 半小时学会PyTorch快速图片分类
半小时学会PyTorch快速图片分类
通过本教程,读者将能够在选择的任何图像数据集上,构建和训练图像识别器,同时充分了解底层模型架构和训练过程。教程内容包括数据提取、数据可视化、CNN、ResNets、迁移学习、结果解释、微调等。
这是一篇长文教程,建议大家读不完的话一定要收藏,利用闲暇时光将其读完!更加欢迎将本文转发给同学、朋友、同事等。
本文的目标是能够让你可以在任何图像数据集上构建和训练图像识别器,同时充分了解底层模型架构和培训过程。
目标读者:任何研究图像识别、或对此领域感兴趣的初学者
教程目录:
数据提取
数据可视化
模型训练
结果解释
模型层的冻结和解冻
微调
教程所使用的Jupyter notebook:
https://github.com/SalChem/Fastai-iNotes-iTutorials/blob/master/Image_Recognition_Basics.ipynb
更简单直接的方式是登录Google Colab:
https://colab.research.google.com/github/SalChem/Fastai-iNotes-iTutorials/blob/master/Image_Recognition_Basics.ipynb
注意:使用Google Colab之前,确保你做了如下设置
Runtime -> Change runtime type -> Hardware Accelerator -> GPU
设置IPython内核并初始化
加载依赖库

初始化

其中,bs 代表batch size,意为每次送入模型的训练图像的数量。每次batch迭代后都会更新模型参数。
比如我们有640个图像,那么bs=64;参数将在1 epoch的过程中更新10次。
如果你运行教程过程中提示内存不足,可以使用较小的bs,按照2的倍数增减即可。
使用特定值初始化上面的伪随机数生成器可使系统稳定,从而产生可重现的结果。
数据提取
数据集来自Oxford-IIIT Pet Dataset,可以使用fastai数据集对模块进行检索。

URLs.PETS 是数据集的url。这里提供了12个品种的猫和25个品种的狗。untar_data 解压并下载数据文件到 path。
PosixPath('/home/jupyter/.fastai/data/oxford-iiit-pet/images/scottish_terrier_119.jpg')
每个图像的标签都包含在图像文件名中,需要使用正则表达式提取。模式如下:

创建训练并验证数据集:

ImageDataBunch 根据路径 path_img 中的图像创建训练数据集 train_ds 和验证数据集 valid_ds。
from_name_re 使用在编译表达式模式 pat 后获得的正则表达式从文件名 fnames 列表中获取标签。
df_tfms 是即时应用于图像的转换。在这里,图像将调整为 224x224,居中,裁剪和缩放。
这种转换是数据增强的实例,不会更改图像内部的内容,但会更改其像素值以获得更好的模型概括。
normalize 使用ImageNet图像的标准偏差和平均值对数据进行标准化。
数据可视化
训练数据样本表示为
(Image (3, 224, 224), Category scottish_terrier)
Image里是RGB数值,Category 是图像标签。对应的图像如下:
len(data.train_ds)和len(data.valid_ds)分别输出训练样本5912和验证样本数量1478。
data.c和data.classes分别输出类及其标签的数量。下面的标签共有37个类别:
['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair', 'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue', 'Siamese', 'Sphynx', 'american_bulldog', 'american_pit_bull_terrier', 'basset_hound', 'beagle','boxer', 'chihuahua', 'english_cocker_spaniel', 'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese', 'japanese_chin', 'keeshond', 'leonberger', 'miniature_pinscher', 'newfoundland', 'pomeranian', 'pug', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu', 'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']

show_batch 显示一些batch里的图片。
模型训练

cnn_learner 使用来自给定架构的预训练模型构建CNN学习器、来自预训练模型的学习参数用于初始化模型,允许更快的收敛和高精度。我们使用的CNN架构是ResNet34。下图是一个典型的CNN架构。

