 Facebook AI又出新作:性能翻倍,计算成本不增加
Facebook AI又出新作:性能翻倍,计算成本不增加
Facebook AI又出新作,LeCun力荐!在BERT等先进架构中插入一个“存储器”层,能极大提升网络容量和性能,同时保持计算成本基本不变。实验表明,采用新模型的12层网络性能即与24层BERT-large模型的性能相当,运行时间减少一半。
图灵奖得主,AI大神Yann LeCun发Twitter推荐。LeCun认为,本文用product key memory层替代了BERT模型中的结构层,实现了与后者相当的性能,计算量降低了一半。
本文介绍了一种可以轻松集成到神经网络中的结构化存储器。该存储器在设计上非常大,架构的容量显著增加,参数数量可达十亿个,而增加的计算成本基本上可忽略不计。存储器的设计和访问模式基于产品密钥,可实现快速准确的最近邻搜索。

这一新方法在保持计算成本不增加的同时,大幅增加了参数数量,使得整个系统在训练和测试时,能够在预测准确度和计算效率之间进行更优化的权衡。这个存储器层能够处理超大规模的语言建模任务。
在实验中,我们使用一个包含高达300亿字的数据集,并将存储器层插入最先进的transformer的架构网络中。结果表明,只有12层的存储器增强模型的性能,优于24层的基线transformer模型,而在推理时间方面,前者比后者快两倍。相关代码已经发布,以用于重现实验。
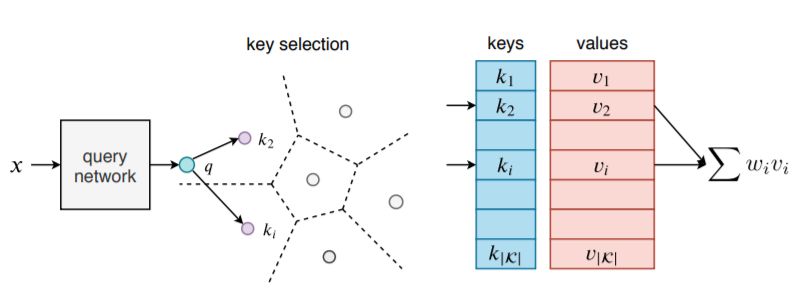
图1:键值存储器层概述:输入x通过查询网络处理,该查询网络生成查询向量q,将查询向量q与所有键进行比较。输出是与所选键相关的存储器的稀疏加权和。对于大量密钥| K |,密钥选择过程在实践中成本过高。我们的product key方法是精确的,整个搜索过程非常快。
神奇的“存储器层”:性能翻倍,计算成本不增加
本文提出了一个键值存储器(key memory)层,可以扩展到非常大的规模,同时保持对关键空间的搜索精度。该层显著增加了整个系统的容量,而增加的计算成本可以忽略不计。与基于键值存储器的现有模型(图1)不同,本文将“键”定义为两个子键的串联。更多细节如图2所示,该结构隐含地定义了一组非常大的键,每个键与值存储器槽相关。值向量集中引入了大量参数,因为参数数量与子键的数量成平方关系。
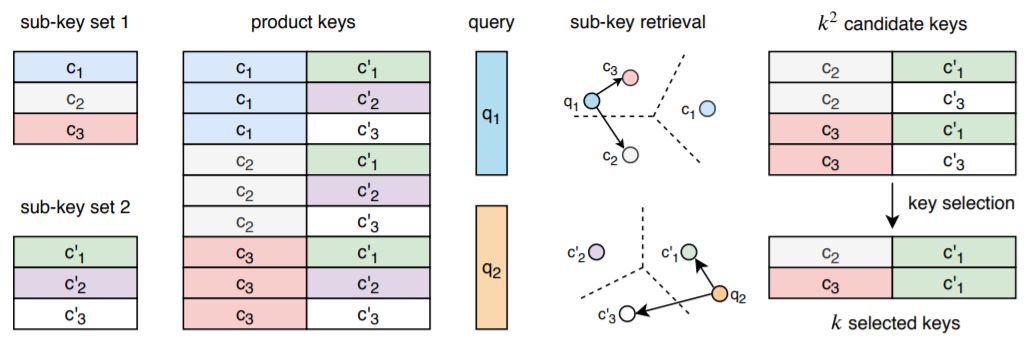
图2:product key示意图。我们定义了两个离散的密钥子集(子密钥集1和子密钥集2)。它们会产生更大的密钥集,这些密钥永远不会明文表示。对于给定的查询,我们将其分为两个子查询(q1和q2)。在每个子集中选择k个最接近的密钥(图中的k = 2),从而隐含地选择k×k个密钥。保证使用查询最大化内积的k个key属于该子集,在该子集上可以更高效地进行搜索。
尽管存储器slot数量很大,但找到输入的最精确键是非常有效的,通常需要O(p | K |)次向量比较,其中|K |是内存插槽的总数。所有存储器参数都是可训练的,但在训练时每个输入只更新少量内存slot。密钥选择和参数更新的稀疏性使训练和推理非常有效。
本文中加入的存储器层,可以解决现有架构在给定大量可用数据的情况下遇到的问题,也可以提升运行速度。我们以语言建模任务为例,将存储器层整合到流行的transformer架构中。这样做的原因是,BERT 和GPT-2 取得了巨大成功,证明了增加大型模型的容量,能够直接转化为对语言建模性能的大幅改进,反过来又能促进双语言理解任务和文本生成任务的性能提升。
总的来说,本文的主要贡献如下:
引入了一个新的网络层,大幅扩充了神经网络的容量,在训练和测试时只需要很小的计算成本,几乎可以忽略不计。
提出了新的快速索引策略,通过构造提供精确的最近邻域搜索,并避免了依赖在训练期间重新学习的索引结构产生的缺陷。
在一个大型transformer最先进网络架构中演示了本文中的方法,该网络由24层组成。我们的方法有1个存储器和12层结构,结果性能与24层transformer架构相当,推理时间则是后者的两倍。实验表明,为各种复杂性的transformer网络架构添加更多存储器层,可以为目标任务提供系统而显著的性能提升。

