 阿里最新论文解读:考虑时空域影响的点击率预估模型DSTN
阿里最新论文解读:考虑时空域影响的点击率预估模型DSTN

【导语】:在本文中,阿里的算法人员同时考虑空间域信息和时间域信息,来进行广告的点击率预估。
什么是时空域?我们可以分解为空间域(spatial domain)和时间域(temporal domain)。空间域的意思即是说,在一屏的推荐中,内容是相互关联的,当推荐了第一条广告之后,第一条广告会对第二条广告的点击率产生影响,从而影响第二条推荐的广告。时间域的意思即是说,用户之前的点击或未点击的广告会影响当次的推荐。
本文介绍的论文题目为是《Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction》,论文的下载地址为:https://arxiv.org/abs/1906.03776
1、背景
CTR预估问题在广告领域十分重要,吸引了工业界和学术界学者的研究。之前我们也介绍过许多比较成功的方法,如LR、FM、Wide&Deep、DeepFM等。
但上述的方法,存在一个共同的问题,即当我们要预估对一个广告的点击概率时,只考虑该广告的信息,而忽略了其他广告可能带来的影响。如用户历史点击或者曝光未点击的广告、当前上下文已经推荐过的广告等。因此,将这些广告作为辅助信息,加入到模型中,也许可以提升CTR预估的准确性。
总结一下,辅助广告总共有三种类型:上下文广告、用户点击过的广告、用户未点击的广告,如下图所示:
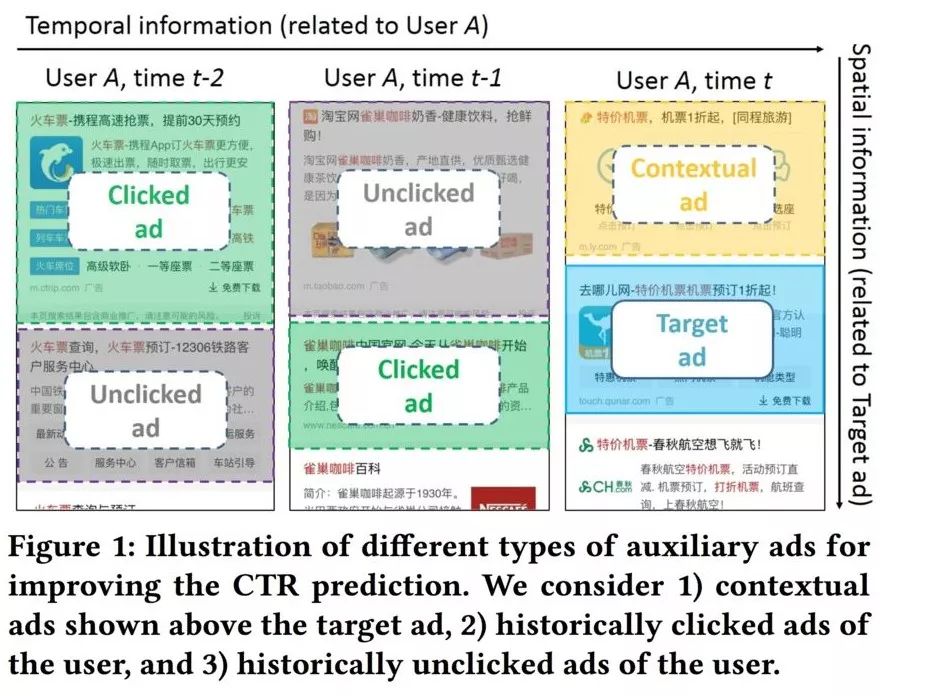
这里还是想强调一下上下文广告这个概念,之前的模型可能一次计算所有广告的点击率,然后按点击率进行排序,取top-K进行展示。但这里我们把一次推荐K个广告过程看作K个单次推荐的过程集合。先推荐第一个位置的广告,再推荐第二个位置的广告,,依次类推。在推荐第三个广告时,推荐的第一个广告和第二个广告便是我们这里所说的上下文广告。
为了将这些信息加入到模型中,必须要注意以下几点:
1)每种类型的辅助广告数量可能相差很多,模型必须适应这些所有可能的情况。2)辅助的广告信息可能与目标广告是不相关的,因此,模型需要具备提取有效信息,而过滤无用信息的能力。举例来说,用户点击过的广告可能有咖啡广告、服装广告和汽车广告,当目标广告是咖啡相关的广告时,过往点击中咖啡相关的广告可能是起比较大作用的信息。3)不同类型的辅助广告信息,有时候起到的作用可能是不同的,模型需要能够有能力对此进行判别。
总的来说,就是模型需要有能力有效处理和融合各方面的信息。
本文提出了DSTN(Deep Spatio-Temporal neural Networks)模型来处理和融合各种辅助广告信息,下一节,咱们就来介绍一下模型的结构。
2、模型架构
