 哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型
哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型
为了进一步促进中文自然语言处理的研究发展,哈工大讯飞联合实验室发布基于全词覆盖(Whole Word Masking)的中文BERT预训练模型。我们在多个中文数据集上得到了较好的结果,覆盖了句子级到篇章级任务。同时,我们对现有的中文预训练模型进行了对比,并且给出了若干使用建议。我们欢迎大家下载试用。
下载地址:https://github.com/ymcui/Chinese-BERT-wwm
技术报告:https://arxiv.org/abs/1906.08101

摘要
基于Transformers的双向编码表示(BERT)在多个自然语言处理任务中取得了广泛的性能提升。近期,谷歌发布了基于全词覆盖(Whold Word Masking)的BERT预训练模型,并且在SQuAD数据中取得了更好的结果。应用该技术后,在预训练阶段,同属同一个词的WordPiece会被全部覆盖掉,而不是孤立的覆盖其中的某些WordPiece,进一步提升了Masked Language Model (MLM)的难度。在本文中我们将WWM技术应用在了中文BERT中。我们采用中文维基百科数据进行了预训练。该模型在多个自然语言处理任务中得到了测试和验证,囊括了句子级到篇章级任务,包括:情感分类,命名实体识别,句对分类,篇章分类,机器阅读理解。实验结果表明,基于全词覆盖的中文BERT能够带来进一步性能提升。同时我们对现有的中文预训练模型BERT,ERNIE和本文的BERT-wwm进行了对比,并给出了若干使用建议。预训练模型将发布在:https://github.com/ymcui/Chinese-BERT-wwm
简介
Whole Word Masking (wwm),暂翻译为全词Mask,是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个词缀,在生成训练样本时,这些被分开的词缀会随机被[MASK]替换。在全词Mask中,如果一个完整的词的部分WordPiece被[MASK]替换,则同属该词的其他部分也会被[MASK]替换,即全词Mask。
同理,由于谷歌官方发布的BERT-base(Chinese)中,中文是以字为粒度进行切分,没有考虑到传统NLP中的中文分词(CWS)。我们将全词Mask的方法应用在了中文中,即对组成同一个词的汉字全部进行[MASK]。该模型使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大语言技术平台LTP(http://ltp.ai)作为分词工具。
下述文本展示了全词Mask的生成样例。