图3:左:典型的transformer模块由自注意力层和FFN层(双层网络)组成。右图:在我们的系统用product存储器层替换了FFN层,这类似于具有非常大的隐藏状态的稀疏FFN层。在实践中,我们仅替换N层FFN层,其中N∈{0,1,2}
实验过程
数据集
最大的公开语言建模数据集是One Billion Word语料库。在该数据集上获得良好的性能需要繁琐的正则化,因为它现在对于标准体系结构来说太小了,本实验亦然,且观察到即使是小模型也足以过度拟合。
在此数据集上,对于维度为1024的16层模型,当验证困惑(perplexity)开始增加时,获得25.3的测试困惑度。
研究人员从公共通用爬网中提取了30倍大的语料库,训练集由280亿字组成(140 GB的数据)。
与One Billion Word语料库不同,研究人员的语料库没有改变句子,允许模型学习远程依赖。在这个数据集上,没有观察到任何过度拟合,并且系统地增加模型容量导致验证集上的更好性能。
操作细节
研究人员使用具有16个attention heads和位置嵌入的transformer架构。
研究人员考虑具有12、16或24层的模型,具有1024或1600维度,并使用Adam优化器训练模型,学习率为2.5×10^(-4),其中β1=0.9,β2=0.98,遵循Vaswani等人的学习率计划。
由于使用稀疏更新来学习内存值,研究人员发现以更高的Adam学习率10^(-3)来学习它们是极好的。于是用PyTorch实现模型、在32个Volta GPU上训练,并使用float16操作来加速训练、减少模型的GPU内存使用。
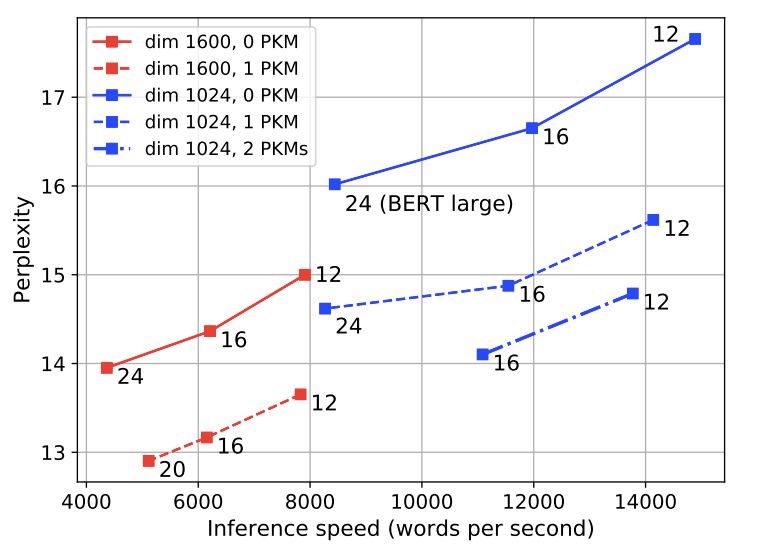
下图是对比有内和没有内存时,模型的测试困惑;以及在测试集上的速度和困惑之间进行权衡。

