 阿里达摩院刷新纪录,开放域问答成绩比肩人类水平
阿里达摩院刷新纪录,开放域问答成绩比肩人类水平
近日,由阿里巴巴达摩院语言技术实验室研发的 Multi-Doc Enriched BERT 模型在微软的 MS MARCO 数 据评测任务,Passage Retrieval Task(文档检索排序)和 Q&A Task(开放域自动问答)中双双刷新记录,均取得榜首(截止 2019 年 6 月 26 日)。
MS MARCO 挑战赛是 AI 阅读理解领域的权威比赛,包含 100 多万问题和近千万篇文档,参赛机构提供的 AI 模型需要从这些文档中找出 100 万个问题的正确答案。参与此次评比的还有微软、Facebook 等公司。

与斯坦福大学发起的 SQuAD 挑战赛不同,MS MARCO 数据集模拟了搜索引擎中的真实应用场景,其难度更大,是机器阅读理解领域最有应用价值的数据集之一。MS MARCO 挑战赛需要参赛者提交的模型具备理解长文档多段落,并回答复杂问题的能力。对于每一个问题,MS MARCO 提供多篇来自搜索结果的网页文档,AI 需要通过阅读这些文档来回答用户提出的问题。但是,文档中是否含有答案,以及答案具体在哪一篇文档或段落中,都需 AI 自己来判断解决。
更难的是,有一部分问题无法在文档中直接找到答案,需要 AI 自由发挥做出判断。这对机器阅读理解提出了更高要求,需要 AI 具备综合理解多文档信息、聚合生成问题答案的能力。
阿里的突破在于提出了基于“融合结构化信息 BERT 模型”的“深度级联机器阅读模型”, 可以模仿人类阅读理解的过程,先对文档进行快速浏览,判断,然后针对相应段落进行精读,并根据“自己的理解”回答问题。其中,阿里巴巴自研的算法成果——“深度级联机器阅读模型”已被 AAAI 2019 收录。
这是继 2018 年《Multi-granularity hierarchical attention fusion networks for reading comprehension and question answering》(ACL 2018)在单文档阅读理解(斯坦福 SQuAD 挑战赛)取得的成果后,阿里巴巴研究团队在机器阅读理解领域的又一次突破。
机器阅读理解模型需要的输入是
阿里巴巴研究团队在 MS MARCO 上提交的 Multi-Doc Enriched BERT 模型,正是为了解决上述问题。团队先于2019年初提出了级联学习框架《A Deep Cascade Model for Multi-Document Reading Comprehension》(AAAI 2019),设计出深度级联机器阅读框架,该方案可有效降低召回阶段延时,并最大化答案准确率,算法在召回和排序上逐步从文档级别,段落级别演化,并在最后有限的备选段落中进行答案提取工作。
随后,研究团队提出了 Enriched BERT 模型,配合 Deep Cascade Model 框架,在多文阅读理解上超过了之前广泛使用的 IR Based MRC 模型。其中,负责提供语义表征的 Enriched BERT 模型除了在 MS MARCO 上作为语言模型帮助取得双料冠军外,在国际公认的自然语言理解标准数据集 GLUE Benchmark 上也取得了 Top3 的成绩(相关技术近期公开)。
特别在 MS MARCO Q&A Task 上,阿里方面称,较之前最先进的模型有 1.5% 的 Rouge-L 绝对提升。此外,在 MS MARCO Passage Retrieval Task 上,他们自研的 Enriched BERT Base 模型领先于其他模型。

阿里方面介绍,阿里 AI 可以像人类一样在阅读并理解后快速应对天马行空的问题。比如阿里 AI 可以在毫秒内读完 2 亿字的巨著, 相当于 5 本《大英百科全书》,并根据自己的理解快速回答 100 多万个不同领域的不同问题。例如 2014 年足球世界杯的冠军是谁?哈利波特在哪里上学的?什么是宇宙中最强的磁场?阿里 AI 可以分别迅速给出答案,这一研究水平可以应对高中英语阅读理解试题。

