【RT-Thread学习笔记】一种C语言宏定义的写法
2022-07-30 13:41:04 1882
1882 
C语言允许定义参数数量可变的函数,这称为可变参数函数(variadic function)。这种函数需要固定数量的强制参数(mandatory argument),后面是数量可变的可选参数(optional argument)。
2022-08-18 21:40:17995 如何使用C语言的宏定义转换字符串?
2022-08-29 08:51:067086 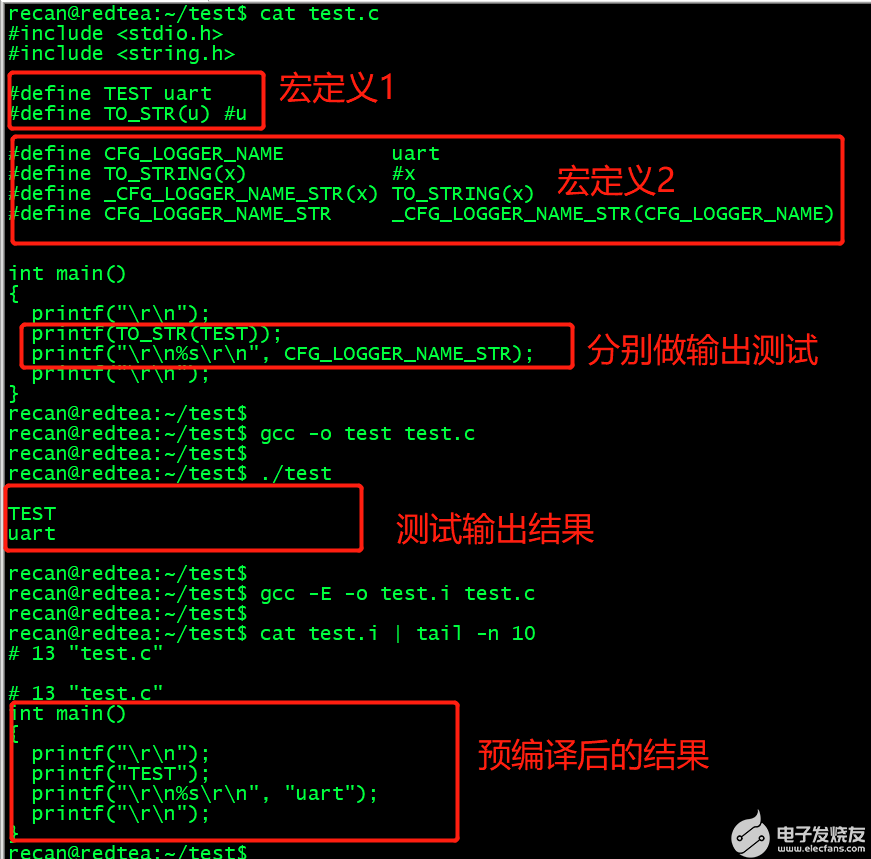
单片机开发或多或少都会接触一些汇编代码,今天就来说说关于汇编在C中的定义和调用,以及举例说明嵌套汇编代码。
2022-08-29 14:07:141136 今天分享一个C语言宏定义小技巧,从语法上来看比较简单,不过一旦真正领悟到其精妙之处不仅可以简化代码、还能提高代码的可扩展性。
2022-09-07 09:36:50476 定义的标识符不占内存,只是一个临时的符号,预编译后这个符号就不存在了。在简单的程序使用带参数的宏定义可完成函数调用的功能,又能减少系统开销,提高运行效率。正如C语言中所讲,函数的使用可以使程序更加模块化,便于组织,而且可重复利用。
2022-10-11 17:34:30994 近日在某一技术群又水群时某一群友将这个称之为“常量”,事实上在C语言中#define 正确的叫法叫做“宏定义”属于预处理指令中的一种,在C语言中应用极其广泛。
2023-10-01 13:28:00317 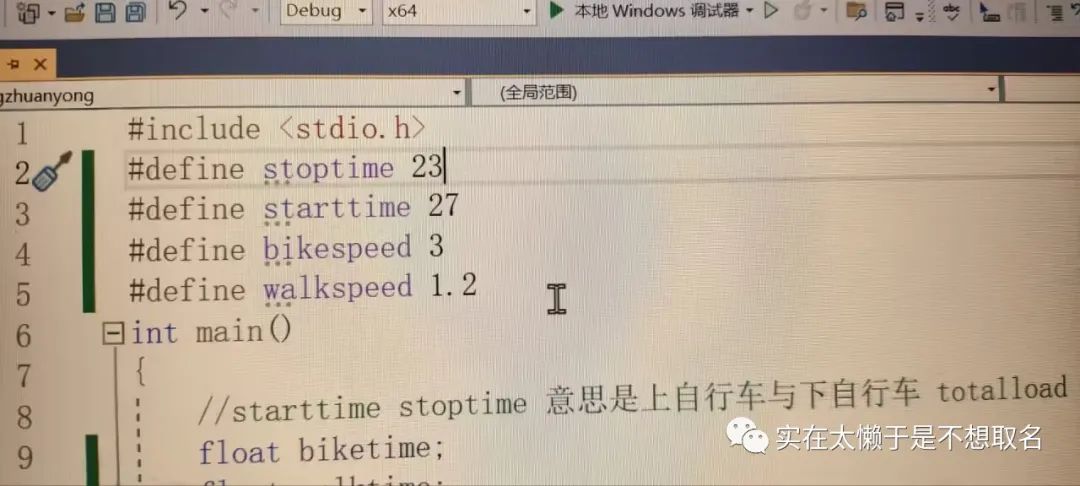
你好: 使用C6748芯片进行网口Lan8710配置,参考例程startware\driver中的mdio.c;在第51行处:下面的宏定义分别代表什么意思?在手册哪可以找到这些介绍
2020-07-30 17:37:23
我感觉还可以
2012-11-19 20:33:12
本文由dongeasy收集整理,原文链接:http://www.dongeasy.com/software-development/embedded-system/2013.html在宏定义中
2016-08-23 18:22:44
C语言宏定义使用do{}while(0)的好处1. 概述经常写项目代码,有时需要用到宏定义,而宏定义的用法是否标准,则是会影响到是否能快速查错以及代码拓展性的问题。在宏定义的用法上大家为什么都推荐用
2022-02-25 06:28:18
C语言宏定义技巧
2015-03-01 21:58:22
题目描述请编写“#define SQR(x) …”,实现计算x的平方。#include /******************************************//// Write your code here,/// beginning with “#define”…/*********************************...
2021-07-14 07:25:20
请问,C语言中定义全局变量时,如何在定义变量时就指定好变量的地址?
2023-11-03 06:31:09
