 百度研究人员攻陷激光雷达!
百度研究人员攻陷激光雷达!
自动驾驶汽车不仅会被「假路标」误导,开上反向车道,还会无视道路中间的障碍物,直到躲闪不及才能发现。最近密歇根大学、UIUC联合百度提交的一项研究让自动驾驶技术又一次成为了人们关注的焦点。这一次,连性能最好的传感器激光雷达(LiDAR)都被黑掉了,自动驾驶汽车真的安全吗?
用激光雷达进行目标检测是目前自动驾驶汽车用到的主流方法,这种传感器精度高、成本高昂、技术门槛高。如果昂贵的价格能买来安全,那么也能显示其价值。但最近,来自百度研究院、密歇根大学以及伊利诺伊大学香槟分校的研究者提出了一种可以「欺骗」激光雷达点云的对抗方法,对激光雷达的安全性提出了质疑。
在深度学习中,为了检测神经网络的鲁棒性,研究者通常会用特定方法生成一些不容易识别或判断的目标对神经网络进行攻击,这些目标被称为「对抗样本」。对抗样本通常是精心设计的输入,伴有小幅度的扰动,目的是诱导神经网络做出错误预测。
上述几位研究者也制作了对抗样本,不过这次是针对激光雷达的。他们提出的对抗方法名为 LiDAR-Adv,如果把用该方法生成的对抗样本打印出来,会得到下图这些奇形怪状的物体。

为了进行物理对照实验,他们还找来了普通箱子作为对照组。

对照组用到的箱子(确定不是 SF 的广告?)
接下来,他们把这些对抗样本和普通箱子分别放置在自动驾驶车行进路径的中央和右侧,观察激光雷达的反应。

将对抗样本和箱子放在路径中央
结果显示,放在路径中央时,配置激光雷达的汽车一直到逼近对抗样本时才检测出该目标,相比之下,该汽车在距离较远时就检测到了作为对照的普通箱子。

将对抗样本和对照箱放在路径右侧。
将物体放在路径右侧时情况更为糟糕,激光雷达直接「无视」了对抗样本。这让我们对自动驾驶汽车的安全性提出了很大的质疑。
容易受攻击的不止是神经网络
用对抗样本「欺骗」自动驾驶汽车的确不是什么新鲜事,如机器之心之前报道过的用「物理攻击」方式欺骗特斯拉的自动驾驶系统。在那项研究中,来自腾讯科恩实验室的研究人员在道路特定位置贴了几个贴纸,就让处在自动驾驶模式的特斯拉汽车并入反向车道。该研究中的对抗样本欺骗的是特斯拉 Model S 中的车道检测系统,即其中的深度神经网络分类器。
深度神经网络(DNN)容易受到对抗样本的攻击,这一点已经被许多研究所证明。为了证明这种攻击在现实世界构成威胁,一些研究提议生成能够迷惑分类器识别停车标志的实体贴纸或可打印贴图,如上述的特斯拉对抗攻击实验。但是,自动驾驶系统并不仅仅是图像分类器。为了获得更清晰的感知影像,大多数自动驾驶检测系统配备有激光雷达或普通雷达(无线电探测与测距)设备,这些设备能够借助于激光束直接探查周围 3D 环境。这就提出了一个疑问:贴图干扰是否会影响激光雷达扫描的点云?
为了回答这一问题,研究者提出了一种基于优化的方法——LiDAR-Adv,以生成可以在各种场景下规避激光雷达检测系统的对抗样本,从而揭露激光雷达自动驾驶检测系统的潜在漏洞。
研究者首先使用一种基于黑盒进化的算法展示了相关漏洞,接着使用基于梯度的方法 LiDAR-Adv 探索强大的对抗样本造成的影响有多大。
为了评估 LiDAR-Adv 在现实世界中的影响,研究者对生成的对抗样本进行 3D 打印,并在百度阿波罗自动驾驶平台上测试它们。结果显示,借助于 3D 感知和产品级多阶段检测器,他们能够误导自动驾驶系统,实现不同的对抗目标。
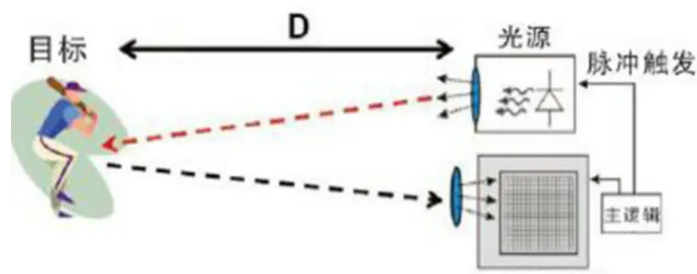
激光雷达工作原理
在分析研究者提出的对抗方法之前,我们先来了解一下激光雷达的工作原理。
如下图 2 所示,激光雷达传感器首先对 3D 环境进行扫描,获得场景的原始点云。接着,点云通过预处理馈入到检测模型。最后,对检测输出进行后处理,以预测检测结果。

