 电子发烧友App
电子发烧友App


堆栈指针sp的内容是什么
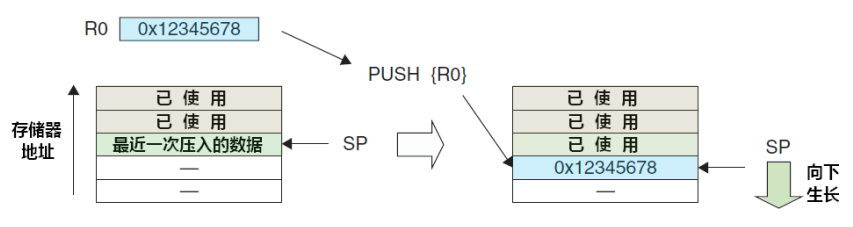
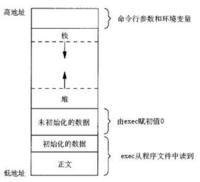
堆栈是一块保存数据的连续内存。一个名为堆栈指针(SP)的寄存器指向堆栈的顶部。 堆栈的底部在一个固定的地址。
堆栈的大小在运行时由内核动态地调整。 CPU实现指令 PUSH和POP,向堆栈中添加元素和从中移去元素。 堆栈由逻辑堆栈帧组成。 当调用函数时逻辑堆栈帧被压入栈中,当函数返回时逻辑 堆栈帧被从栈中弹出。
堆栈帧包括函数的参数,函数地局部变量,以及恢复前一个堆栈 帧所需要的数据,其中包括在函数调用时指令指针(IP)的值。 堆栈既可以向下增长(向内存低地址)也可以向上增长, 这依赖于具体的实现。在我 们的例子中,堆栈是向下增长的。