(这一AI能力已应用在阿里电子商务平台中)
对人类而言, 阅读是获取知识、不断进步的重要途径;对机器而言,同样如此。阿里 AI 这一成果揭示了机器在理解大量复杂材料以及回答现实生活中复杂问题方面的潜力。
据阿里方面介绍,这一技术已经开始大规模应用,例如去年在 Lazada 一次线上促销活动前, 阿里 AI 仅仅花了 30 毫秒就学会 25 个在印尼促销品销售中的所有规则,并成功应用到聊天机器人中,在活动中回答问题方面的准确率达到了 96%。
围绕电商服务、导购及任务助理为核心的智能人机交互产品,在活动,规则,指南等场景中替代人工构建知识,降低人工成本,提升认 知智能能力,为海量的活动规则咨询提供解答服务。在近年来的双 11,双 12 场景及最近的 618 大促中维护效率提升 50%,相比通用方案解决率提升 10%。同时,这一技术也活跃在政务场景如市 ⺠办事咨询中,基于浙江省百万级办事指南库,”身份证到哪里换“这类咨询从等待人工回复时⻓ 2.5 天提升到了秒级响应。

以多文档开放问答场景的机器阅读为代表的语言理解技术是自然语言处理的基础能力之一,在这些基础能力之上,阿里巴巴可围绕该技术构建一系列问答类应用。在产业落地方面,问答平台及聊天机器人产 品等会伴随这项技术丰富其自身能力,降低人力成本提高效率;对于消费者来说,智能客服以后可以帮助 消费者在购物时有更好的体验。
当前,无论是在工业界还是学术界,各方研究团队都在机器阅读理解上投入大量精力。未来,除了对话和问答场景,在搜索场景中,搜索引擎将不仅仅是返回用户相关的链接和网⻚,而是通过对互联网上的海量资源进行阅读理解,直接得出答案返回给用户。
附:级联机器阅读理解模型详解
阿里方面提供的资料显示,级联学习可以通过在不同阶段采用不同的特性选择和样本筛选策略达到效果和性能的平衡,阿里巴巴提出的多文档机器阅读模型首先利用简单特征和排序模型过滤掉与问题无关的样本和段落,并得到一组候选文本,供后续从中提取答案。然后将生成的段落传递给基于注意力的深层 MRC 模型(不同于传统多层 MRC,阿里巴巴研究团队在近期公布的 Google BERT 进行了进一步的创新优化,并设计了基于 Enriched BERT 的新 MRC 模型),该模型用于提取单词级别的实际答案跨度。
为了进一步提升模型效果,该模型使用文档提取和段落提取作为辅助任务,以快速减少搜索空间的范围。重要的是,这三个任务在统一的深层 MRC 模型中共享同一个底层语言模型(Enriched BERT),这不仅可以实现粗到细的演绎过程,还可以通过迭代有效地学习更好的模型。

如上图所示,系统架构由三个核心模块组成,分别负责文档检索、段落检索和答案提取。对于前两个功能中的每一个功能,都定义了一个排序函数和一个提取函数。排序函数用于无关内容的过滤(Efficiency)。提取函数将文档提取和段落提取作为辅助任务并与最终答案提取模块(机器阅读理解) 联合优化,以提高性能(Effectiveness)。所采用的方案与以前的方法相比,关键的改进是每个模块的本地排序功能在成本和复杂性上逐步增加,在整个计算过程中保持效率和有效性竞争因素之间的平衡。
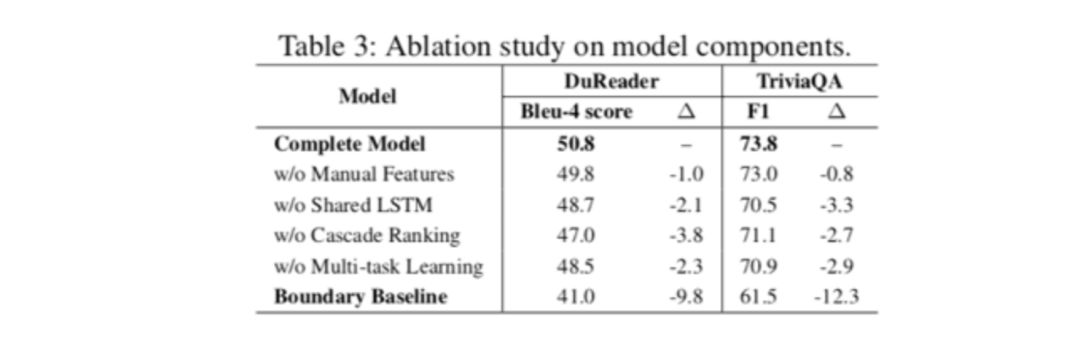
在实验中(备注:AAAI 2019 的实验中不包含 Enriched BERT 结果,后续公布),模型开发人员首先用 TriviaQA Web 和 DuReader 基准数据集验证了在离线测试中的有效性,这两套数据集通常被用作多文档 MRC 评测的标准数据集。该基准数据的结果表明,研究人员所提出的模型明显超过了以前最先进的模型, 在每个包含两个段落四个文档集的场景中性能最佳;此外,通过额外的辅助任务在初期排序中消除不相关的文档和段落,时间成本被证明是可以降低的,可以在不显著影响最终答案提取效果的情况下完成。

