 电子发烧友App
电子发烧友App


四、Volatile变量的使用
volatile变量的读写对所有线程立即可见
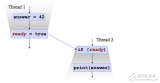
只是读和写一步,复杂的运算不能保证对其他线程可见,因为复杂的运算可能会被编译成多条指令,JMM只保证,volatile变量从工作内存写回到主存是对其他线程可见的。先看一个具体的例子。
static volatile int i = 0;
// -XX:+PrintGC
// -XX:+PrintGCDetails
// -Xms20m
// -Xmn10m
// -Xmx20m
// -XX:+UseSerialGC
// -XX:MaxTenuringThreshold=15
// -XX:-HandlePromotionFailure
// -XX:+PrintHeapAtGC
public static void main(String[] args) {
int a = i++;
}1234567891011121314
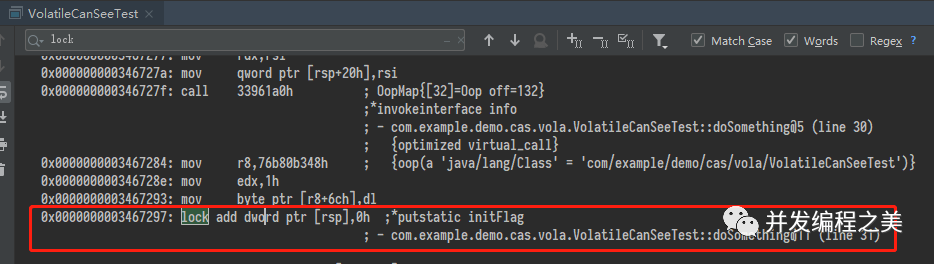
编译后的指令
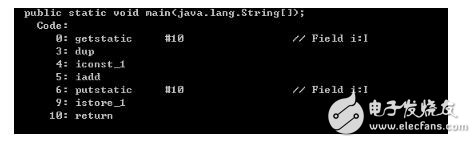
JMM只是能够保证(并不一定能够保证,但是一条字节码的指令也是由若干机器指令完成的,但是能够说明问题了)getstatic 和 putstatic volatile变量的时候是原子的,至于中间的一些列操作,并不能够保证再次期间没有其他线程对i操作生成脏数据。也就是,JMM保证get操作的值是当前内存中最新的,以及put之后内存中i的对其他内存可见。
禁止指令的重排序
这一点,《java并发编程的艺术》一书中讲的比较详细。
重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。JMM针对编译器制定的volatile重排序规则见下表。
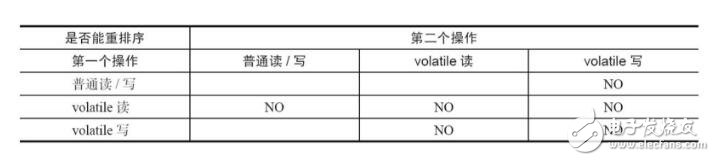
个人总结来说,
volatile的读下面的任何操作都不能重排序到volatile读操作的上方,volatile上面的普通读写可重排序到下方。
volatile的写上面的任何操作都不能重排序到volatile写操作的下方,volatile下面的普通读写可重排序到上方。
任何两个volatile的读写顺序不能重排。
为了实现上述的volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。(StoreStore等屏障的介绍见文章最后)
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。
插入屏障后的效果见下图
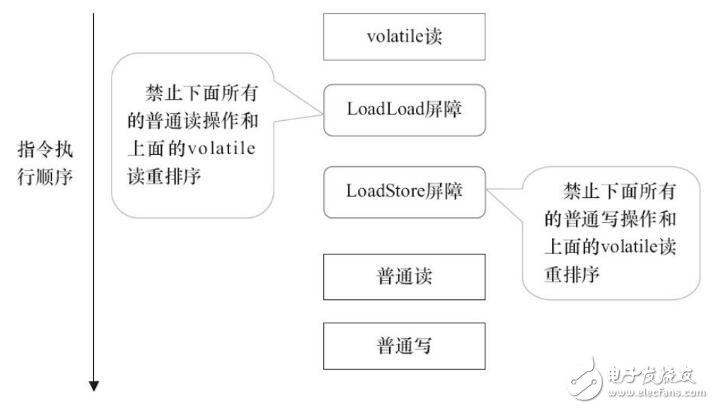
LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
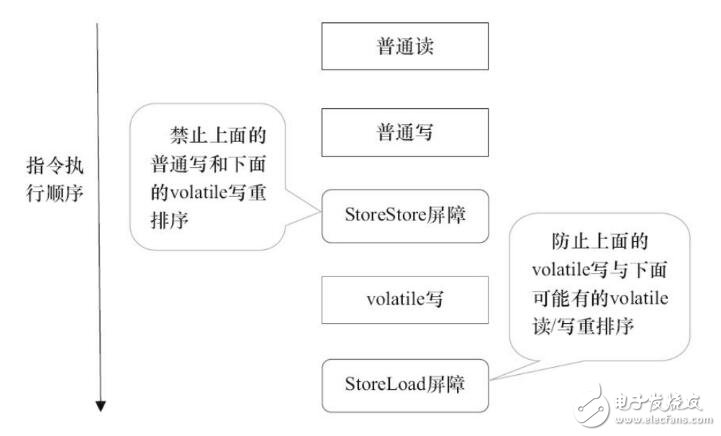
StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
上面这段话引自《java并发编程的艺术》一书,但是不是很明白,volatile的写前面的所有操作都不得拍到volatile写之后,为什么这里只加入了Store-Store屏障呢,这样普通读不就可以重拍到volatile写的下方了??????
如果,volatile读的上面还有volatile读,因为volatile读下面都会插入load-load屏障,所以两者不会重排。如果volatile读的上面还有volatile写,volatile写后面加入了store-load,所以下面的volatile读不能能与之重排序。
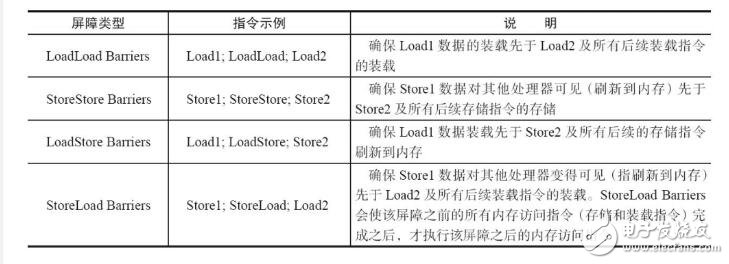
屏障介绍:














 工商网监
工商网监
评论