 电子发烧友App
电子发烧友App


联机分析处理
联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息。
数据仓库和联机分析处理(OLAP)是决策支持基本要素,已经日益成为数据库行业的重点。许多商业产品和服务现已推出,并且所有主要的数据库管理系统供应商现在已经在这些领域提供产品。决策支持,相比于传统的联机事务处理应用程序,会有些不同的要求数据库技术。本文提供的数据概述数据仓库和OLAP技术,着眼于他们的新的要求。我们描述后端工具来提取,清洁和数据加载到数据仓库;典型OLAP的多维数据模型;前端客户端工具用于查询和数据分析;服务器扩展来高效的查询处理;用来管理元数据和仓库工具。此外,勘测技术现状,本文还指出了一些有前景的研究问题,其中一些涉及数据库研究界合作多年的研究的问题,但其他一些问题只是刚刚开始被解决。本概述是基于一个教程,有作者们在会议VLDB 1996年提出。
1. 介绍
数据仓库是决策支持技术的集合,旨在使知识工作者(总裁,经理,分析师)做出更快更好的决策。过去三年已经看到的爆炸性的增长,无论是在所提供的产品和服务的数量,还是在采用这些技术的工业领域。按照META集团说法,数据仓库市场,包括硬件,数据库软件和工具,预计是由1995年的20亿美金增长到1998年分80亿美金。数据仓库技术已经成功部署在许多行业:制造业(订单运输和客户支持),零售(用于用户分析和库存管理),金融服务(理赔分析,风险分析,信用卡分析和欺诈检测),交通(车队管理),电信(呼叫分析和欺诈检测),公用事业(电力使用分析)和医疗保健(对于结果的分析)。本文介绍了数据仓库技术的路线图,着重于有特殊需求的数据仓库数据库管理系统(DBMS)。
数据仓库是一个“面向主题的,集成的,随时间变化的,非易失性的,主要用于组织决策的数据集合。 ”通常情况下,数据仓库用来分别维护组织的不同业务的数据库。有很多原因来这么做。数据仓库支持在线分析处理(OLAP ),它的功能和性能要求完全不同于由业务数据库所支持的联机事务处理( OLTP)应用程序。
OLTP应用程序通常使得文书数据处理任务自动化,如订单录入和银行交易等一些组织的日常运作。这些任务是结构化和重复性,以及由短的,原子,孤立的交易。该交易需要详细,最新的数据,通常通常访问他们的主键来读取或更新少数(几十)记录。操作数据库往往是百兆到千兆字节。数据库的一致性和可恢复性是至关重要的,最大化事务吞吐量是关键性能指标。因此,数据库被设计为反映已知的应用,特别是的操作语义,以尽量减少并发冲突。
数据仓库,相反的,是有针对性的决策支持。历史,总结和整合的数据比详细的,个人记录更重要。由于数据仓库包含合并数据,或许可以从几个业务数据库,在一段时间可能很长的时期,他们往往要比业务数据库较大的订单;企业数据仓库预计为数百GB到TB级大小。工作负载大多是查询密集型与临时性的,复杂查询可以访问数以百万计的记录,并进行了大量的扫描,联接和聚合。查询吞吐量和响应时间比事务吞吐量更重要。