ResNet34后面的数字可以随意更改,比如改成ResNet50。数字越大,GPU内存消耗越高。
让我们继续,现在可以在数据集上训练模型了!
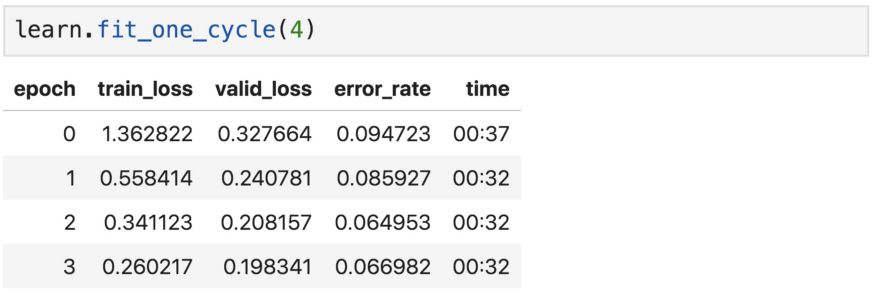
fit_one_cycle会按预设epoch数训练模型,比如4个epoch。
epoch数表示模型查看整个图像集的次数。但是,在每个epoch中,随着数据的增加,同一张图像都会与上个epoch略有不同。
通常,度量误差将随着epoch的增加而下降。只要验证集的精度不断提高,增加epoch数量就是个好办法。然而,epoch过多可能导致模型学习了特定的图像,而不是一般的类,要避免这种情况出现。
刚才提到的训练就是我们所说的“特征提取”,所以只对模型的头部(最底下的几层)的参数进行了更新。接下来将尝试对全部层的参数进行微调。
恭喜!模型已成功训练,可以识别猫和狗了。识别准确率大约是93.5%。
还能进步吗?这要等到微调之后了。
我们保存当前的模型参数,以便重新加载时使用。

对预测结果的解释
现在我们看看如何正确解释当前的模型结果。

ClassificationInterpretation提供错误分类图像的可视化实现。

plot_top_losses显示最高损失的图像及其:预测标签/实际标签/损失/实际图像类别的概率
高损失意味着对错误答案出现的高信度。绘制最高损失是可视化和解释分类结果的好方法。
具有最高损失的错误分类图像
分类混淆矩阵

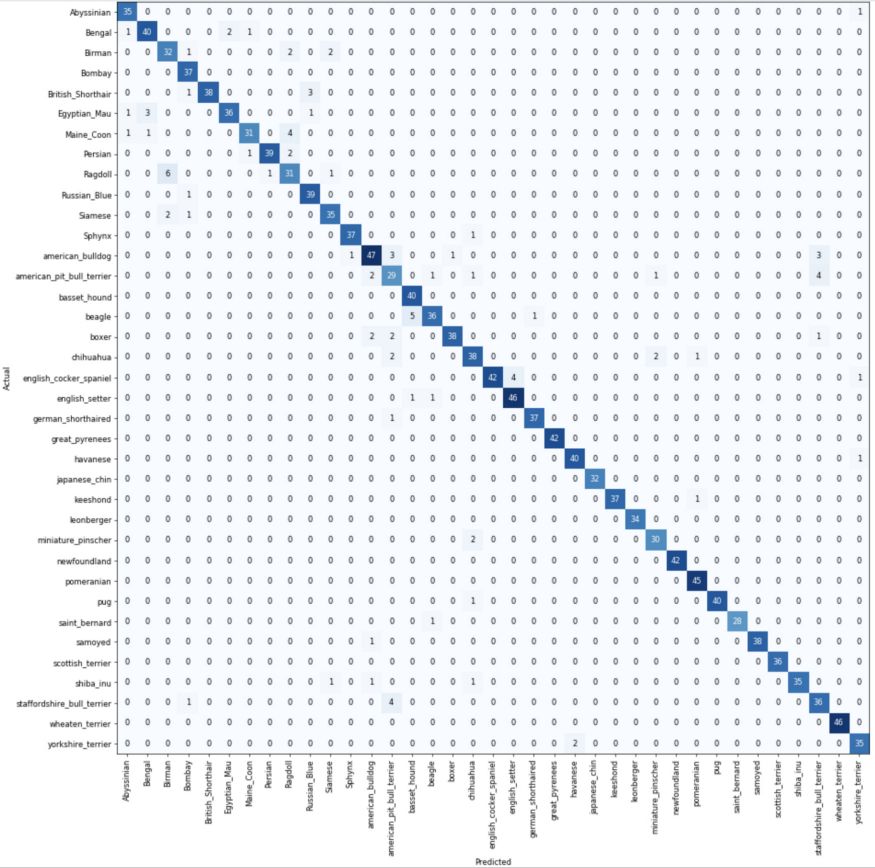
在混淆矩阵中,对角线元素表示预测标签与真实标签相同的图像的数量,而非对角线元素是由分类器错误标记的元素。