这是很多计算机的实现方式,包括Intel,Motorola,SPARC和MIPS处理器。 堆栈指针(SP)也是依赖于具体实现的。 它可以指向堆栈的最后地址,或者指向堆栈之后的下一个空闲可用地址。 在我们的讨论当中,SP指向堆栈的最后地址。除了堆栈指针(SP指向堆栈顶部的的低地址)之外,为了使用方便还有指向帧内固定 地址的指针叫做帧指针(FP)。
有些文章把它叫做局部基指针(LB-local base pointer)。从理论上来说,局部变量可以用SP加偏移量来引用。然而,当有字被压栈和出栈后,这些偏移量就变了。尽管在某些情况下编译器能够跟踪栈中的字操作,由此可以修正偏移 量,但是在某些情况下不能。而且在所有情况下,要引入可观的管理开销。而且在有些机器上,比如Intel处理器, 由SP加偏移量访问一个变量需要多条指令才能实现。因此,许多编译器使用第二个寄存器, FP, 对于局部变量和函数参数都可以引用,因为它们到FP的距离不会受到PUSH和POP操作的影响。
在Intel CPU中,BP(EBP)用于这 个目的。在Motorola CPU中, 除了A7(堆栈指针SP)之外的任何地址寄存器都可以做FP。 考虑到我们堆栈的增长方向,从FP的位置开始计算,函数参数的偏移量是正值, 而局部 变量的偏移量是负值。 当一个例程被调用时所必须做的第一件事是保存前一个FP(这样当例程退出时就可以 恢复)。 然后它把SP复制到FP,创建新的FP,把SP向前移动为局部变量保留空间。这称为 例程的序幕(prolog)工作。 当例程退出时,堆栈必须被清除干净,这称为例程的收尾 (epilog)工作。Intel的ENTER和LEAVE指令, Motorola的LINK和UNLINK指令,都可以用于 有效地序幕和收尾工作。
一个简单的堆栈例子
example1.c:
------------------------------------------------------------------
void function(int a, int b, int c) {
char buffer1[5];
char buffer2[10];
}
void main() {
function(1,2,3);
}
------------------------------------------------------------------
使用gcc的-S选项编译, 以产生汇编代码输出:
$ gcc -S -o example1.s example1.c
通过查看汇编语言输出, 我们看到对function()的调用被翻译成:
pushl $3
pushl $2
pushl $1
call function
以从后往前的顺序将function的三个参数压入栈中, 然后调用function()。 指令call会把指令指针(IP)也压入栈中。 我们把这被保存的IP称为返回地址(RET)。 在函数中所做的第一件事情是例程的序幕工作:
pushl ëp
movl %esp,ëp
subl $20,%esp
将帧指针EBP压入栈中。 然后把当前的SP复制到EBP, 使其成为新的帧指针。 我们把这个被保存的FP叫做SFP。 接下来将SP的值减小, 为局部变量保留空间。
内存只能以字为单位寻址。 一个字是4个字节, 32位。 因此5字节的缓冲区会占用8个字节(2个字)的内存空间, 而10个字节的缓冲区会占用12个字节(3个字)的内存空间。 这就是为什么SP要减掉20的原因。 这样我们就可以想象function()被调用时堆栈的模样(每个空格代表一个字节):
内存低地址 内存高地址
buffer2 buffer1 sfp ret a b c
《------ [ ][ ][ ][ ][ ][ ][ ]
堆栈顶部 堆栈底部
制造缓冲区溢出
现在试着修改我们第一个例子, 让它可以覆盖返回地址, 而且使它可以执行任意代码。堆栈中在buffer1[]之前的是SFP, SFP之前是返回地址。 ret从buffer1[]的结尾算起是4个字节。应该记住的是buffer1[]实际上是2个字即8个字节长。 因此返回地址从buffer1[]的开头算起是12个字节。 我们会使用这种方法修改返回地址, 跳过函数调用后面的赋值语句‘x=1;’, 为了做到这一点我们把返回地址加上8个字节。 代码看起来是这样的:
example3。c:
--------------------------------------------------------------------
void function(int a, int b, int c) {
char buffer1[5];
char buffer2[10];
int *ret;
ret = buffer1 + 12;
(*ret) += 8;
}
void main() {
int x;
x = 0;
function(1,2,3);
x = 1;
printf(“%d\n”,x);
}
-------------------------------------------------------------------
我们把buffer1[]的地址加上12, 所得的新地址是返回地址储存的地方。 我们想跳过赋值语句而直接执行printf调用。
如何知道应该给返回地址加8个字节呢? 我们先前使用过一个试验值(比如1), 编译该程序, 祭出工具gdb:
-----------------------------------------------------------------
[aleph1]$ gdb example3
GDB is free software and you are welcome to distribute copies of it
under certain conditions; type “show copying” to see the conditions。
There is absolutely no warranty for GDB; type “show warranty” for details。
GDB 4。15 (i586-unknown-linux), Copyright 1995 Free Software Foundation, Inc.。。
(no debugging symbols found)。。.
(gdb) disassemble main
Dump of assembler code for function main:
0x8000490 : pushl ëp
0x8000491 : movl %esp,ëp
0x8000493 : subl $0x4,%esp
0x8000496 : movl $0x0,0xfffffffc(ëp)
0x800049d : pushl $0x3
0x800049f : pushl $0x2
0x80004a1 : pushl $0x1
0x80004a3 : call 0x8000470
0x80004a8 : addl $0xc,%esp
0x80004ab : movl $0x1,0xfffffffc(ëp)
0x80004b2 : movl 0xfffffffc(ëp),êx
0x80004b5 : pushl êx
0x80004b6 : pushl $0x80004f8
0x80004bb : call 0x8000378
0x80004c0 : addl $0x8,%esp
0x80004c3 : movl ëp,%esp
0x80004c5 : popl ëp
0x80004c6 : ret
0x80004c7 : nop
------------------------------------------------------------------
我们看到当调用function()时, RET会是0x8004a8, 我们希望跳过在0x80004ab的赋值指令。 下一个想要执行的指令在0x8004b2。 简单的计算告诉我们两个指令的距离为8字节。
















 工商网监
工商网监
评论