促进复杂的分析和可视化、数据仓库通常多维建模。例如,在一个销售数据仓库,销售,销售区域、销售人员和产品可能是一些感兴趣的维度。通常,这些维度是分层次的;销售时间可能是组织为day-month-quarter-year的层次结构,产品作为product-category-industry的层次结构。典型的OLAP操作包括上钻(增加聚合的水平)和下钻(减少聚合的水平或增加细节)以及一个或多个维度层次结构切割(选择和投影),轴转(调整的多维视图的数据)。
由于已有的业务数据库已经很好的支持已知的OLTP工作负载,所以试图对业务数据库执行复杂的OLAP查询,将导致不可接受的性能。此外,决策支持需求的数据可能从业务数据库中丢失;例如,了解趋势或进行预测所需要历史数据,而业务数据库只存储当前的数据。决策支持一般需要从多个不同来源的数据进行整合:这可能包括外部资源,如股票的市场反馈需要额外的几个业务数据库。不同的来源可能含有不同质量的数据,或使用不一致的陈述,代码和格式,需要协调。最后,支持多维数据模型和操作的典型OLAP需要特殊的数据组织,访问方式和实现方法,不是如一般的商业数据库管理系统用来针对OLTP。由于这些原因,数据仓库的实现有别于业务数据库。
数据仓库可能会实施在标准的或扩展的关系DBMS 上,就是所谓关系型OLAP(ROLAP )服务器。这些服务器假设数据存储在关系数据库,并且支持扩展SQL和特殊访问及实施方法来有效实现多维数据模型和操作。相比之下,多维OLAP ( MOLAP)服务器直接把多维数据存储在特定的数据结构(例如,数组),并实现了OLAP在这些特点的数据结构的操作。
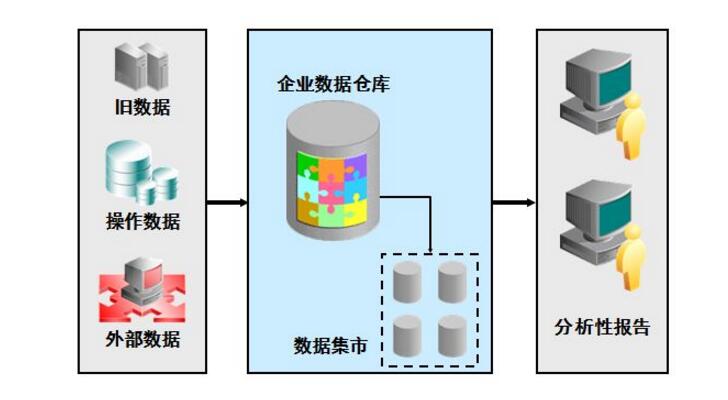
这不仅仅是建设和维护一个数据仓库,还需要选择一个OLAP服务器并为仓库明确模式和一些复杂的查询。存在着不同结构的替代品。许多组织希望实施综合性企业的仓库,收集跨越整个组织的所有科目(例如,客户,产品信息,销售,资产,人员)。然而,构建企业级数据仓库是一个漫长而复杂的过程,需要广泛的业务建模,可能需要多年才能成功。相反的,一些组织满足于数据集市,它是针对选定的科目的子集(例如,营销数据可能包括客户,产品和销售信息) 。这些数据集市实现更快的推算,因为它们不需要企业广泛的共识,但如果一个完整的商业模式并不发达的话,从长远来看,它们可能会导致复杂的集成问题。