经过验证,团队使用阿里小蜜客服机器人系统进行了在线环境测试,该系统旨在帮助阿里巴巴集团电子商务平台解决每日约 200 万名访问者提出的问题。这些测试表明,该模型能够以低于 50 微秒的速度满足请求,同时也提高了有效性标准。
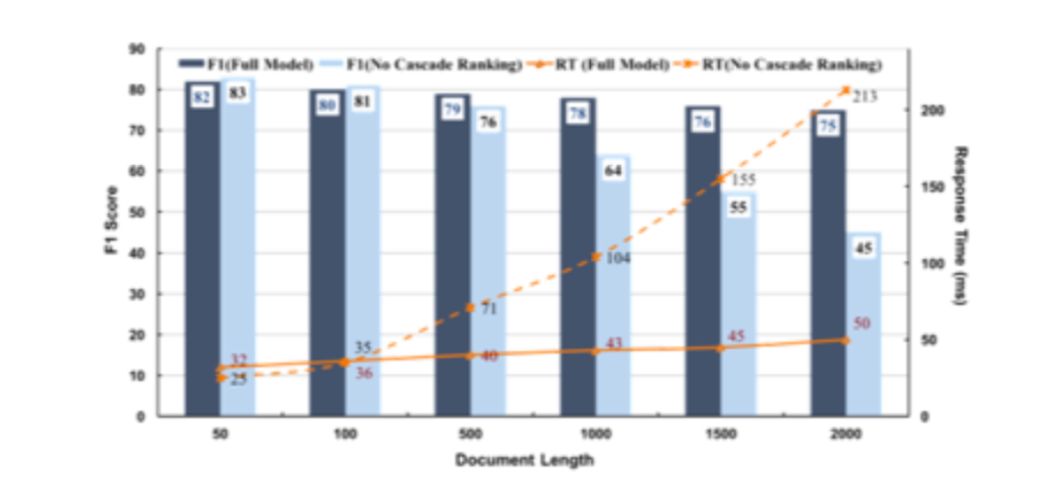
上述结果表明,通过减少无关内容的“噪声”,该模型可以大大改善现有的最先进在线答疑系统标准, 同时更好地平衡提取过程各个阶段效率和有效性。
-
AI
+关注
关注
87文章
30726浏览量
268870 -
阿里巴巴
+关注
关注
7文章
1613浏览量
47163 -
模型
+关注
关注
1文章
3226浏览量
48804
原文标题:阿里达摩院刷新纪录,开放域问答成绩比肩人类水平,超微软、Facebook
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
认识一下阿里的AI殿堂-达摩院 精选资料分享
今年黑五海信再次刷新纪录 65万台4K高清电视被美国消费者抢购一空
随着激光电视价格不断刷新纪录,替代大尺寸液晶电视的时机终于来了吗?
海信“黑五”刷新纪录 65万台4K高清电视被美国消费者抢购一空
阿里达摩院发布2019十大科技趋势
阿里达摩院首份科技趋势报告出炉:2019年十大科技趋势预测
阿里达摩院自然语言理解技术夺冠 AI技术将进一步落地发展
阿里巴巴达摩院刷新自然语言理解技术世界纪录 将推进AI技术在各领域的落地
《Beat Saber》卖出200万份 在虚拟现实社区中不断的刷新纪录
阿里达摩院斩获AI相关6大权威冠军,部分能力已超越人类





 工商网监
工商网监
评论