 电子发烧友App
电子发烧友App


确定k个划分达到平方误差最小。适用于发现凸面形状的簇,簇与簇之间区别较明显,且簇大小相近。
优点
算法快速,简单;对大数据集有较高的效率并且可伸缩;时间复杂度为O(n*k*t), 其中t是迭代次数,接近于线性,并且适合挖掘大规模数据集。
缺点
k值的选定难以估计,初始类聚类中心点的选取对聚类结果有较大的影响。经常以局部最优结束,对噪声和孤立点敏感。
算法过程
输入:k,data
1) 选取k个点作为质心;
2) 计算剩余的点到质心的距离并将点归到最近的质心所在的类;
3) 重新计算各类的质心;
4) 重复进行2~3步直至新质心与原质心的距离小于指定阈值或达到迭代上限
优化目标
聚类的基本假设:对于每一个簇,可以选出一个中心点,使得该簇中的所有的点到该中心点的距离小于到其他簇的中心的距离。虽然实际情况中得到的数据并不能保证总是满足这样的约束,但这通常已经是我们所能达到的最好的结果,而那些误差通常是固有存在的或者问题本身的不可分性造成的。
基于以上假设,N个数据点需要分为K个簇时,k-means要优化的目标函数:

其中,在数据点n被归类到簇k的时候为1,否则为0。
为第k个簇的中心。
直接寻找和来最小化J并不容易,不过可以采取迭代的办法:先固定 ,选择最优的 ,很容易看出,只要将数据点归类到离他最近的那个中心就能保证 J最小。下一步则固定,再求最优的。将 J对求导并令导数等于零,很容易得到J 最小的时候 应该满足:

即 的值应当是所有簇k中的数据点的平均值。由于每一次迭代都是取到 J的最小值,因此J 只会不断地减小(或者不变),而不会增加,这保证了k-means最终会到达一个极小值。虽然k-means并不能保证总是能得到全局最优解,但是对于这样的问题,像k-means这种复杂度的算法,这样的结果已经是很不错的了。
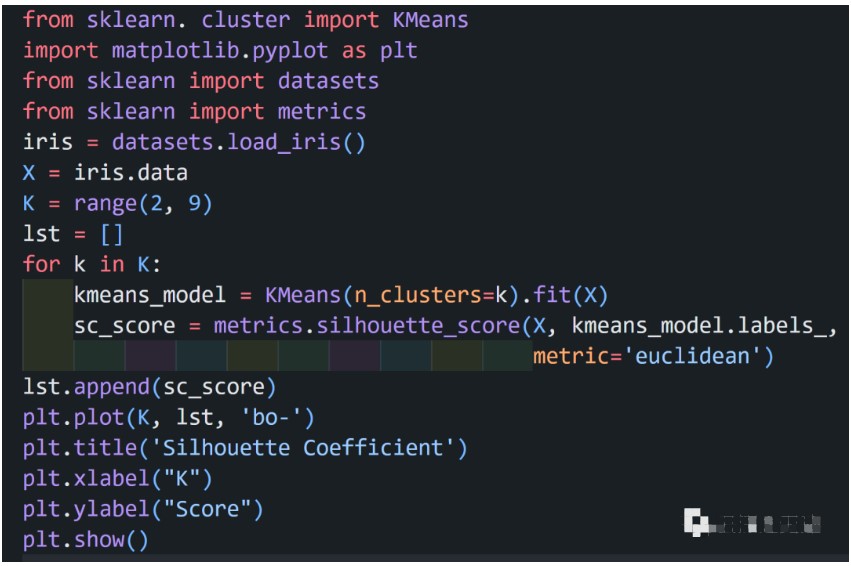
kmeans方法应用举例
[plain] view plain copy#显示数据的基本特征
#检查数据的维度
dim(iris)
#显示列名
names(iris)
#查看数据内部结构
str(iris)
#显示数据集属性
attributes(iris)
#查看前十行记录
head(iris,10)
iris[1:10,]
#查看属性Petal.Width的前五行数据
iris[1:5,“Petal.Width”]
iris$Petal.Width[1:5]
#显示每个变量的分布情况
summary(iris)
#显示iris数据集列Species中各个值出现的频次
table(iris$Species)
#根据列Species画出饼图
pie(table(iris$Species))
#画出Sepal.Length的分布柱状图
hist(iris$Sepal.Length)
#画出Sepal.Length的密度函数图
plot(density(iris$Sepal.Length))
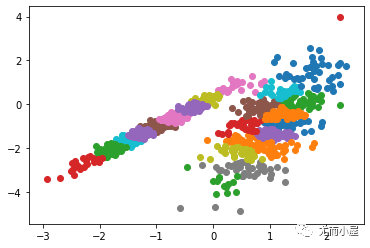
#画出Sepal.Length列和Petal.Length列的散点图
plot(iris$Sepal.Length,iris$Petal.Length)
#计算Sepal.Length列所有值的方差
var(iris$Sepal.Length)
#计算Sepal.Length列和Petal.Length列的协方差
cov(iris$Sepal.Length, iris$Petal.Length)
#计算Sepal.Length列和Petal.Length列的相关系数
cor(iris$Sepal.Length, iris$Petal.Length)
#使用Kmeans聚类
#删去类别列,即第五列,然后对数据做聚类
#1
newiris = iris[,-5]
#2
newiris = iris
newiris$Species = NULL
#将数据分为三类
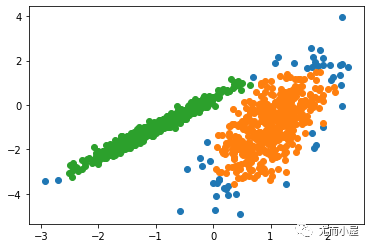
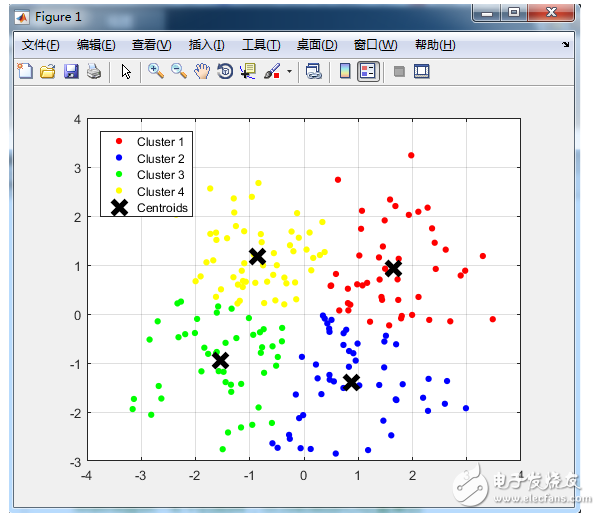
class = kmeans(newiris, 3)
#统计每种花中属于每一类的数量
table(iris$Species,class$cluster)
#以Sepal.Length为横坐标,Sepal.width为纵坐标,画散点图,颜色用1,2,3表示缺省颜色
plot(newiris[c(“Sepal.Length”, “Sepal.Width”)], col=class$cluster)
#在散点图中标出每个类的中心
points(class$centers[,c(“Sepal.Length”, “Sepal.Width”)], col=1:3, pch=8, cex=2)