在第2节,我们描述了一个典型的数据仓库体系结构,和设计和操作数据仓库的过程。在3-7节,我们回顾了在数据加载相关技术和刷新数据仓库,仓库服务器,前端工具和仓库管理工具。在每一种情况下,我们指出什么是传统的数据库技术不同的,我们会提到有代表性的产品。在本文中,我们不打算提供每个类别的所有产品的综合描述。我们鼓励有兴趣的读者看看在最近的商业杂志,如Databased Advisor, Database Programming,Design, Datamation,DBMS Magazine, vendors’ Web sites来获取商业产品,白皮书和案例研究的更多细节。OLAP Council是在整个行业的标准化工作上一个很好的信息源。还有科德等人的论文定义了OLAP产品的12条规则。还有,Data Warehousing Information Center是数据仓库和OLAP良好的资源。
数据仓库的研究是相当新的,并一直专注的主要是查询处理和视图维护问题。还有很多开放性的研究问题,在第8节,我们会简要提及的这些问题并得出结论。
2. 架构与端到端流程
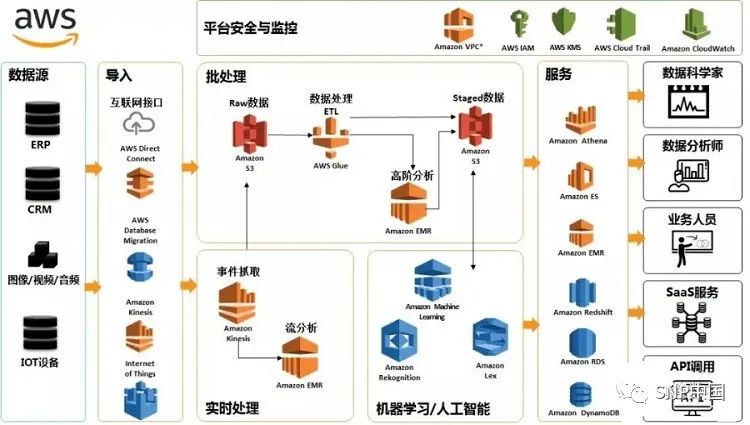
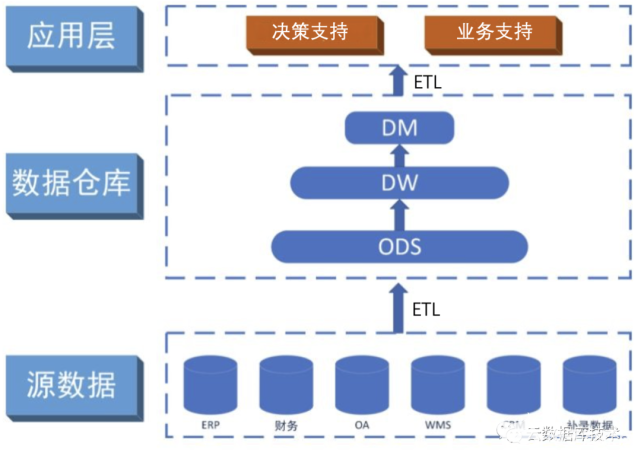
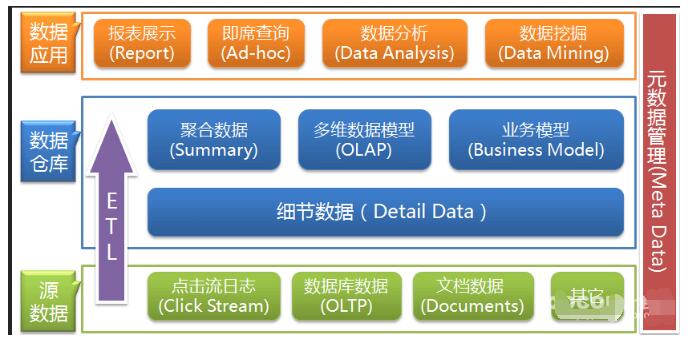
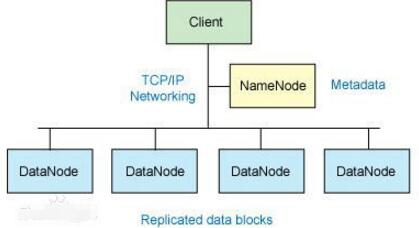
图1是一个典型的数据仓库架构。

它包括一些工具。这些工具可以用来从多种操作数据库和外部源中提取数据,并清洗、转换和整合这些数据,然后把数据加载到数据仓库;定期刷新仓库来更新的源和清除仓库的数据,或者是慢归档存储。除了主仓库,可能会有好几个部门数据集市。存储在数据仓库和数据集市的数据,由一个或多个仓库服务器管理,并呈现数据的多维视图给不同的前端工具,如:查询工具、报告作者、分析工具和数据挖掘工具。最后,还有一个存储库,用于存储和管理元数据,并为监测和管理仓储系统。
仓库可能被设计成分布式,以来得到负载均衡,可伸缩性和高可用性。在这样一个分布式体系结构,元数据存储库通常是在每个节点的仓库都进行备份的,整个仓库集中管理的。另一个体系结构,是仓库或数据集市的联合,每个仓库或者数据集市都有自己的贮存和分级管理。该设计实现力求使用方便,所以可能花费过于昂贵的代价来构造一个逻辑集成的企业仓库。
设计和推出一个数据仓库是一个复杂的过程,包括以下活动:
定义体系结构,容量规划,并选择存储服务器、数据库和OLAP服务器和工具。
整合服务器、存储和客户端工具。
设计仓库表和视图。
定义物理仓库组织,数据布局、分区和访问方法。
使用网关、ODBC驱动程序,或其他的包装器连接数据源,。
设计和实现数据提取、清洗、转换、加载和刷新的脚本。
贮存表和视图的定义、脚本和其他元数据。
设计和实现终端用户应用程序。
推出仓库和应用程序。
3. 后端工具和实用程序
数据仓库系统使用各种数据提取和清洗工具,录入仓库的加载和更新的实用程序。通常外来源的数据提取的实现需要通过网关和标准接口(如Information Builders EDA/SQL, ODBC, Oracle Open Connect, Sybase Enterprise Connect, Informix Enterprise Gateway)。
