范围之外,则重新采样。
范围是超参数,由ψψ表示。较小的ψψ会缩小范围,从而以多样化为代价提高样本保真度。
那么所有这些错综复杂的调整工作会有什么后顾呢?好吧,有人称之为狗球。
BigGAN技术还发现更大规模的GAN训练可能会有一系列问题。
值得注意的是,训练集似乎可以通过增加批量大小和宽度等参数来很好地扩展,但不知什么原因,最终总会崩溃。
如果你对通过分析奇异值来理解这种不稳定性感兴趣的话,请查看论文,因为你会在那里找到很多东西。
最后,作者还在一个名为JFT-300的新数据集上训练BigGAN,这是一个类似ImageNet的数据集,它有3亿个图像。他们表明BigGAN在这个数据集上的表现更好,这表明更大规模的数据集可能是GAN的发展方向。
在论文的第一版发布后,作者在几个月后重新访问了BigGAN。还记得我怎么说增加层数不起作用?事实证明,这是由于糟糕的训练集选择导致的。
该团队不再只是在模型上填充更多层,还进行了实验,发现使用ResNet突破瓶颈是可行的。
通过以上不断地调整、缩放和仔细实验,BigGAN的顶级线条完全抹杀了先前的最新状态,得分高达52.52分,总分是152.8。
如果这不是正确步骤的话,那我不知道哪个是正确的。
StyleGAN:Style-based Generative Adversarial Networks
StyleGAN是Nvidia的一个延伸研究,它主要与传统的GAN研究关系不大,传统GAN主要关注损失函数,稳定性,体系结构等。
如果你想生成汽车的图像的话,仅仅拥有一个可以欺骗地球上大多数人的世界级人脸生成器是没有用的。
因此,StyleGAN不是专注于创建更逼真的图像,而通过提高GAN的能力,可以对生成的图像进行精细控制。
正如我所提到的那样,StyleGAN没有开发架构和计算损失函数功能。相反,它是一套可以与任何GAN联用的技术,允许您执行各种很酷的操作,例如混合图像,在多个级别上改变细节,以及执行更高级的样式传输。
换句话说,StyleGAN就像一个photoshop插件,只是大多数GAN开发都是photoshop的新版本。
为了实现这种级别的图像风格控制,StyleGAN采用了现有的一些技术,如自适应实例规范化,潜在矢量映射网络和常量学习输入。
如果没有深入细节,是很难再描述StyleGAN的,所以如果你有兴趣的话,请查看我的文章,其中展示了如何使用StyleGAN生成权力游戏角色。我对所有技术都有详细的解释,一路上有很多很酷的结果等你哦。
结论
恭喜你,坚持看到了最后!你们都跟上了创造虚假个人照片的高度学术领域的最新进展。
但是在你瘫在沙发上并开始无休止地刷微博票圈之前,请稍微停一下看看你到底还有多少路要走:
接下来是什么?!未被开发的区域!
在掌握了ProGAN和StyleGAN,且规模到达BigGAN之后,你很容易迷失在这里边。
但请放大地图仔细观察,看到那个绿色土地了吗?看到北方的红三角了吗?
这些都是等待被突破的未知开发区域,如果你放胆一试,他们都可以成为你的。
-
GaN
+关注
关注
19文章
1922浏览量
73068 -
DeepFake
+关注
关注
0文章
15浏览量
6664
原文标题:能生成Deepfake也能诊断癌症,GAN与恶的距离
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐




请问LM311能准确的交截生成对应的PWM波形吗?
EM储能网关 ZWS智慧储能云应用(3) — 收益接入介绍






 工商网监
工商网监
评论