图 2:激光雷达在 AV 上的检测流程图
构建激光雷达对抗样本的难点
基于激光雷达的检测系统由多个不可微分步骤组成,而不是单个的端到端网络,这种端到端网络会极大地限制基于梯度的端到端攻击的使用。
这些关键性障碍不仅令之前的图像方法无效,而且在构建对抗样本时带来如下一些新的挑战:
1)基于激光雷达的检测系统利用实体激光雷达设备将 3D 形状映射到点云上,随后点云馈入到机器学习检测系统。所以,形状扰动(shape perturbation)如何影响扫描到的点云尚不清楚;2)激光雷达点云的预处理过程是不可微的,从而避免了对基于梯度的优化器的不成熟使用;3)扰动空间受到多方面的限制。
首先,研究者需要确保可以在现实世界重建扰动目标。其次,一个目标的有效激光雷达扫描为点云的约束子集,使得扰动空间比无任何约束的点云扰动空间小得多。
LiDAR-Adv 对抗样本构建方法
如下图 1 所示,研究者提出了 LiDAR-Adv 方法,生成针对现实世界激光雷达检测系统的对抗样本。

图 1:LiDAR-Adv 概览图。图上行显示,基于激光雷达的检测系统可以检测到普通的箱子;图下行显示,LiDAR-Adv 生成的类似大小的对抗样本无法被检测到。
首先,研究者模拟了一个可微分的激光雷达渲染器,将 3D 目标的扰动与激光雷达扫描(或点云)连接起来。然后,他们利用可微分的 proxy 函数制作 3D 特征聚合。最后,他们设计不同的损失,确保生成的 3D 对抗样本平滑。
此外,为了更好地展示 LiDAR-Adv 攻击方法的灵活性,研究者在两种不同的攻击场景下对其进行了评估:
1)隐藏目标:合成一个不会被检测器检测到的「对抗样本」;
2)改变标签:合成一个被检测器识别为特定对抗目标的「对抗样本」。
研究者还对激光雷达与黑盒设置下的进化算法做了对比。
方法概览
在场景中给定一个 3D 样本 S,如 background 中所述,并在激光雷达传感器扫描该场景之后根据 S 生成点云 X,所以 X = render(s, background)。在预处理过程中,点云 X 被切割并聚合生成 x,即 H × W × 8 特征向量。研究者将这一聚合过程称为Φ: x = Φ(X)。然后,机器学习模型 M 将 2D 特征 x∈^RH×W×8 映射到 O = M(x),其中 O ∈^RH×W×7。接着,研究者利用聚类过程Ψ对 O 进行后处理,以生成检测到障碍的置信度 y_conf 和标签 y_label,所以 (y_conf , y_label) = Ψ(O)。一个对抗攻击者意图操控样本 S,以实现对抗目标。
研究者将对抗目标分为两类:
隐藏目标:通过操控现有样本 S 来隐藏 S;
改变标签:将检测到的目标 S 的标签 y 改变为特定目标 y'。
在激光雷达检测中实现上述对抗目标并非易事,面临以下三方面问题:
多阶预处理/后处理;
操作约束;
操作空间有限。
针对上述问题,研究者设计了端到端攻击管道。为了方便基于梯度的算法,研究者执行了一个近似可微且模拟激光雷达功能性的渲染器 R,从而使一组预定义射线与包含顶点 V 和倾斜点 W 的 3D 目标平面 (S) 产生交互。
预处理完成后,点云馈入到预处理函数Φ,以生成特征图 x = Φ(X)。接着,特征图 x 作为机器学习模型 M 的输入,以获得输出度量 O = M(x)。整个过程可以表征为 F(S) = M(Φ(R(S)))。
注意,通过微分渲染器 R,整个过程 F(S) = M(Φ(R(S))) 又可微分为 w.r.t. S。通过这种方式,研究者可以操控 S,从而利用最终输出 F(S) 运行的目标函数生成对抗 S_adv。
实验
在实验过程中,研究者实现了「隐藏样本」的目标,并通过基于进化的黑盒算法揭露了激光雷达检测系统存在的漏洞。然后,他们展示了白盒设置下 LiDAR-Adv 方法的定性和定量结果。此外,实验结果表明,LiDAR-Adv 方法还可以实现「改变标签」等其他一些对抗目标。
由于点云在现实场景下是连续捕获的,所以单个静态帧中的攻击可能在现实场景中的影响不大。所以在实验中,针对包含不同方向和位置的 victim 数据集,研究者生成了一个鲁棒的通用对抗样本。他们对这种通用对抗样本进行 3D 打印,并进行真实驾驶实验,从而证明这些样本的确对公路上行驶的自动驾驶车辆构成威胁。