数据清洗
由于数据仓库是用于决策,数据仓库中的数据正确性的非常重要的。然而,因为大量的数据来自多个参与的数据源,数据中出现错误和异常的概率很高。因此,帮助检测数据的异常和对其改正的工具,可以带来很高高效益。在一些情况下,数据清洗显得非常有必要:字段长度不一致,不一致的描述,不一致的价值分配,缺失的条目和违背完整性约束。可想而知,数据录入表中的可选字段是不一致数据的重要来源。
有三个相关,但不同的类数据清理工具。数据迁移工具可以制定简单转换规则,例如,用性别种类来替换性别字符串。Prism的Warehouse Manager是这种类型的工具中比较流行的一个。数据清理工具使用特定领域的知识(如邮政地址)来对数据进行清理。他们经常利用解析和模糊匹配技术来完成来着多个源的清洗。一些工具可以指定源的“相对清洗”。 Integrity和Trillum等工具属于此类。数据审计工具可以通过扫描数据从而发现规则和关系(或提醒违背了规定的规则)。因此,这样的工具可以认为是数据挖掘工具的变体。这样的工具可能会发现一个可疑的样本(基于统计分析),例如,某汽车经销商从未收到任何投诉。
加载
提取、清洗和转换后,数据必须被加载到仓库。额外的预处理可能仍然被需要:检查完整性约束;排序;通过总结、聚合和其他计算来建立存储在仓库中的派生表;创建目录和其他访问路径;分区实现多个目标存储区域。通常情况下,批量装载工具可以用来做这件事。除了填充仓库,一个负载工具必须允许系统管理员监控状态,取消、挂起和恢复一个负载,失败后重启而没有损失数据的完整性。
数据仓库的加载工具必须处理比操作数据库更大规模的数据量。只有一个小时间窗口中(通常在晚上),仓库可以离线刷新它。连续加载会花费很长的时间,例如。,可以加载TB级的数据会花几周和几个月时间!因此,通常需要利用管线式和分区式的并行性。进行一个满载的优势在于它可以被视为一个长的批处理事务,来建立一个新的数据库。虽然在运行中,但是当前数据库仍然可以支持查询;当负载事务提交时,当前数据库被新的数据库所取代。使用周期检查点保证,如果加载过程中发生了失败,这个进程可以从上个检查点重启。
然而,即使使用并行性,一个满载可能仍然需要太长的时间。大多数商业工具(如,RedBrick Table Management Utility)在刷新过程中使用增量加载,来降低必须被纳入仓库的数据规模。只插入更新的元组。然而,这样的加载过程更加难以管理了。增量加载会与正在进行的查询起冲突,所以它被作为一个短事务(定期提交,如,每隔1000个记录或每隔几秒),但这样一来这个事务的序列必须被设计,来确保导出数据与基础数据的索引的一致性。






















 工商网监
工商网监
评论