 电子发烧友App
电子发烧友App



1.研究背景
随着配电网信息化建设的推进,配电网在日常运行中产生了大量的配用电数据,但一直以来这些数据并未得到充分的挖掘和有效的利用。如今电改政策试点、售电侧放开对电力客户服务提出了更高的要求,电力行业市场化进程的深入也对电力负荷预测提出了更高的要求。目前,国内外专家和学者已经在大数据负荷预测领域展开了研究工作,也取得了一些成果。
江苏居住区配电一体化系统的全面建成、用电信息采集系统(下称“用采系统”)的全面覆盖,积累了自2009年以来全省47万配变、26万专变、3700万用户的负荷和电量数据,营销系统保存着自2009年以来全省26万大用户的业扩报装、增容、减容数据,江苏省电力公司气象信息系统积累了自2006年以来全省13地市71个气象站的10min/点温度、湿度、雨量、风速等气象数据,上述数据总量已累计达到180TB,且仍然在以每日30GB的速度快速增长。如何充分利用这些数据资源,挖掘负荷、电量、业扩、气象、经济等因素的关系,建立更加精准的负荷和电量影响模型,提高短期负荷预测的精确度,是本文的重点研究内容。
本文分析了大数据负荷预测方法的优势,介绍了配用电大数据的清洗方法,构建了多维负荷和电量模型,实现了基于配用电大数据的短期负荷预测方法,并且结合实际计算结果,验证了方法的准确性。
2.大数据负荷预测方法的优势
传统负荷预测方法大致可以分为统计算法和智能算法,统计算法包括时间序列模型、决策树、回归算法、随机森林等,智能算法包括人工神经网络、支持向量机、贝叶斯理论等基本算法及其改进算法,但上述方法由于建模时选取的样本较小,历史数据的选取直接影响负荷预测的效果。大数据负荷预测方法存在以下3点优势:
(1)考虑的影响因素更全。影响负荷走势的因素众多,主要包括两大类型:用户用电行为中体现的随机性,以及外部气象因素和节假日的影响。
(2)数据的时间跨度更长。大数据负荷预测方法选取了时间跨度更长的历史数据,用于发现负荷数据随月、季、年周期发生的变化规律。
(3)数据的空间粒度更细。大数据负荷预测方法所采用的负荷数据粒度可以细化到地区、行业、变压器、线路、台区、用户等各个级别。
3.数据源建设
江苏电力大数据平台以营配集成、用电信息采集、省地县一体化电量系统为基础,结合外部气象和经济数据,建成了江苏配用电大数据中心,为江苏配用电大数据分析工作提供了丰富的数据资源。
3.1配用电大数据的来源与分类
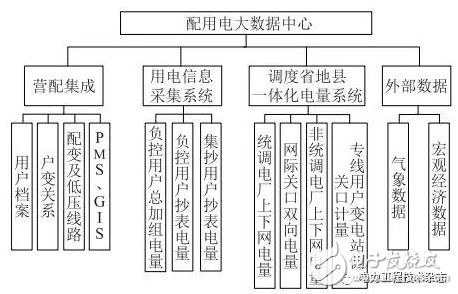
配用电大数据中心的数据体系架构如图1所示。数据主要来源于营配集成、用电信息采集系统、调度省地县一体化电量系统,以及外部的气象数据和宏观经济数据。
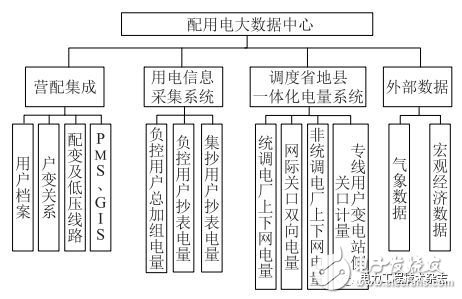
图1 配用电大数据中心的数据体系架构
3.2配用电大数据的预处理
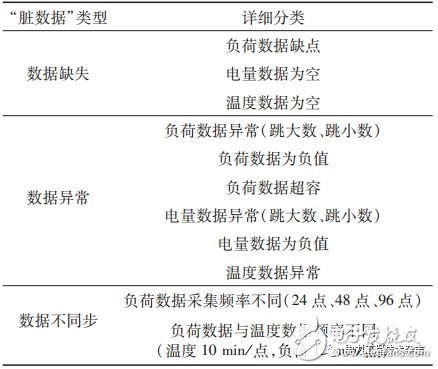
从大数据平台目前集成的所有数据类型来看,“脏数据”主要有3种大类型,11个小类,如表1所示。
表1 “脏数据”类型
3.2.1数据缺失/异常的清洗方法
数据缺失/异常的清洗主要采用了替代法和插值法。
(1)插值法。负荷数据缺点(异常)较少时,可以基于当日负荷曲线,采用插值法(如拉格朗日插值、三次样条插值等)实现负荷曲线的补全。