图 3:研究人员生成的不同尺寸对抗样本,在多个激光雷达照射的情况下仍然可以保持不被检测到。

表 1:不同设置下 LiDAR-Adv 方法和基于进化方法的攻击成功率对比。
为了确保 LiDAR-Adv 方法在各种物理条件下保持对抗效果,研究者通过一组物理变换(位置和方向)来进行采样和优化。实验证明了生成的对抗样本具有鲁棒性,可以实现高成功率的隐蔽和攻击。

表 2:在受控和不可见情形下,LiDAR-Adv 方法对于不同位置和方向上攻击的成功率。
除此之外,研究者评估了 3D 打印生成的样本在物理世界的效果。如下图 5(a)所示,自动驾驶系统在 36 个不同帧中并未检测到对抗物体。如下图 5(b)所示,系统在 18 个帧中的 12 个检测到了正方体盒子。由于车速不同,总帧数也有不同。
图 5:物理攻击结果。LiDAR-Adv 方法的 3D 打印硬质对抗物体未被基于激光雷达的汽车检测系统检测到。图第 1 行显示由激光雷达传感器收集的点云数据,第 2 行显示由仪表板处相机捕获的相应图像。
-
百度
+关注
关注
9文章
2267浏览量
90350 -
激光雷达
+关注
关注
968文章
3967浏览量
189808
原文标题:自动驾驶「无视」障碍物:百度研究人员攻陷激光雷达
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
激光雷达会伤害眼睛吗?

激光雷达的维护与故障排查技巧
激光雷达技术的基于深度学习的进步
如何提升激光雷达数据的精度
光学雷达和激光雷达的区别是什么
激光雷达与毫米波雷达的优缺点是什么
单车4台AT128!禾赛获得百度萝卜快跑新一代无人驾驶平台主激光雷达独家定点

百度萝卜快跑第六代无人车携手禾赛AT128激光雷达,共筑自动驾驶新篇章
禾赛科技独供百度Apollo新一代无人车主激光雷达
单车4台AT128!禾赛科技获得百度萝卜快跑新一代无人驾驶平台主激光雷达独家定点

一文看懂激光雷达

激光雷达的探测技术介绍 机载激光雷达发展历程
激光雷达的应用场景
激光雷达LIDAR基本工作原理






 工商网监
工商网监
评论