 电子发烧友App
电子发烧友App


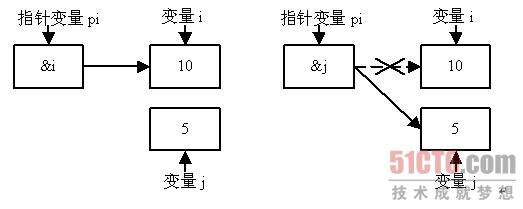
首先,你要明白一个概念,指针,是做什么的?答案是,指针,是指向地址的。程序指针,指向的空间,在物理上是Flash,在逻辑上,就是代码空间。比如说51单片机的PC指针,指向的就是Flash,即程序下一步要执行的指令的地址。
数据指针,指向的空间,在物理上有Flash和RAM,在逻辑上是Flash里的常数空间和数据空间,注意,是对于单片机来说,对于我们的电脑,常数空间不是在Flash上。
比如说51单片机的DPTR,如果用MOVC A,@A+DPTR,此时,就是指向常数空间,如果用MOVX A,@A+DPTR就是指向的数据空间。
堆栈指针,指向的空间,在物理上是RAM,在逻辑上,就是数据空间,是特定的数据空间,堆栈是数据空间中单独划分出来,专门用于寄存中间结果的内存空间。
数据指针和堆栈指针主要有两个区别:
一是数据指针可以指向Flash,即可以指向常数,比如说我们定义一个数组 unsigned char code Table[99],此时,就是DPTR可以指向常数空间。堆栈指针是不可以的,只能是指向RAM。
第二个区别,堆栈指针指向的是特定的数据空间,这个特定的数据空间,是从整个数据空间里划分出来,专门用于作堆栈用的,堆栈区间一旦划分出来,堆栈指针在规则上,就只能在这个范围内活动,如果出了这个范围,可能导致整个程序的崩溃。而数据指针在规则上,可以指向整个数据空间,但是,可以读堆栈空间,不应该去修改,否则也可能导致程序的崩溃。
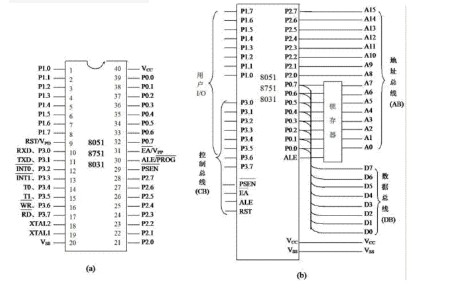
在51单片机中,SP栈指针是一个专用的8位寄存器,
系统复位后,SP初始化为07H,使得堆栈指针实际上是由08H单元开始。 在响应中断或子程序调用时,发生入栈操作,入栈的是16位PC值; 51中有PUSH压入和POP弹出栈操作指令,
如有必要,在中断或调用子程序时可用POSU指令把PSW或其它需要保护的寄存器的内容
压入堆栈加以保护;返回前再使用POP指令把它们恢复。
51的内部RAM只有从00H到7FH共计128字节的空间,而且00H~1FH是工作寄存器区, 所以SP的设定一般设定是从20H到70H这个范围。 51堆栈的容量最大也不会超过128字节。
1、在计算机领域,堆栈是一个不容忽视的概念,但是很多人甚至是计算机专业的人也没有明确堆栈其实是两种数据结构。堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除。要点:堆,顺序随意。栈,后进先出(Last-In/First-Out)。区分队列 先进先出
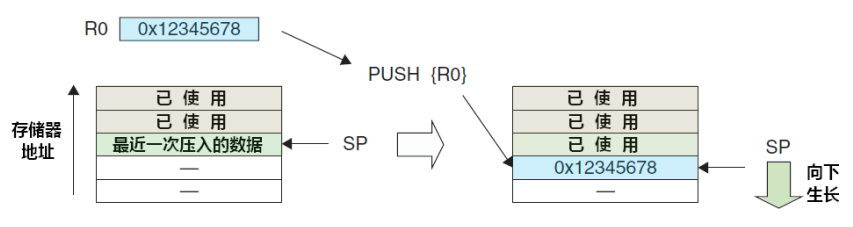
2、堆栈是一块保存数据的连续内存。 一个名为堆栈指针(SP)的寄存器指向堆栈的顶部。 堆栈的底部在一个固定的地址。 堆栈的大小在运行时由内核动态地调整。 CPU实现指令 PUSH和POP, 向堆栈中添加元素和从中移去元素。 堆栈由逻辑堆栈帧组成。
当调用函数时逻辑堆栈帧被压入栈中, 当函数返回时逻辑 堆栈帧被从栈中弹出。 堆栈帧包括函数的参数, 函数地局部变量, 以及恢复前一个堆栈 帧所需要的数据, 其中包括在函数调用时指令指针(IP)的值。 堆栈既可以向下增长(向内存低地址)也可以向上增长, 这依赖于具体的实现。 在我 们的例子中, 堆栈是向下增长的。 这是很多计算机的实现方式, 包括Intel, Motorola, SPARC和MIPS处理器。
