 电子发烧友App
电子发烧友App


Python是一种面向对象的解释型计算机程序设计语言,由荷兰人发明,第一个公开发行版发行于1991年。Python是纯粹的自由软件,源代码和解释器CPython遵循 GPL协议。Python语法简洁清晰,特色之一是强制用空白符作为语句缩进。
Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
Python ascii 编码转化为utf-8编码
实现代码如下:
123456a = ‘abce’
# print type(a)
b = a.decode(“ascii”)
# print type(b)
c = a.decode(“ascii”).encode(“utf-8”)
# print type(c)
在python中进行编码转换都是通过unicode作为中间值实现的。所以要先decode成unicode字符,然后再使用encode转换成utf-8编码的str。可以把注释取消了,看下转换过程中的类型。
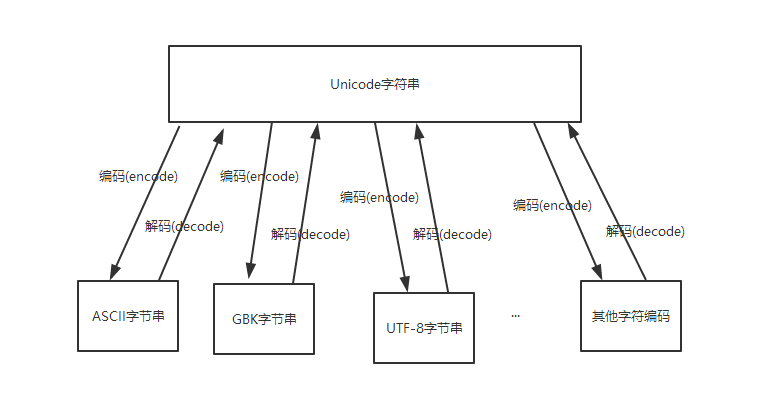
ASCII 是一种字符集,包括大小写的英文字母、数字、控制字符等,它用一个字节表示,范围是 0-127 Unicode分为UTF-8和UTF-16。
UTF-8变长度的,最多 6 个字节,小于 127 的字符用一个字节表示,与 ASCII 字符集的结果一样,ASCII 编码下的英语文本不需要修改就可以当作 UTF-8 编码进行处理。
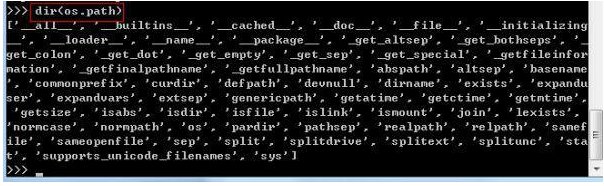
Python 从 2.2 开始支持 Unicode ,函数 decode( char_set )可以实现 其它编码到 Unicode 的转换,函数 encode( char_set )实现 Unicode 到其它编码方式的转换。
比如
[python] view plain copy(“你好”).decode( “GB2312”)
将得到
u‘\u4f60\u597d’,
即 “你”和“好“的 Unicode 码分别是 0x4f60 和 0x597d
再用
[python] view plain copy(u‘\u4f60\u597d’).encode(”UTF-8“)
将得到
‘\xe4\xbd\xa0\xe5\xa5\xbd’
它是 “你好”的UTF-8编码结果。
python中使用 unicode的关键:unicode是一个类,函数unicode(str,”utf8“)从utf8编码(当然也可以是别的编码)的字符串str生成 unicode类的对象,而函数unc.encode(”utf8“)将unicode类的对象unc转换为(编码为)utf8编码(当然也可以是别的编码)的字符串。于是,编写unicode相关程序,需要做的事情是 * 获取数据(字符串)时,用unicode(str, ”utf8“)生成unicode对象 * 在程序中仅使用unicode对象,对程序中出现的字符串常量都以u”字符串“的形式书写 * 输出时,可将unicode对象转换为任意编码输出,使用str.encode(”some_encoding“)
[python] view plain copy》》》 unicode(”你好“, ”utf8“)
u‘\u4f60\u597d’
》》》 x = _
》》》 type(x)
》》》 type(”你好“)
》》》 x.encode(”utf8“)
‘\xe4\xbd\xa0\xe5\xa5\xbd’
》》》 x.encode(”gbk“)
‘\xc4\xe3\xba\xc3’
》》》 x.encode(”gb2312“)
‘\xc4\xe3\xba\xc3’
》》》 print x
你好
》》》 print x.encode(”utf8“)
你好
》》》 print x.encode(”gbk“)
???