这里讲了三种不同的DSTN的架构,分别是DSTN - Pooling Model、DSTN - Self-Attention Model和DSTN - Interactive Attention Model。但这三种模型的Embedding部分是同样的,所以咱们先讲Embedding层,再分别介绍几种模型的结构。
2.1 Embedding Layer
Embedding Layer的结构如下:
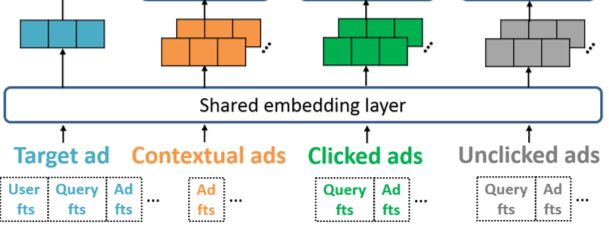
可以看到,输入有四部分信息,分别是目标广告的信息、上下文广告信息、点击广告信息、曝光未点击广告信息。目标广告信息包括用户特征、query特征(如果是搜索场景的话)、目标广告特征;上下文广告信息包括上下文广告特征;用户点击过和未点击过的广告信息包括广告特征以及对应的query特征。
这些特征可以归为三类:
单值离散特征:如用户ID、广告ID等,这类特征直接转换为对应的Embedding。
多值离散特征:如广告的标题,经过分词之后会包含多个词,每个词在转换为对应的Embedding之后,再经过sum pooling的方式转换为单个向量。
连续特征:对于连续特征如年龄,这里会进行分桶操作转换为离散值,然后再转换为对应的Embedding。
不同的特征转换成对应的Embedding之后,进行拼接操作,如目标广告信息中,会将用户ID、用户年龄、广告ID、广告名称等等对应的Embedding进行拼接;上下文广告信息中的每一个广告,会将广告ID和广告名称对应的Embedding进行拼接等等。
最终,对目标广告信息会得到一个t维的vector,计作xt;对于上下文广告信息,我们会得到nc个c维的vector,每一个计作xci;对于点击广告序列,我们会得到nl个l维的vector,每一个计作xlj;对于未点击序列,会得到nu个u维的vector,每个计作xuq。
介绍完了Embedding,接下来介绍几种不同的上层结构。
2.2 DSTN - Pooling Model
第一种结构称为DSTN - Pooling Model,其模型结构如下:
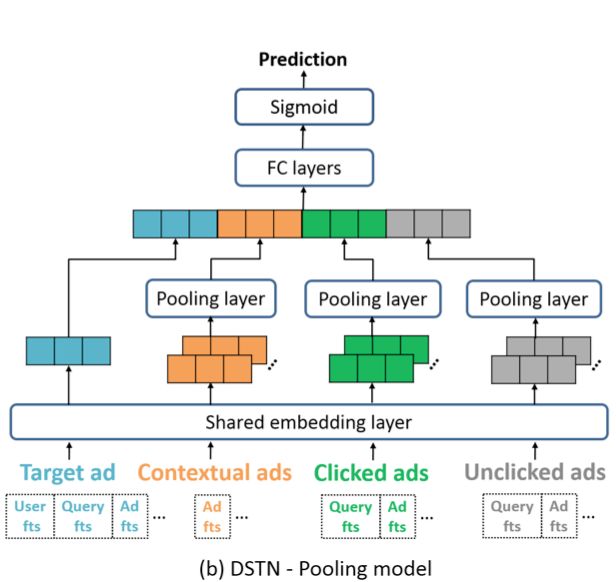
这种方式就是对上下文广告序列、点击广告序列和未点击广告序列中的vector进行简单的sum-pooling,转换为一个vector:
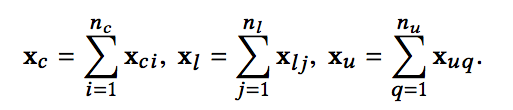
然后各部分进行拼接,经过全连接神经网络之后,在输出层经过一个sigmoid转换为点击的概率:
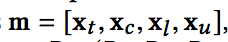
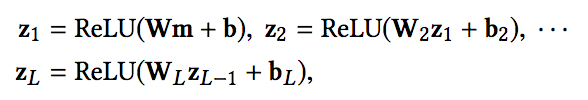