堆栈指针(SP)也是依赖于具体实现的。 它可以指向堆栈的最后地址, 或者指向堆栈之后的下一个空闲可用地址。 在我们的讨论当中, SP指向堆栈的最后地址。 除了堆栈指针(SP指向堆栈顶部的的低地址)之外, 为了使用方便还有指向帧内固定 地址的指针叫做帧指针(FP)。 有些文章把它叫做局部基指针(LB-local base pointer)。 从理论上来说, 局部变量可以用SP加偏移量来引用。 然而, 当有字被压栈和出栈后, 这 些偏移量就变了。
尽管在某些情况下编译器能够跟踪栈中的字操作, 由此可以修正偏移 量, 但是在某些情况下不能。 而且在所有情况下, 要引入可观的管理开销。 而且在有些 机器上, 比如Intel处理器, 由SP加偏移量访问一个变量需要多条指
令才能实现。 因此, 许多编译器使用第二个寄存器, FP, 对于局部变量和函数参数都可以引用, 因为它们到FP的距离不会受到PUSH和POP操作的影响。 在Intel CPU中, BP(EBP)用于这 个目的。 在Motorola CPU中, 除了A7(堆栈指针SP)之外的任何地址寄存器都可以做FP。 考虑到我们堆栈的增长方向, 从FP的位置开始计算, 函数参数的偏移量是正值, 而局部 变量的偏移量是负值。 当一个例程被调用时所必须做的第一件事是保存前一个FP(这样当例程退出时就可以 恢复)。 然后它把SP复制到FP, 创建新的FP, 把SP向前移动为局部变量保留空间。 这称为 例程的序幕(prolog)工作。 当例程退出时, 堆栈必须被清除干净, 这称为例程的收尾 (epilog)工作。 Intel的ENTER和LEAVE指令, Motorola的LINK和UNLINK指令, 都可以用于 有效地序幕和收尾工作。
3、普通的8051MCU堆栈指针只有8位,所以堆栈不可能超过256字节13086.
SP:堆栈指针(SP,Stack Pointer),专门用于指出堆栈顶部数据的地址。
堆栈介绍:日常生活中,我们都注意到过这样的现象,家里洗的碗,一只一只摞起来,最晚放上去的放在最上面,而最早放上去的则放在最下面,在取的时候正好相反,先从最上面取,这种现象我们用一句话来概括:“先进后出,后进先出”。请大家想想,还有什么地方有这种现象?其实比比皆是,建筑工地上堆放的砖头、材料,仓库里放的货物,都是“先进后出,后进先出”,这实际是一种存取物品的规则,我们称之为“堆栈”。
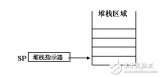
在单片机中,我们也能在RAM中构造这样一个区域,用来存放数据,这个区域存放数据的规则就是“先进后出,后进先出”,我们称之为“堆栈”。为什么需要这样来存放数据呢?存储器本身不是能按地址来存放数据吗?对,知道了地址的确就能知道里面的内容,但如果我们需要存放的是一批数据,每一个数据都需要知道地址那不是麻烦吗?如果我们让数据一个接一个地放置,那么我们只要知道第一个数据所在地址单元就能了(看图2)如果第一个数据在27H,那么第二、三个就在28H、29H了。所以利用堆栈这种办法来放数据能简化操作
那么51中堆栈什么地方呢?单片机中能存放数据的区域有限,我们不能够专门分配一块地方做堆栈,所以就在内存(RAM)中开辟一块地方,用于堆栈,但是用内存的哪一块呢?还是不好定,因为51是一种通用的单片机,各人的实际需求各不相同,有人需要多一些堆栈,而有人则不需要那么多,所以怎么分配都不合适,怎样来解决这个问题?分不好干脆就不分了,把分的权利给用户(编程者),根据自已的需要去定吧,所以51单片机中堆栈的位置是能变化的。而这种变化就体现在SP中值的变化,看图2,SP中的值等于27H不就相当于是一个指针指向27H单元吗?当然在真正的51机中,开始指针所指的位置并非就是数据存放的位置,而是数据存放的前一个位置,比如一开始指针是指向27H单元的,那么第一个数据的位置是28H单元,而不是27H单元,为什么会这样?