most_confused只突出显示预测分类和实际类别中最混乱的组合,换句话说,就是分类最常出错的那些组合。从图中可以看到,模型经常将斯塔福郡斗牛犬错误分类为美国斗牛犬,它们实际上看起来非常像。
[('Siamese', 'Birman', 6), ('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5), ('staffordshire_bull_terrier', 'american_pit_bull_terrier', 5), ('Maine_Coon', 'Ragdoll', 4), ('beagle', 'basset_hound', 4), ('chihuahua', 'miniature_pinscher', 3), ('staffordshire_bull_terrier', 'american_bulldog', 3), ('Birman', 'Ragdoll', 2), ('British_Shorthair', 'Russian_Blue', 2), ('Egyptian_Mau', 'Abyssinian', 2), ('Ragdoll', 'Birman', 2), ('american_bulldog', 'staffordshire_bull_terrier', 2), ('boxer', 'american_pit_bull_terrier', 2), ('chihuahua', 'shiba_inu', 2), ('miniature_pinscher', 'american_pit_bull_terrier', 2), ('yorkshire_terrier', 'havanese', 2)]
对网络层的冻结和解冻
在默认情况下,在fastai中,使用预训练的模型对较早期的层进行冻结,使网络只能更改最后一层的参数,如上所述。冻结第一层,仅训练较深的网络层可以显著降低计算量。
我们总是可以调用unfreeze函数来训练所有网络层,然后再使用fit或fit_one_cycle。这就是所谓的“微调”,这是在调整整个网络的参数。
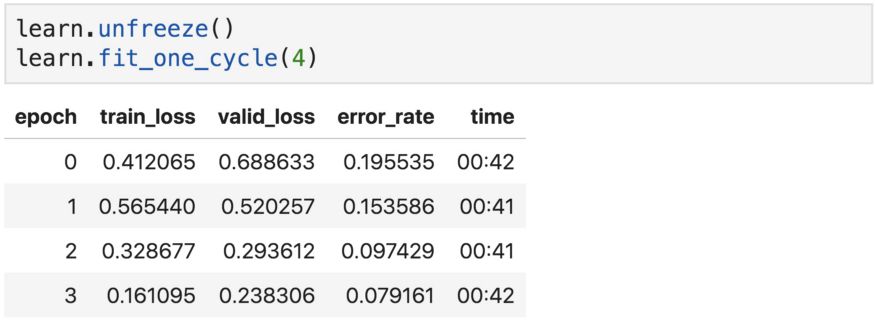
现在的准确度比以前略差。这是为什么?
这是因为我们以相同的速度更新了所有层的参数,这不是我们想要的,因为第一层不需要像最后一层那样需要做太多变动。控制权重更新量的超参数称为“学习率”,也叫步长。它可以根据损失的梯度调整权重,目的是减少损失。例如,在最常见的梯度下降优化器中,权重和学习率之间的关系如下:
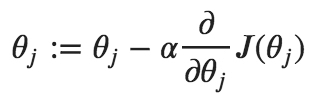
顺便说一下,梯度只是一个向量,它是导数在多变量领域的推广。
因此,对模型进行微调的更好方法是对较低层和较高层使用不同的学习率,通常称为差异或判别学习率。
本教程中可以互换使用参数和权重。更准确地说,参数是权重和偏差。但请注意,超参数和参数不一样,超参数无法在训练中进行估计。
对预测模型的微调
为了找到最适合微调模型的学习率,我们使用学习速率查找器,可以逐渐增大学习速率,并且在每个batch之后记录相应的损失。在fastai库通过lr_find来实现。
首先加载之前保存的模型,并运行lr_find