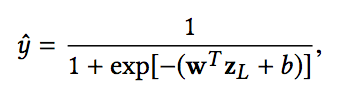
损失函数的话选择logloss:
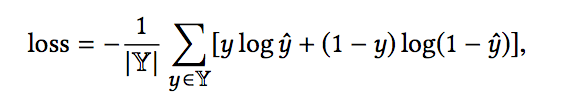
这种方式,实现比较简单,但是存在一定的缺点,当对应一个广告位置,有多个候选目标广告时,只有目标广告信息xt发生变化,其他信息都没有发生变化,这说明我们添加的辅助广告信息仅仅是一个静态信息。同时,由于使用了sum-pooling的方式,一些有用的信息可能会被噪声所覆盖。举例来说,如果目标广告是咖啡相关的, 点击序列中有一个咖啡相关的广告,有10个服饰相关的广告,那么这个咖啡相关广告的信息很容易被忽略。
2.3 DSTN - Self-Attention Model
对于sum-pooling带来的缺陷,文中提出了第二种结构,称为DSTN - Self-Attention Model,这里的Self-Attention是针对每一种特定的辅助广告信息的,也就是说,上下文广告之间进行Self-Attention,点击广告序列之间进行Self-Attention等等。
如果是上下文广告之间进行Self-Attention,其最终输出为:
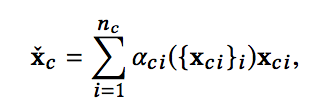
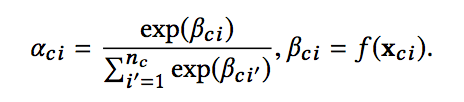
通过公式可以看出,这里并不是我们所熟知的Transformer里面的self-attention,第一次看也没注意,第二次细看才发现,所以有时候尽管名字一样,但内容也许千差万别。
这里的self-attention的含义是,将每一个广告对应的embedding vector输入到一个f中,得到一个标量输出βci,这里的f可以是一个多层全连接神经网络。然后通过softmax归一化到0-1之间,得到每一个广告的权重aci,随后基于权重进行加权求和。
使用self-attention的好处是可以对序列中的不同广告赋予不同的权重,能够在一定程度上解决sum-pooling的问题,但其仍然存在一定的缺陷。首先,self-attention中计算的权重,没有考虑target ad的信息,也就是说,针对不同的target ad,其attention权重保持不变。其次,归一化后的权重aci,其求和是等于1的,这样,当所有的广告都与目标广告关系不大时,部分广告的权重由于归一化也会变得很大。最后,每种类型的辅助广告的数量也是会产生影响的,但由于对权重进行了归一化,这个信息相当于也丢失了。
2.4 DSTN - Interactive Attention Model
因此,再针对上面的不足,提出了DSTN - Interactive Attention Model。其模型结构如下:
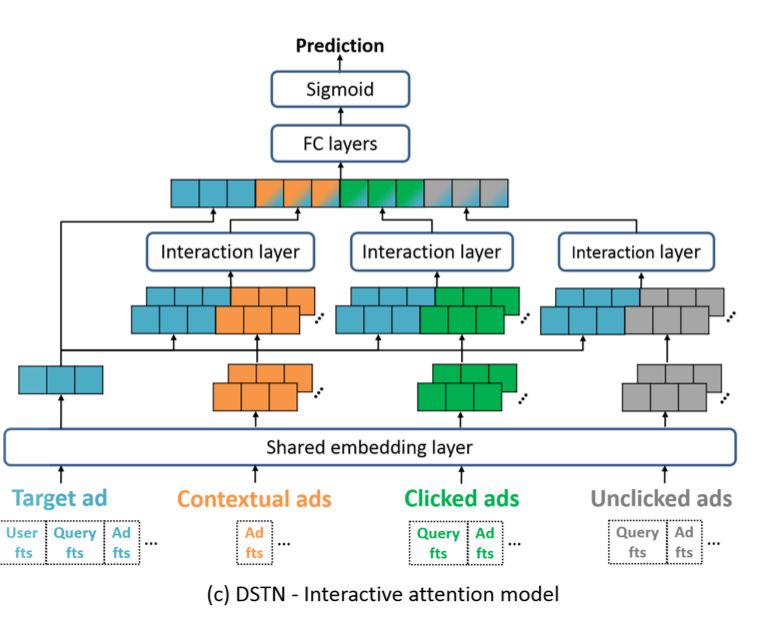