基线测试结果
我们选择了若干中文自然语言处理数据集来测试和验证预训练模型的效果。同时,我们也对近期发布的谷歌BERT,百度ERNIE进行了基准测试。为了进一步测试这些模型的适应性,我们特别加入了篇章级自然语言处理任务,来验证它们在长文本上的建模效果。
以下是我们选用的基准测试数据集。
我们列举其中部分实验结果,完整结果请查看我们的技术报告。为了确保结果的稳定性,每组实验均独立运行10次,汇报性能最大值和平均值(括号内显示)。
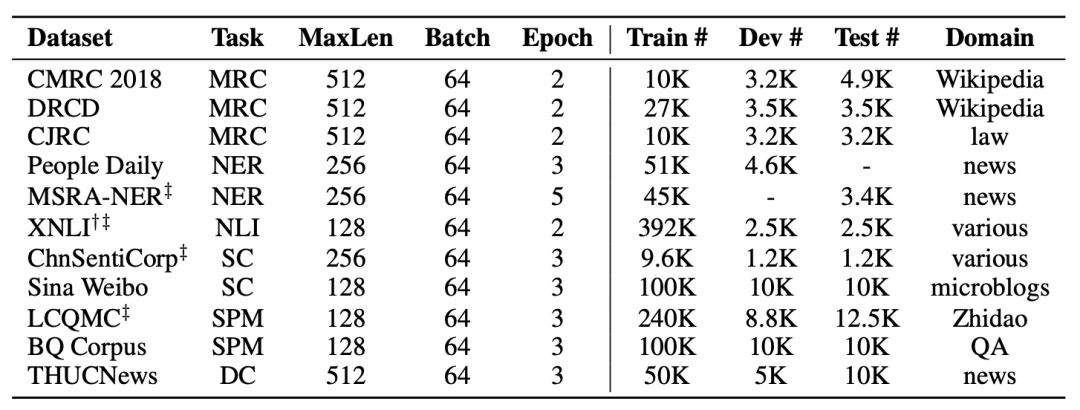
▌中文简体阅读理解:CMRC 2018
CMRC 2018是哈工大讯飞联合实验室发布的中文机器阅读理解数据。根据给定问题,系统需要从篇章中抽取出片段作为答案,形式与SQuAD相同。
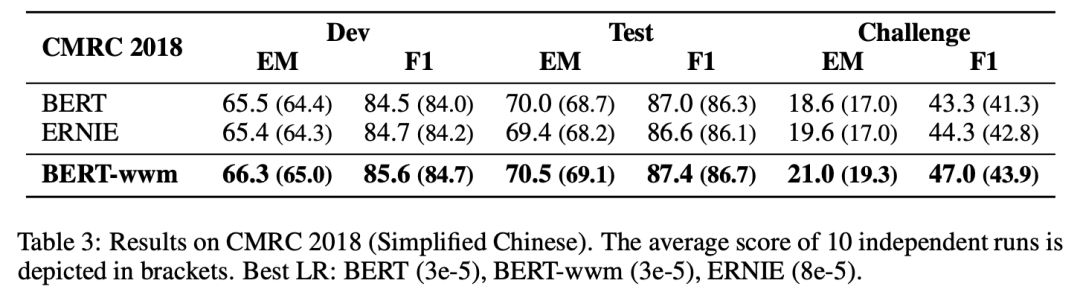
▌中文繁体阅读理解:DRCD
DRCD数据集由中国***台达研究院发布,其形式与SQuAD相同,是基于繁体中文的抽取式阅读理解数据集。
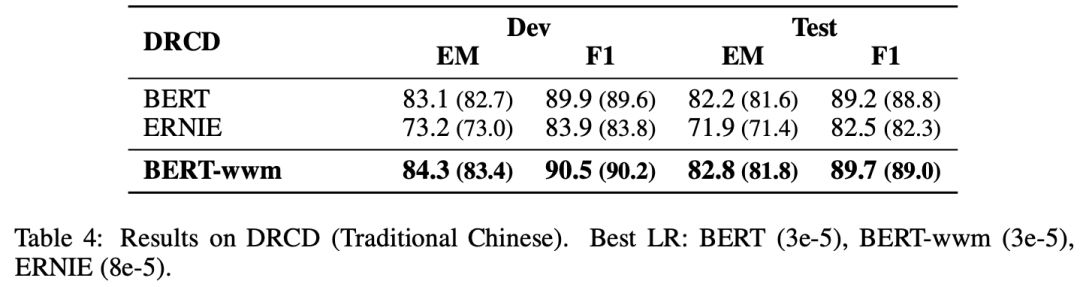
▌中文命名实体识别:人民日报,MSRA-NER
中文命名实体识别(NER)任务中,我们采用了经典的人民日报数据以及微软亚洲研究院发布的NER数据。
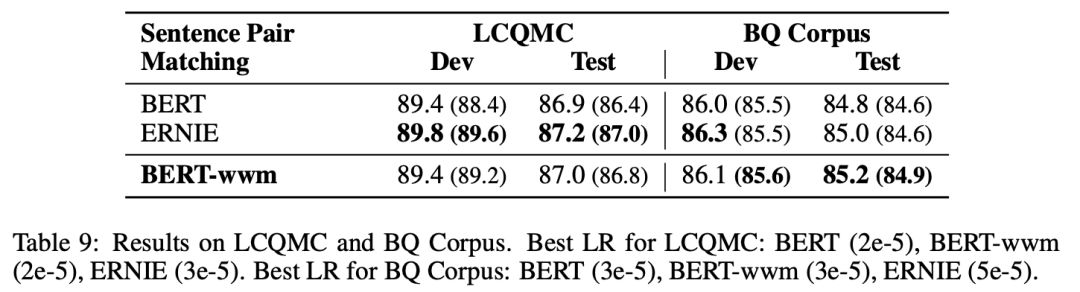
▌句对分类:LCQMC,BQ Corpus
LCQMC以及BQ Corpus是由哈尔滨工业大学(深圳)发布的句对分类数据集。
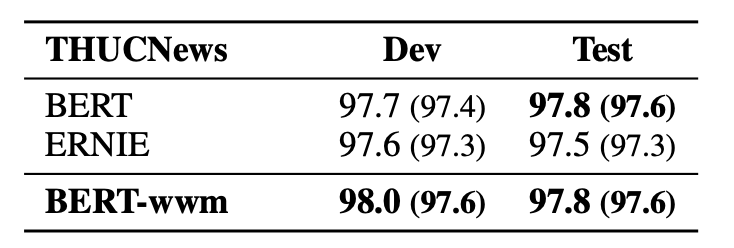
▌篇章级文本分类:THUCNews
由清华大学自然语言处理实验室发布的新闻数据集,需要将新闻分成10个类别中的一个。
使用建议
基于以上实验结果,我们给出以下使用建议(部分),完整内容请查看我们的技术报告。
初始学习率是非常重要的一个参数(不论是BERT还是其他模型),需要根据目标任务进行调整。
ERNIE的最佳学习率和BERT/BERT-wwm相差较大,所以使用ERNIE时请务必调整学习率(基于以上实验结果,ERNIE需要的初始学习率较高)。
由于BERT/BERT-wwm使用了维基百科数据进行训练,故它们对正式文本建模较好;而ERNIE使用了额外的百度百科、贴吧、知道等网络数据,它对非正式文本(例如微博等)建模有优势。