(2)替代法。负荷数据缺点(异常)较多,无法采用插值法时,可以用相似日(工作日选取上一周工作日,周末选取上一周周末)同一时段负荷数据替代;电量数据缺点(异常)较多时,可以用相似日(工作日选取上一月工作日,周末选取上一月周末)的电量数据替代。
3.2.2数据不同步的清洗方法
数据不同步的情况下,通常采用平均值法、强制同步法进行数据清洗。
(1)平均值法。由于极少部分终端采集频率为48点/日,因此需要将48点负荷数据扩展为96点负荷数据,可以采用平均值法进行数据扩展。
(2)强制同步法。温度数据为10min/点,而负荷数据15min/点,强制将00:10的温度数据与00:15的负荷数据匹配,00:30的温度数据与00:30的负荷数据匹配,00:40的温度数据与00:45的负荷数据集匹配,以此类推。
4.多维用电影响因素模型的构建
4.1模型构建的总体思路
由于经济数据发布频率太低,而且经济环境在一段时间内相对于气象因素而言比较稳定,因此本文只考虑气象因素和节假日建立用电影响因素模型。用电影响因素模型的总体构建思路如图2所示。
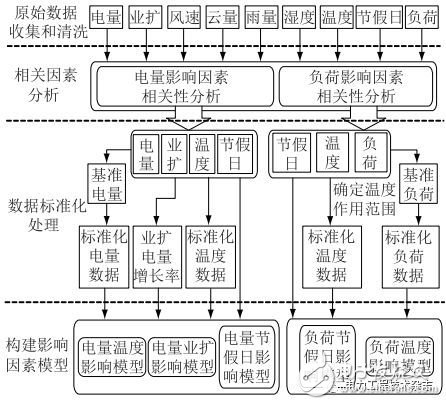
图2 用电影响因素模型构建思路
模型构建思路主要包括以下4个步骤:
(1)原始数据收集和清洗;
(2)相关因素分析;
(3)数据标准化处理;
(4)用电影响模型构建。
4.2相关因素分析
用电量受气象因素、节假日、经济形势等众多因素的影响,由于经济数据发布频率太低,而且经济环境在一段时间内相对于气象因素而言比较稳定,因此这里只考虑气象因素和节假日与用电量的相关性。
目前气象信息考虑温度、湿度、雨量、云量、气压、风速六项指标,采用式(1)的相关性计算方法分别对各影响因素进行分析:
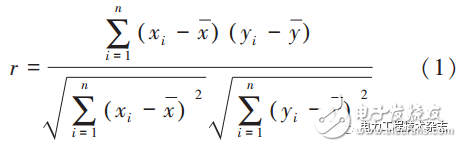
式中:xi为用户第i天的日用电量数据;x为用户n天的日用电量平均值;yi为第i天的影响因素数据(例如温度、湿度等);y为n天的影响因素数据平均值。
4.3数据标准化处理
在构建用电影响因素模型之前,需要通过计算选取合适的基准电量(负荷),实现电量(负荷)数据的标幺化,便于后期直观地分析各影响因素对电量(负荷)的影响率。数据标准化处理主要包括以下几个步骤:
(1)按度划分温度区间,将各温度区间对应的电量(负荷)数据归并,得到各温度区间内的平均电量(负荷)。
(2)绘制电量(负荷)-温度曲线,并采用七点平滑算法平滑曲线。
(3)按点计算(2)中曲线斜率,选择曲线中较为平缓的温度区间,计算该温度区间内的平均电量(负荷),作为基准电量(负荷)。
(4)采用(3)中的基准电量(负荷),标准化所有电量(负荷)数据。
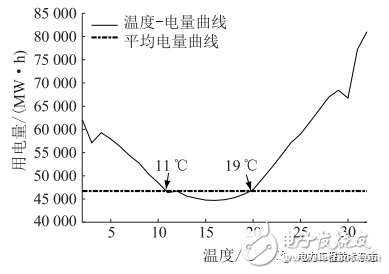
图3 南京商业电量-温度曲线
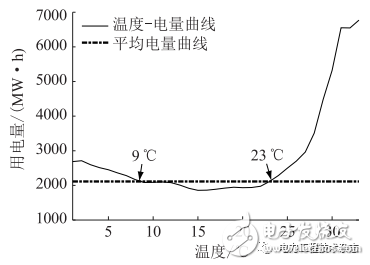
图4 苏州居民电量-温度曲线
4.4行业用电影响模型
由3.1可知,用电影响模型包括电量温度影响模型、电量业扩影响模型、电量节假日影响模型、负荷温度影响模型和负荷节假日影响模型,限于篇幅,这里主要介绍行业负荷温度影响模型和行业电量节假日影响模型的构建方法。
4.4.1行业负荷温度影响模型
(1)首先根据3.3的计算方法得到待计算行业的基准负荷(基准负荷为全年工作日96点负荷平均值Pi,其中i取值为1~96。
(2)逐日逐点计算负荷影响率:
式中:d表示工作日编号,R(d,i)为第d个工作日第i个点的负荷影响率。
(3)将温度划分为>40、<-4、-4~40这45个档位,将所有工作日的96点负荷影响率归类到对应的温度档位,形成45×96的温度—负荷影响率序列S(d,i,t),其中下标t为温度标签。
(4)逐一对S(d,i,t)中的数据集合求平均值,得到温度综合影响率C(i,t),若S(d,i,t)中某一格数据样本太少,则温度范围上下扩展1 ℃ ,重新计算温度综合影响率,若果数据样本依然过少,则将该点的温度综合影响率交给后续的模型拟合算法完成。
(5)形成负荷-温度综合影响率矩阵C(i,t)后,通过插值法修补残缺数据点,通过平滑算法平抑模型中的异常数据点,最终得到负荷温度影响模型。
(6)由于负荷数据更新较快,且过于久远的历史数据不具备参考价值,因此负荷温度影响模型每月根据新增数据更新。
4.4.2行业电量节假日影响模型
以年为计算周期,计算每年所有节假日期间,行业日电量相对于节假日前正常电量的影响率,其计算流程如下:
(1)根据实时节假日放假时间及调休安排,配置节假日信息表,为了显示节假对电量的连续影响趋势,应在实际节假日的基础上前后多配置1d,对于春节这个特殊节假日,前后多配置一周。
(2)找节假日前最近5个工作日,计算这5个工作日的平均用电量,将该电量作为基准电量。
(3)根据下式计算节假日期间每天的电量影响率:
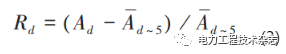
其中:Rd为节假日第d天的行业电量影响率;Ad为节假日第d天的行业用电量;Ad~5为节假日前的5个工作日的行业平均用电量。
5.短期负荷预测的实现与应用
由于江苏全省用户数量高达4000万,若全省网供负荷预测分解过细(到用户)工作量太大,且用户负荷随机性较强,预测精确度反而较低。实践表明,将全省网供负荷分解到行业级即可得到令人满意的精确度,且计算量也在合理的范围内。图5为基于配用电大数据的短期网供负荷预测方法。
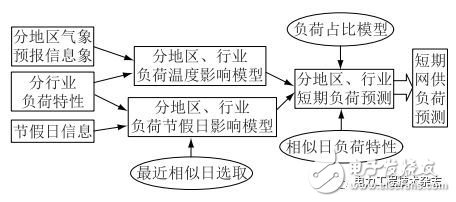
图5 基于配用电大数据的短期网供负荷预测方法示意图
在传统方法中,误差逆向传播神经网络(back propagation,BP)算法应用广泛、适应性强,以BP算法为传统方法的代表,与本文提出的大数据方法进行比较。图6为BP算法和大数据方法的全省网供负荷预测误差率。
(1)最近相似日选取;
(2)相似日气象因素剔除;
(3)预测日气象因素加成;
(4)节假日因素考虑;
(5)构建负荷占比模型;
(6)实现网供负荷预测。
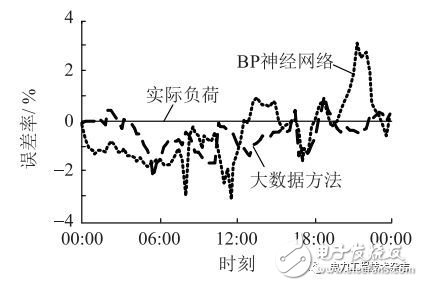
图6 短期网供负荷预测结果
6.结语
本文基于配用电大数据开展了大量的研究工作,主要进行了:
(1)配用电大数据的清洗。基于配用电大数据的特点以及实际业务的需要,分析了配用电大数据中“脏数据”的来源和类型,针对性地提出了数据清洗方法。
(2)基于配用电大数据,构建了行业负荷温度影响模型和行业电量节假日影响模型,为后期开展短期负荷预测打下基础。
(3)提出了基于大数据的短期负荷预测方法。基于多维用电影响因素模型,开展了分地区、行业的短期网供负荷预测,计算结果表明基于配用电大数据的网供负荷预测有着较高的准确性,可以为电网运行和规划提供数据支撑。












 工商网监
工商网监
评论