什么是堆栈?MCS-51单片机的堆栈怎样设置的?
答:程序设计时,往往需要一个后进先出的RAM区,以保存CPU的现场。这种后进先出的缓冲区,就称为堆栈。
MCS-51单片的堆栈原则上设在内部RAM的任意区域内 。但是,一般设在31H~7FH的范围之间,栈顶的位置由栈指针SP指出。
51单片机堆栈操作指令举例说明
这4类指令的作用是把直接寻址单元的内容传送到堆栈指针SP所指的单元中,以及把SP
所指单元的内容送到直接寻址单元中。这类指令只有两条,下述的第一条常称为入栈操作指令,第二条称为出栈操作指令。需要指出的是,单片机开机复位后,(SP)默认为07H,但一般都需要重新赋值,设置新的SP首址。入栈的第一个数据必须存放于SP+1所指存储单元,故实际的堆栈底为SP+1所指的存储单元。
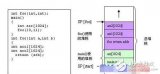
堆栈操作指令有两条: PUSH direct POP direct 第一条指令称之为推入,就是将direct中的内容送入堆栈中,第二条指令称之为弹出,就是将堆栈中的内容送回到direct中。推入指令的执行过程是,首先将SP中的值加1,然后把SP中的值当作地址,将direct中的值送进以 堆栈操作指令有两条: PUSH direct POP direct
第一条指令称之为推入,就是将direct中的内容送入堆栈中,第二条指令称之为弹出,就是将堆栈中的内容送回到direct中。推入指令的执行过程是,首先将SP中的值加1,然后把SP中的值当作地址,将direct中的值送进以SP中的值为地址的RAM单元中。例: MOV SP,
#5FH MOV A,
#100 MOV B,
#20 PUSH ACC
PUSH B
则执行第一条PUSH ACC指令是这样的:将SP中的值加1,即变为60H,然后将A中的值送到60H单元中,因此执行完本条指令后, 内存60H单元的值就是100,同样,执行PUSH B时,是将SP+1,即变为61H,然后将B中的值送入到61H单元中,即执行完本条指令后,61H单元中的值变为20。
POP指令的在单片机中执行是这样的,首先将SP中的值作为地址,并将此地址中的数送到POP指令后面的那个direct中,然后SP减1。 接上例: POP B POP ACC 则执行过程是:将SP中的值(现在是61H)作为地址,取61H单元中的数值(现在是20),送到B中,所以执行完本条指令后B中的值是20,然后将SP减1,因此本条指令执行完后,SP的值变为60H,然后执行POP ACC,将SP中的值(60H)作为地址,从该地址中取数(现在是100),并送到ACC中,所以执行完本条指令后,ACC中的值是100。
这有什么意义呢?ACC中的值本来就是100,B中的值本来就是20,是的,在本例中,的确没有意义,但在实际工作中,则在PUSH B后一般要执行其他指令,而且这些指令会把A中的值,B中的值改掉,所以在程序的结束,如果我们要把A和B中的值恢复原值,那么这些指令就有意义了。 还有一个问题,如果我不用堆栈,比如说在PUSH ACC指令处用MOV 60H,A,在PUSH B处用指令MOV 61H,B,然后用MOV A,60H,MOV B,61H来替代两条POP指令,不是也一样吗?是的,从结果上看是一样的,但是从过程看是不一样的,PUSH和POP指令
都是单字节,单周期指令,而MOV指令则是双字节,双周期指令。更何况,堆栈的作用不止于此,所以一般的计算机上都设有堆栈,单片机也是一样,而我们在编写子程序,需要保存数据时,常常也不采用后面的办法,而是用堆栈的办法来实现。 例:写出以下单片机程序的运行结果 MOV 30H,
#12 MOV 31H,
#23 PUSH 30H
PUSH 31H POP 30H POP 31H
结果是30H中的值变为23,而31H中的值则变为12。也就两者进行了数据交换。从这个例程能看出:使用堆栈时,入栈的书写次序和出栈的书写次序必须相反,才能保证数据被送回原位,不然就要出错了。 另外特别注意事项:
进行堆栈操作时,我们不能: PUSH R0 PUSH R1 而只能: PUSH 00H PUSH 01H POP也是一样。
















 工商网监
工商网监
评论