【R语言实现K-means】
原始代码来自:
http://weibo.com/p/23041875063b660102vi10
[plain] view plain copyMy_kmeans = function(data, k, max.iter=10){
#获取行,列数
rows = nrow(data)
cols = ncol(data)
#迭代次数
iter = 0
#定义indexMatrix矩阵,第一列为每个数据所在的类,第二列为每个数据到其类中心的距离,初始化为无穷大
indexMatrix = matrix(0, nrow=rows, ncol=2)
indexMatrix[,2] = Inf
#centers矩阵存储类中心
centers = matrix(0, nrow=k, ncol=cols)
#从样本中选k个随机正整数作为初始聚类中心
randSeveralInteger = as.vector(sample(1:rows,size=k))
for(i in 1:k){
indexMatrix[randSeveralInteger[i],1] = i
indexMatrix[randSeveralInteger[i],2] = 0
centers[i,] = as.numeric(data[randSeveralInteger[i],])
}
#changed标记数据所在类是否发生变化
changed=TRUE
while(changed){
if(iter 》= max.iter)
break
changed=FALSE
#对每一个数据,计算其到各个类中心的距离,并将其划分到距离最近的类
for(i in 1:rows){
#previousCluster表示该数据之前所在类
previousCluster = indexMatrix[i,1]
#遍历所有的类,将该数据划分到距离最近的类
for(j in 1:k){
#计算该数据到类j的距离
currentDistance = (sum((data[i,]-centers[j,])^2))^0.5
#如果该数据到类j的距离更近
if(currentDistance 《 indexMatrix[i,2]) {
#认为该数据属于类j
indexMatrix[i,1] = j
#更新该数据到类中心的距离
indexMatrix[i,2] = currentDistance
}
}
#如果该数据所属的类发生了变化,则将changed设为TRUE,算法继续
if(previousCluster != indexMatrix[i,1])
changed=TRUE
}
#重新计算类中心
for(m in 1:k){
clusterMatrix = as.matrix(data[indexMatrix[,1]==m,]) #得到属于第m个类的所有数据
#如果属于第m类的数据的数目大于0
if(nrow(clusterMatrix) 》 0){
#更新第m类的类中心
centers[m,] = colMeans(clusterMatrix)
#centers[m,] = apply(clusterMatrix, 2, mean) #两句效果相同
}
}
iter=(iter+1)#迭代次数+1
}
#计算函数返回值
#cluster返回每个样本属于那一类
cluster = indexMatrix[,1]
#center为聚类中心
centers = data.frame(centers)
names(centers) = names(data)
#withinss存储类内距离平方和
withinss = matrix(0,nrow=k,ncol=1)
ss《-function(x) sum(scale(x,scale=FALSE)^2)
#按照类标号划分数据集,并对每部分求方差
withinss《-sapply(split(as.data.frame(data),indexMatrix[,1]),ss)
#tot.withinss为类内距离和
tot.withinss《-sum(withinss)
#类间距离
between = ss(centers[indexMatrix[,1],])
size = as.numeric(table(cluster))
#生成返回值列表cluster,tot.withinss,betweenss,iteration
result《-list(cluster=cluster,centers = centers, tot.withinss=withinss,betweenss=between,iter=iter)
return(result)
}

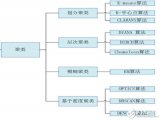
【改进】
1) 选定K的方法
a) 与层次聚类结合。首先采用层次凝聚算法决定结果簇的数目。
b) 设定一些类别分裂和合并的条件,在聚类的过程中自动增减类别的数目,得到较为 合理的类型数目k(ISODATA)
c) 根据方差分析理论(ANOVA),应用混合F统计量确定最佳分类数,应用模糊划分熵 验证最佳分类数的正确性;
d) 次胜者受罚的竞争学习规则(RPCL),对每个输入而言,不仅竞争获胜单元的权值被 修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。
2) 选定初始聚类中心
a) 采用遗传算法初始化
b) 在层次聚类的结果中选取k个类,将这k个类的质心作为初始质心
3) K-means++算法
k-means++算法选择初始质心的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。
a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心
b) 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的 距离D(x)
c) 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选 取作为聚类中心的概率较大
d) 重复b和c直到k个聚类中心被选出来
e) 利用这k个初始的聚类中心来运行标准的k-means算法
算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
a) 先从我们的数据库随机挑个随机点当“种子点”
b) 对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组 里,然后把这些距离加起来得到Sum(D(x))。
c) 再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现 是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x), 直到其《=0,此时的点就是下一个“种子点”。
d) 重复b和c直到k个聚类中心被选出来
e) 利用这k个初始的聚类中心来运行标准的k-means算法
4) 空簇处理
如果所有的点在指派步骤都未分配到某个簇,就会得到空簇。如果这种情况发生,则需要某种策略来选择一个替补质心,否则的话,平方误差将会偏大。
a) 一种方法是选择一个距离当前任何质心最远的点。这将消除当前对总平方误差影响最大的点。
b) 另一种方法是从具有最大SSE的簇中选择一个替补的质心。这将分裂簇并降低聚类的总SSE。如果有多个空簇,则该过程重复多次。






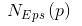





 工商网监
工商网监
评论