 电子发烧友App
电子发烧友App


什么是OCR
OCR的英文全称:
OCR是英文Optical Character Recognition的缩写,意思是光学字符识别,也可简单地称为文字识别,是文字自动输入的一种方法。它通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,所以,OCR是一种非常快捷、省力的文字输入方式,也是在文字量比较大的今天,很受人们欢迎的一种输入方式。
OCR的发展简况
OCR的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。我国研究汉字识别的起步比较晚,20世纪70年代末才开始进行OCR的研究工作。早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。
目前,比较流行的OCR软件很多,英文OCR主要有OmniPage,中文OCR主要有清华紫光OCR、清华文通OCR、汉王OCR、中晶尚书OCR、丹青OCR、蒙恬OCR等。尽管汉字字量大、字形复杂,但OCR技术已经走向成熟。许多OCR软件不仅能识别黑白印刷体汉字,还能识别灰度和彩色印刷体汉字,识别速度很快,识别正确率达到了99%以上;可识别宋体、黑体、楷体等多种字体的简、繁体;可对多种字体、不同字号的混排进行识别;有些OCR软件还能识别图像、表格。与此同时,对于手写体汉字识别的研究也取得了很大进展,正确识别率已达到了70%以上。
OCR软件的应用
在扫描仪市场上,许多类型的办公和家用扫描仪均配有OCR软件,如紫光的扫描仪配备了紫光O
CR,中晶的扫描仪配备了尚书OCR,Mustek的扫描仪配备了丹青OCR等。扫描仪与OCR软件共同承担着从文稿的输入到文字识别的全过程。
文稿扫描在办公领域中经常用到,即将报纸、杂志等媒体上刊载的有关文稿通过扫描仪进行扫描,随后进行OCR识别,或存储成图像文件,留待以后进行OCR识别,将图像文件转换成文本文件或Word文件进行存储。
此外,数字化信息的存储、传输、不仅成本低、效率高,而且能够适应排版,网络传输等不断发展的需要。目前我国有很多历史遗留下来的大量图书、报刊、杂志等纸质珍品,急需将其转换成电子信息。如电子图书馆的建立,就需要将图书逐页扫描,加上OCR软件的识别,更替代了人工键入文字的工作,大大缩短了录入时间,减轻了劳动强度,节省了人力且降低了费用,提高了录入正确率、工作效率和现代办公自动化程度。
目前OCR软件与扫描仪的搭配已应用到信息化时代的多个领域,如数字化图书馆,各种报表的识别,以及银行、税务系统票据的识别等。随着网络化、信息化的发展与普及,其应用范围将越来越广泛。
OCR系统的组成
汉字识别软件OCR的功能是将各种录入汉字、印刷体或手写体中每个汉字的图形或图像通过计算机辨认出来,并标出汉字类别代码。因此,汉字识别归根结底是一个图像识别问题。由于汉字信息量很大,具有不同的字形、字体,而且结构复杂,因此汉字识别的过程极其复杂。
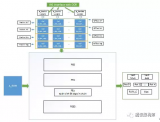
由于扫描仪的普及与广泛应用,OCR软件只需提供与扫描仪的接口,利用扫描仪驱动软件即可。因此,OCR软件主要是由图像处理模块、版面划分模块、文字识别模块和文字编辑模块等4部分组成。
1、图像处理模块
图像处理模块主要具有文稿扫描、图像缩放、图像旋转等功能。通过扫描仪输入后,文稿形成图像文件,图像处理模块可对图像进行放大,去除污点和划痕,如果图像放置不正,可以手工或自动旋转图像,目的是为文字识别创造更好的条件,使识别率更高。
2、版面划分模块
版面划分模块主要包括版面划分、更改划分,即对版面的理解、字切分、归一化等,可选择自动或手动两种版面划分方式。目的是告诉OCR软件将同一版面的文章、表格等分开,以便于分别处理,并按照怎样的顺序进行识别。
3、文字识别模块
文字识别模块是OCR软件的核心部分,文字识别模块主要对输入的汉字进行"阅读",但不能一目多行,必须逐行切割,对于汉字通常也是一个字一个字地辨认,即单字识别,再进行归一化。文字识别模块通过对不同样本汉字的特征进行提取,完成识别,自动查找可疑字,具有前后联想等功能。
4、文字编辑模块
文字编辑模块主要对OCR识别后的文字进行修改、编辑,如系统识别认为有误,则文字会以醒目的红色或蓝色显示,并提供相似的文字供选择,选择编辑器供输出等。
OCR软件的使用方法
OCR软件的种类虽然很多,但其使用方法大同小异。首先要对文稿进行扫描,然后进行OCR识别。OCR软件的使用方法如下:
1、文稿扫描
为了利用OCR软件进行文字识别,可直接在OCR软件中扫描文稿。运行OCR软件后,会出现OCR软件界面。
将要扫描的文稿放在扫描仪的玻璃面上,使要扫描的一面朝向扫描仪的玻璃面并让文稿的上端朝下,与标尺边缘对齐,再将扫描仪盖上,即可准备扫描。点击视窗中的"扫描"键,即可进入扫描驱动软件进行扫描,有关扫描方法这里不再赘述。但应注意的是:分辨力可设置在200~400dpi,对于文本文档,调整亮度适中很关键。扫描后的文档图像出现在OCR软件视窗中。
2、OCR识别
为了便于操作,可从菜单中选择选项,各种图标出现在视窗的左边。
为了更好使用,首先从上到下介绍画面左边的图标:
"放大"工具:用于放大图像;"缩小"工具:用于缩小图像;"设定识别区域"工具:用于设定识别区域;"设定识别顺序"工具:用于设定识别顺序;"删除识别区域"工具:用于删除识别区域;"擦除图像杂点"工具:用于擦除图像中的杂点;"擦拭图像块"工具:用于擦除图像中的某一区域;"旋转图像"工具:用于将图像旋转90°、180°或270°;"倾斜校正"工具:用于手动图像倾斜校正。
OCR识别的一般步骤:
(1)文稿扫描后,刚开始出现在视窗中的要识别的文字画面很小,首先选择"放大"工具,对画面进行适当放大,以使画面看得更清楚。必要时还可以选择"缩小"工具,将画面适当缩小。
(2)如果画面需要旋转90°,180°或270°,可使用"旋转图像"工具旋转图像。如果文字画面倾斜,可选择"倾斜校正"工具,将画面调正。
(3)识别时选择"设定识别区域"工具,在文字画面上框出要识别的区域,这时也可根据画面情况框出多个区域。如果所框区域有误,则可使用"删除识别区域"工具,删除所选识别区域。
(4)为了提高识别率,如果所选识别区有杂点或有不能识别的图像,则可选择"擦除图像杂点"工具,将杂点一点一点地擦除。如果需要成片地擦除,则可选择"擦拭图像块"工具。
(5)点击"识别"图标,则OCR显示正在进行文字切分,然后转入"正在识别"画面,将识别的文字逐步显示出来,"文稿校对"窗口。
许多OCR软件都具有文字修改功能,被识别出可能有错误的文字,用比较鲜明的颜色显示出来,并且可以进行修改。
(6)将识别后的文件存储成文本(TXT)文件或Word的RTF文件。















 工商网监
工商网监
评论