在长文本建模任务上,例如阅读理解、文档分类,BERT和BERT-wwm的效果较好。
如果目标任务的数据和预训练模型的领域相差较大,请在自己的数据集上进一步做预训练。
如果要处理繁体中文数据,请使用BERT或者BERT-wwm。因为我们发现ERNIE的词表中几乎没有繁体中文。
声明
虽然我们极力的争取得到稳定的实验结果,但实验中难免存在多种不稳定因素(随机种子,计算资源,超参),故以上实验结果仅供学术研究参考。由于ERNIE的原始发布平台是PaddlePaddle(https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE),我们无法保证在本报告中的效果能反映其真实性能(虽然我们在若干数据集中复现了效果)。同时,上述使用建议仅供参考,不能作为任何结论性依据。
该项目不是谷歌官方发布的中文Whole Word Masking预训练模型。
总结
我们发布了基于全词覆盖的中文BERT预训练模型,并在多个自然语言处理数据集上对比了BERT、ERNIE以及BERT-wwm的效果。实验结果表明,在大多数情况下,采用了全词覆盖的预训练模型(ERNIE,BERT-wwm)能够得到更优的效果。由于这些模型在不同任务上的表现不一致,我们也给出了若干使用建议,并且希望能够进一步促进中文信息处理的研究与发展。
-
数据集
+关注
关注
4文章
1205浏览量
24644 -
自然语言处理
+关注
关注
1文章
612浏览量
13506
原文标题:刷新中文阅读理解水平,哈工大讯飞联合发布基于全词覆盖中文BERT预训练模型
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
科大讯飞发布讯飞星火4.0 Turbo大模型及星火多语言大模型
华工科技联合哈工大实现国内首台激光智能除草机器人落地
荣耀与智谱携手共建AI大模型联合实验室
MediaTek与小米集团联合实验室正式揭幕
中山联合光电:精密光学实验室签约落地长春理工大学中山研究院

【大语言模型:原理与工程实践】大语言模型的预训练
西井科技和香港理工大学签署合作协议,将共建联合创新实验室

AI+教育 深圳市中小学联合实验室正式启用







 工商网监
工商网监
评论