结果
上图显示了CC-News语料库测试集上,不同模型的困惑度。研究人员观察到,增加维度或层数会导致在所有模型中显著改善困惑。
但是,为模型添加内存比增加层数更有利;例如,当隐藏单元的数量为1024和1600时,具有单个存储器和12层的模型优于具有相同隐藏尺寸和24层的无记忆模型。
添加2或3个存储层进一步提高了性能。特别是,当内部隐藏状态具有1600维时,具有12层和存储器的模型比具有24层(与BERT large的配置相同)的模型获得更好的困惑,速度几乎快了两倍。将内存添加到内部维度等于1600的large型模型时,推理时间几乎不会增加。
消融研究(Ablation study)
在为了研究不同组件对内存层的影响,并测量它们如何影响模型性能和内存使用情况。除非特别注明,这里考虑存储器为5122=262k插槽,4个存储器磁头,k=32个选定键,研究人员将其嵌入到第5层。
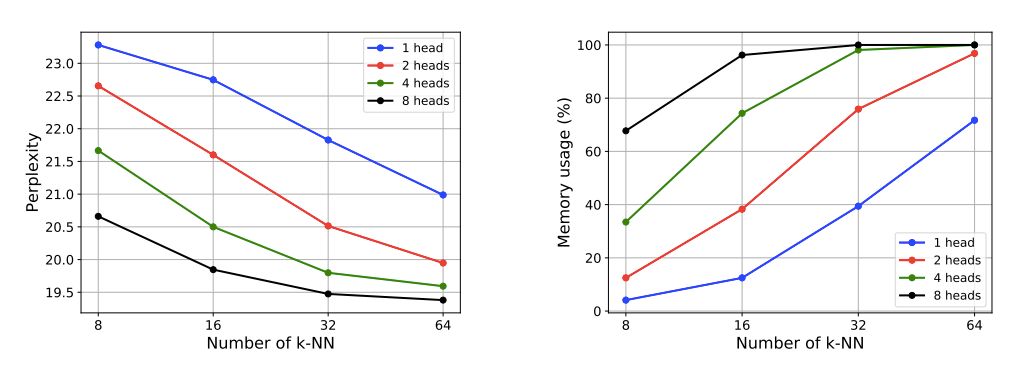
上图显示增加head数或k-NN数。可以改善模型的复杂性和内存使用。
研究人员还注意到。具有相同h×k(h是head数,k是最近邻数)的模型具有相似的内存使用。比如,(h, k) ∈ {(1, 64),(2, 32),(4, 16),(8, 8)}所有内存使用率约为70%,困惑度约为20.5。
总体上看,添加更多head可以提高性能,但也会增加计算时间。实验结果表明,head=4,k=32时可以在速度和性能之间取得良好的平衡。
总结
论文介绍了一个内存层,它允许以几乎可以忽略不计的计算开销大幅提高神经网络的容量。
该层的效率依赖于两个关键因素:将key分解为产品集,以及对内存值的稀疏读/写访问。图层被集成到现有的神经网络架构中。
研究人员通过实验证明它在大规模语言建模方面取得了重要进展,12层的性能达到了24层BERT-large模型的性能,运行时间缩短了一半。
-
AI
+关注
关注
87文章
30896浏览量
269087 -
Facebook
+关注
关注
3文章
1429浏览量
54754
原文标题:LeCun力荐:Facebook推出十亿参数超大容量存储器
文章出处:【微信号:aicapital,微信公众号:全球人工智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华迅光通AI计算加速800G光模块部署
PCB层数增加对成本有哪些影响
AI大模型的性能优化方法
黄仁勋:AI未来关键在于推理,芯片成本骤降成核心要素
最强服务器CPU来了!AI性能直接翻倍
PCB层数增加对成本的影响分析

AI大模型与传统AI的区别

NVIDIA Spectrum-X助力IBM为AI Cloud提供高性能底座





 工商网监
工商网监
评论