recorder.plot可用于绘制损失与学习率的关系图。当损失开始发散时,停止运行。
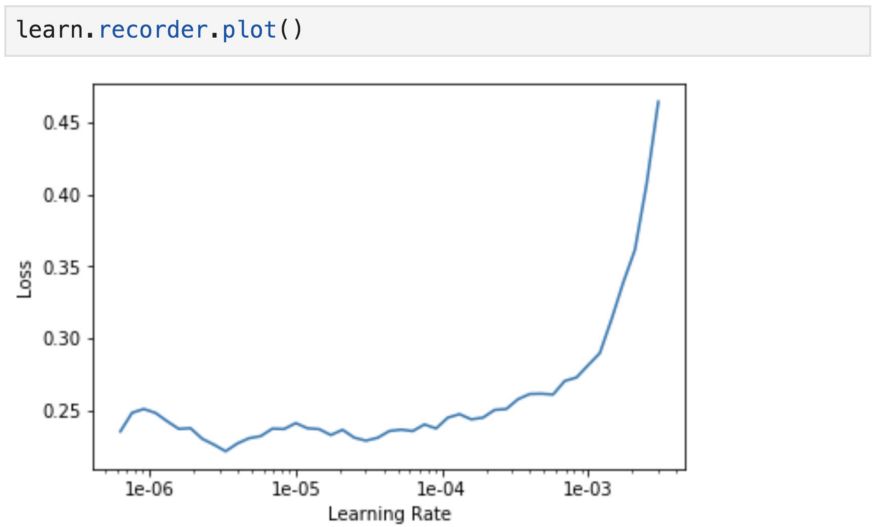
从得到的图中,我们一致认为适当的学习率约为1e-4或更小,超过这个范围,损失就开始增大并失去控制。我们将最后一层的学习速率设为1e-4,更早期的层设为1e-6。同样,这是因为早期的层已经训练得很好了,用来捕获通用特征,不需要那么频繁的更新。
我们之前的实验中使用的学习率为0.003,这是该库的默认设置。
在我们使用这些判别性学习率训练我们的模型之前,让我们揭开fit_one_cycle和fitmethods之间的差异,因为两者都是训练模型的合理选择。这个讨论对于理解训练过程非常有价值,但可以直接跳到结果。
fit_one_cycle vs fit:
简而言之,二者之间不同之处在于fit_one_cycle实现了Leslie Smith 循环策略,而没有使用固定或逐步降低的学习率来更新网络的参数,而是在两个合理的较低和较高学习速率范围之间振荡。
训练中的学习率超参数
在微调深度神经网络时,良好的学习率超参数是至关重要的。使用较高的学习率可以让网络更快地学习,但是学习率太高可能使模型无法收敛。另一方面,学习率太小会使训练速度过于缓慢。
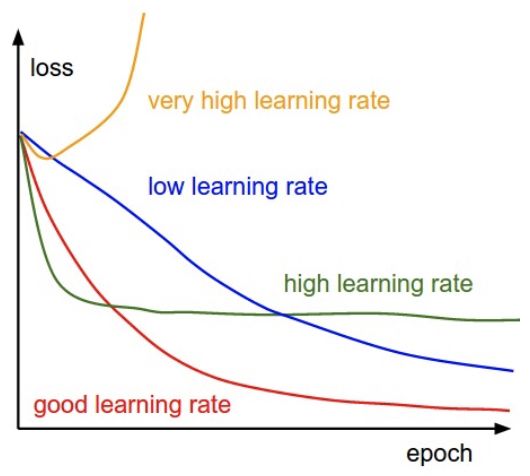
不同水平的学习率对模型收敛性的影响
在本文的实例中,我们通过查看不同学习率下记录的损失,估算出合适的学习率。在更新网络参数时,可以将此学习率作为固定学习率。换句话说,就是对所有训练迭代使用相同的学习率,可以使用learn.fit来实现。一种更好的方法是,随着训练的进行逐步改变学习率。有两种方法可以实现,即学习率规划(设定基于时间的衰减,逐步衰减,指数衰减等),以及自适应学习速率法(Adagrad,RMSprop,Adam等)。
简单的1cycle策略
1cycle策略是一种学习率调度器,让学习率在合理的最小和最大边界之间振荡。制定这两个边界有什么价值呢?上限是我们从学习速率查找器获得的,而最小界限可以小到上限的十分之一。这种方法的优点是可以克服局部最小值和鞍点,这些点是平坦表面上的点,通常梯度很小。事实证明,1cycle策略比其他调度或自适应学习方法更快、更准确。Fastai在fit_one_cycle中实现了cycle策略,在内部调用固定学习率方法和OneCycleScheduler回调。