以上是测试结果(Ubuntu 6.06,locale为utf8),注意type(x)和type(”你好“)的区别。从编码上可以看出utf8编码与gbk不同。在utf8的 locale设置下,打印x按该环境变量编码(我猜我猜我猜猜猜),而打印x.encode(”gbk“)则是乱码。
python编码乱码问题ascii unicode utf-8
基础知识部分
首先需明白python2.7默认使用的是ascii,而现在python3.x默认使用的是unicode。下面内容基于python2.7。
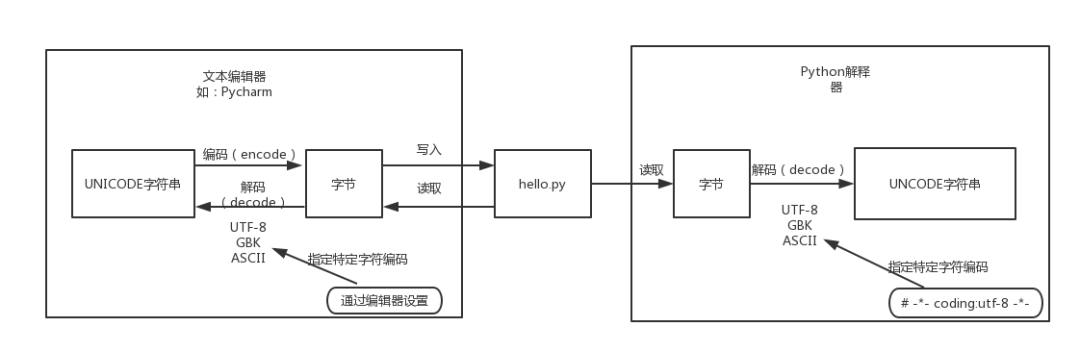
一、文件编码
一般文件使用的是utf-8或者bgk编码进行存储。但是由于python2.7默认使用ascii,所以python2.7在运行py后缀文件时也是默认以ascii编码读取文件。如果文件中没有中文不会出现问题。但是如果有中文的话,由于中文编码超出了ascii编码范围,所以python2.7将会报错。
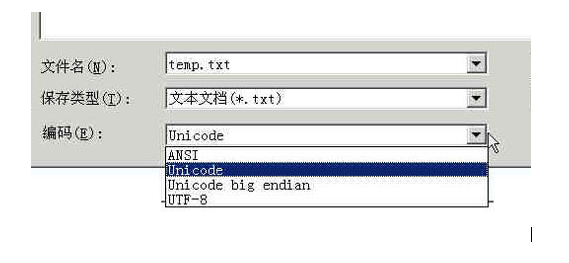
所以我们需要在文件头部添加:
#coding:utf-8
或者
#!/usr/bin/python
# -*- coding: utf-8 -*-1234
来告诉python2.7此文件要用utf-8编码来读取。
在文件中设置后我们可以使用 a = u‘哈’;python会自动使用utf-8来读取汉字,并将其转换为Unicode对象。1
二、字符串编码
python2.7和字符串相关的数据类型,分别是标准字符串(str)是单字节字符序列,Unicode字符串(unicode)是双字节字符序列。。
python的解码,编码是python自动进行的,如果我们没有指明解码方式,python 就会使用 sys.defaultencoding 指明的方式来解码。python2.7的函数str()和unicode()默认将对象转成ascii编码。
但是对于中文,ascii编码是无法表示的。因此我们需要用sys.setdefaultencoding(‘utf-8’)来设置string对象默认的编码。
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’) 123
那么字符串如何在str和unicode间进行转换呢?python提供了两个函数:
b = u‘哈’ //b为unicode对象
b.encode(‘utf-8’) //将b从unicode类型转为utf-8类型
b.decode(‘utf-8’) //将b从utf-8类型转换为Unicode类型123
三、window控制台输出
window控制台默认使用gbk编码。如果你设置了
# -*- coding: utf-8 -*-1
python直接按照utf-8输出到控制台。所以我们可以改变文件编码:
# -*- coding: gbk -*-1
或者使用unicode类型进行输出,会自动转换。












 工商网监
工商网监
评论