相对于self-attention,这里的权重aci没有经过归一化,其计算过程加入了目标广告的信息,计算公式如下:
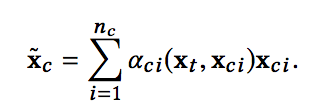
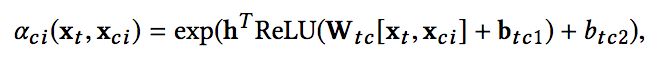
这样,针对不同的目标广告,不同类型的辅助广告信息的权重会不断变化,同时权重也没有进行归一化,避免了归一化带来的种种问题。
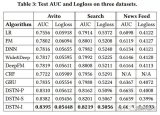
3、实验结果
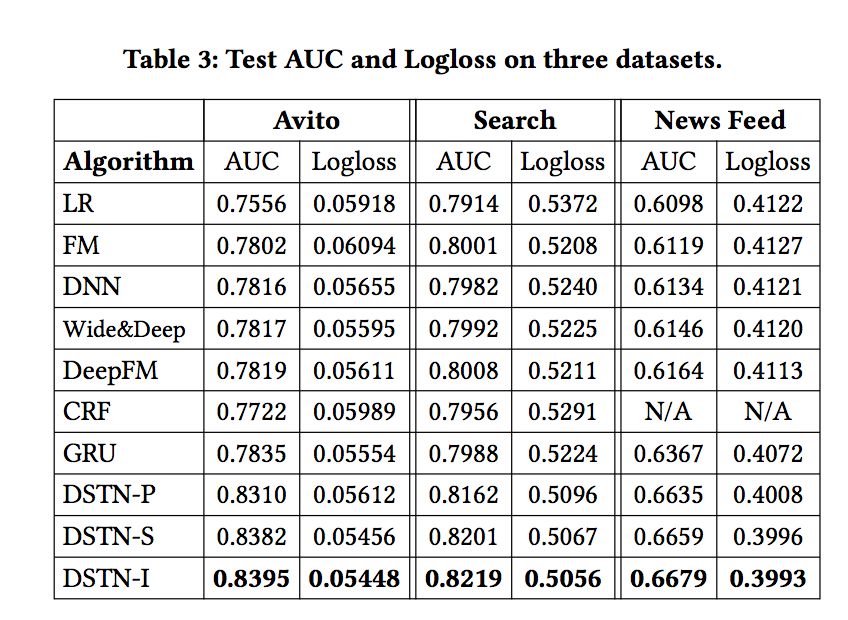
论文对比了多种模型的实验结果:
4、模型部署
看论文的时候,比较关心的一点就是模型的性能问题,因为模型中的一部分输入是上下文广告信息,更准确的前面推荐的广告的信息。假设我们有5个广告位需要推荐,比较容易想到的做法过程如下:
1、得到所有的候选广告集,并得到对应的特征,此时的上下文广告信息为空。2、模型计算所有广告的点击概率。3、选择点击率最高的一个广告。随后把这个广告加入到上下文广告信息中。4、对于剩下的广告,再计算所有广告的点击概率。5、重复第3步和第4步,直到得到5个展示的广告。
我们通过第2步得到了第一个位置的广告,重复执行3和4步4次得到剩下4个位置的广告。
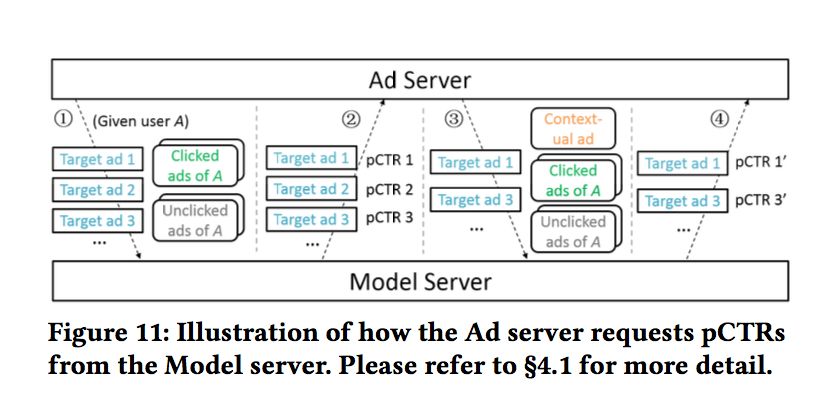
这么做无疑是十分耗时的,线上性能难以保证。因此,文中提到了一种折中的做法,每次从候选集中选择2-3个广告。其示意图如下:
5、总结
感觉本文还是有一定借鉴意义的,最主要的是在推荐过程中考虑推荐结果之间的相互关系,这么做的话个人感觉可以消除点击率预估中的坑位偏置。因为如果上下文信息有两个广告的话,模型会感知到这是对第三个坑位的广告进行推荐。同时上下文信息的加入,在一定程度上也能提升推荐结果的多样性,避免太多同质信息推荐出来。
-
神经网络
+关注
关注
42文章
4845浏览量
108342 -
模型
+关注
关注
1文章
3867浏览量
52327
原文标题:阿里最新论文解读:考虑时空域影响的点击率预估模型DSTN
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何提高网站的点击率
阿里深度学习的“金刚钻”——千亿特征XNN算法及其落地实践
详解信号的时域和空域
教程:如何使用FPGA加速广告推荐算法
萌新!怎么用Labview做一个类似于能看到一个视频播放量点击率各种数据的东西!
DSTN-LCD,DSTN-LCD是什么意思
基于时空域特性的帧间快速编码算法
深度推荐系统与CTR预估2019年值得精读的论文
基于注意力机制的深度兴趣网络点击率模型




评论