1cycle的一个周期长度
下图显示了超收敛方法如何在Cifar-10的迭代次数更少的情况下达到比典型(分段常数)训练方式更高的精度,两者都使用56层残余网络架构。
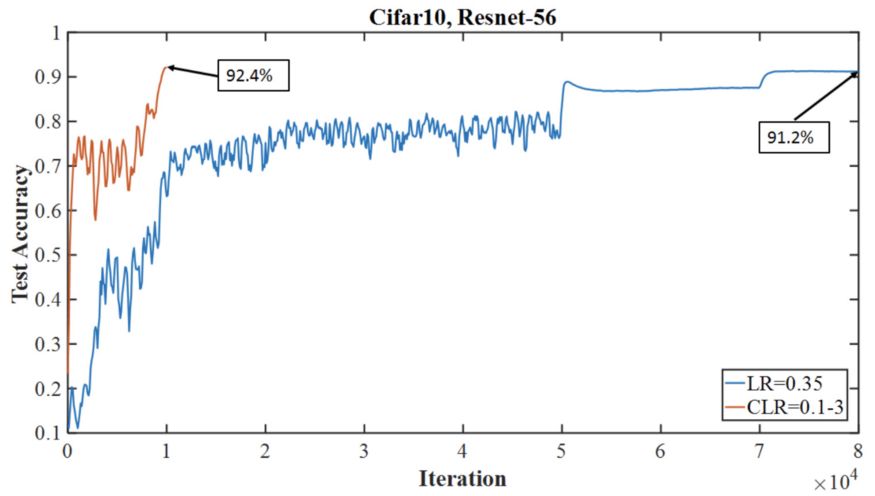
超收敛精度测试与Cifar-10上具有相同架构模型的典型训练机制
揭晓真相的时刻到了
在选择了网络层的判别学习率之后,就可以解冻模型,并进行相应的训练了。

Slice函数将网络的最后一层学习率设为1e-4,将第一层学习率设为1e-6。中间各层在此范围内以相等的增量设定学习率。
结果,预测准确度有所提升,但提升的并不多,我们想知道,这时是否需要对模型进行微调?
在微调任何模型之前始终要考虑的两个关键因素就是数据集的大小及其与预训练模型的数据集的相似性。在我们的例子中,我们使用“宠物”数据集类似于ImageNet中的图像,数据集相对较小,所以我们从一开始就实现了高分类精度,而没有对整个网络进行微调。
尽管如此,我们仍然能够对精度结果进行改进,并从中学到很多东西。
下图说明了使用和微调预训练模型的三种合理方法。在本教程中,我们尝试了第一个和第三个策略。第二个策略在数据集较小,但与预训练模型的数据集不同,或者数据集较大,但与预训练模型的数据集相似的情况下也很常见。

在预训练模型上微调策略
恭喜,我们已经成功地使用最先进的CNN覆盖了图像分类任务,网络的基础结构和训练过程都打下了坚实的基础。
至此,你已经可以自己的数据集上构建图像识别器了。如果你觉得还没有准备好,可以从Google Image抓取一部分图片组成自己的数据集。
开始体验吧!
-
数据集
+关注
关注
4文章
1205浏览量
24644 -
cnn
+关注
关注
3文章
351浏览量
22169 -
pytorch
+关注
关注
2文章
803浏览量
13148
原文标题:从零开始,半小时学会PyTorch快速图片分类
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
PMP10215工作半小时温度就高达127.3度,这样怎么做实际应用呢?
半小时的不眠不休,终于搞定~~~
labview2014中在一个while循环里调用dll运行半小时后就崩溃了该怎么解决?
PyTorch官网教程PyTorch深度学习:60分钟快速入门中文翻译版
textCNN论文与原理——短文本分类







 工商网监
工商网监
评论