 人工智能的两大流派的优劣比较
人工智能的两大流派的优劣比较
近期,DeepMind发表论文,称受Marta Garnelo和 Murray Shanahan的论文“Reconciling deep learning with symbolic artificial intelligence: representing objects and relations”启发,他们提出了一种新的架构,可将目前人工智能的两大流派符号派和神经网络派相结合,并取得良好效果。但是对于如此重要的论文,在国内的主流技术论坛上竟然没有什么的解读与评论,经过了两天的研究,笔者先将我对PrediNet的一些成果发布出来,供各位参考。
人工智能的两大流派的优劣比较
人工智能主要分为符号流、神经网络、遗传等几个流派,目前是神经网络和符号流比较占上峰,但是由于几个流派间基本前提不尽相同,如何将几个流派的思想整合,一直是个比较难以解决的问题,这里简要介绍一下符号和神经网络两大流派。
符号流派认为,一组对象之间存在关系可以用符号表示,符号的组合(and, or, not,等等),可以参与推理过程,但是在DeepMind之前,符号与逻辑推理的关系都是通过专家人工指定的,而不是通过对计算机进行训练获取相应的模型。
神经网络学派则是受到神经元之间相互连接的作用为启发,尤其是以神经网络为代表的算法,其实是先随机给予每个神经元一个权重(weights),然后通过与最终结果的比较,不断训练得到最终的模型。
神经网络学派的优势是在海量数据处理及预测方面表现非常好,/root但是其模型复用性不强,比如识别人脸的模型只能用于训练人脸,而不能用来识别人手或者猫脸等其它特征;而符号学派的命题型结论可以推广,但是由于过于依赖人力,所以发展缓慢。
PrediNet结合两大流派思想的方式
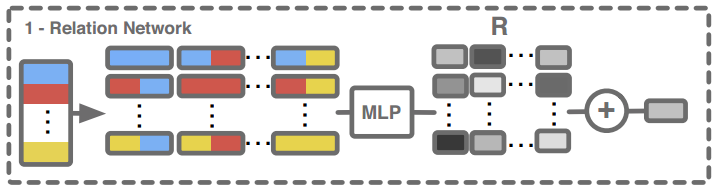
在PrediNet引用的论文“Reconciling deep learning with symbolic artificial intelligence: representing objects and relations”提出了这样一种架构,先由Relation Network处理,其中Relation(关系)是由one-hot向量表示的,也就是每个relation都是彼此独立的,彼此不相关,比如性别中的男、女就是彼此独立的,用one-hot向量表示就是(0,1)和(1,0),而如果这时把他们放入同一维度表示为1和2,就会出现一些问题,因为1和2在数学就有倍数关系存在相关性了。如果读者不好理解,可以把relation简单理解为符号(symbol),输入序列经过关系网络(Relation Network)的处理,输出给MLP(多层感知机),得到最终输出。
这次DeepMind提出的PrediNet方案,与之前的架构不尽相同,输入先经过CNN(卷积神经网络)处理,再由PrediNet处理,最后由MLP(多层感知机)进行输出如下图所示,读者可以把PrediNet看做是一个管道,连接在CNN和MLP之间。而实验的结果也说明,PrediNet训练完成后是可以被复用到的。
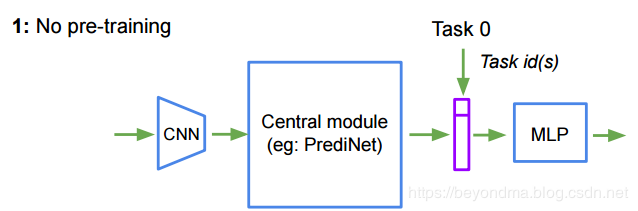
所以划重点,这次 DeepMind 提出的 PrediNet 是一种可以被神经网络派算法所使用的管道层,而且 PrediNet 这个管道层还具备一定的通用性。
PrediNet的工作原理简述
PrediNet其实是一种降维的手段,将高维数据(如图像)转换为低维的命题表示形式。这里先把论文的原文翻译一下:
PrediNet的工作分为三个阶段:注意、绑定和评估。注意阶段,其实就是使用注意力算法选取对象,绑定阶段用计算一组三个位置关系的前两个,评估阶段计算每个谓词剩余参数的值,使结果命题为真。
具体地讲,PrediNet模块由k个头组成,每个头计算对象对之间的j个关系。对于给定的输入L,每个头h使用共享权重的WS,计算相同的关系集合,但是每个头h都基于匹配键查询(key-query matching)的点积(dot-product)注意力算法,去选取对象序列的。
每个头h计算一对单独的查询Qh 1和Qh 2(通过Wh Q1和Wh Q2),但是key space K(由WK定义)在heads之间共享。将得到的注意力掩码(attention mask)对直接应用于L,得到E1和E2,再将E1和E2由一个线性映射(Ws)到一维空间,将继续送入一个元素比较器(element-wise comparation),得到一个差分向量D, 最后,将所有k个头的输出连接起来,得到最终的向量R。向量R是表示k个头和j个关系的PrediNet模块的最终输出。
cmake --build .
这里我做一下解释,首先PrediNet将工作分配N个HEAD去完成,其中每个HEAD使用了两个独立的WQ和WQ2以及一个共享的KEY,基于匹配键查询(key-query matching)的点积(dot-product)注意力算法得到一个掩码(mask),这也就是注意阶段,然后将掩码()mask)应用到输入L上,得到E1和E2,这也就是绑定阶段。接下来使用WS对于E1和E2将降维,送入比较器得到D,并结合所有HEAD得到最终结果。
如果要深入理解PrediNet,其实关键是要理解基于WQ(实际上是查询),WK(实际是键值)的匹配键查询的点积注意力算法(key-query matching dot-product),不过鉴于博主这种技术前沿的解读与分享阅读量一直很低,所以也就不再展开了。不过如果本篇阅读能超过520的表白秘笈(https://blog.csdn.net/BEYONDMA/article/details/90300624),那么下周我就来继续分享注意力算法的相关内容。
-
人工智能
+关注
关注
1800文章
48083浏览量
242158 -
神经元
+关注
关注
1文章
368浏览量
18559 -
DeepMind
+关注
关注
0文章
131浏览量
11059
原文标题:AlphaGo之父DeepMind再出神作,PrediNet原理详解
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工智能实现的流派 FPGA vs. ASIC看好谁?
人工智能是什么?
人工智能的前世今生 引爆人工智能大时代
人工智能实现的流派 FPGA vs. ASIC看好谁?
百度人工智能大神离职,人工智能的出路在哪?
人工智能的影响超乎你想象
解读人工智能的未来
人工智能医生未来或上线,人工智能医疗市场规模持续增长
人工智能芯片是人工智能发展的
arm/asic/dsp/fpga/mcu/soc的特点是什么?
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步
美、欧、日--世界PLC产品三大流派
HKMG实现工艺的两大流派及其详解
人工智能的五大流派





 工商网监
工商网监
评论