到C语言的可变参数的定义。//可变参数用...来表示void TRACE(char *format, ...)(2)可变参数函数需要用到的宏需要include的文件stdarg.hva_list: 指针类型的宏,指向参数列表的参数void va_start(va_list arg
2021-07-14 07:43:15
C语言中怎么定义一个不定长度的数组
2023-10-09 07:40:02
宏定义是我们C语言学习中非常重要的内容。一些基础的用法大家都比较清楚了,我们简单总结一下。1.宏定义的格式为:#define 标识符 字符串。2.宏定义属于预处理命令,在编译过程中的预处理阶段处理
2016-12-13 15:32:12
第五章 性能优化5.1 使用宏定义 在C语言中,宏是产生内嵌代码的唯一方法。对于嵌入式系统而言,为了能达到性能要求,宏是一种很好的代替函数的方法。 写一个"标准"宏MIN ,这个宏输入两个参数并返回较小的一个: 错误做法:#define MIN(A,B) ( A
2021-12-15 08:20:14
编译预处理器是C语言编译器的一个重要组成部分。很好的利用C语言的预处理命令可以增强代码的可读性,灵活性,和易于修改等特点,便于程序的结构化。预处理命令由符号“#”开头,包括宏定义,文件包含,条件处理
2017-06-03 17:23:43
C语言复习:一、位操作:6种操作运算符二、define宏定义关键词define是C语言中的预处理命令,它用于宏定义,可以提高源代码的可读性,为编程提供方便。常见的格式:define标识符字符串
2022-02-25 06:00:57
说明:这里以GPIO外设为例,介绍C语言对寄存器的封装。以此类推其他外设同样可以用这种方法来封装。本文有两部分构成:1、介绍宏定义。2、使用结构体封装寄存器列表。1、宏定义以封装STM32
2022-01-05 06:34:24
C语言常用宏定义技巧
2012-07-26 12:47:37
那么该如何修改呢?不希望写成函数形式的,写成宏定义形式的比较好。
2018-12-26 08:51:20
指令表:注意:宏名的书写由标识符与两边各两条下划线构成。C语言基本数据类型不同操作系统中数据类型所占字节数图解数据类型的其他分类:变量常量(字面量和const常量)void(特殊类型)数组(构造类型)枚举类型(自定义类型)结构体、位域和共用体(构造类型)C语言存储管理当一个
2021-12-21 08:29:23
#define A(x) x;x;x;x;x;x;x;x;x;x;我明白这个可以起到控制的作用也就是宏调用10次;但不太明白其中意思,话说宏中不用分号 ,这个宏函数,需求详细解说
2013-10-09 15:42:18
c语言中常用的宏定义有哪些?
2021-04-28 06:01:10
在用c语言写代码是大家是怎样组织文件的?一般都是一个.c配一个.h文件,并且.c中放函数和变量定义,.h中放宏定义和函数的声明。我想问一下.h中应该放那些宏定义和函数的声明呢?是将.c中用到的所有宏定义和函数声明都放在.h中呢?还是只把对外的接口放在.h中呢?而且大家是如何避免宏的重复定义的呢?
2020-06-05 03:20:02
各位,请问一下,这个宏定义代表什么意思?#define OUTPUT_WAVE(pointer, d)PORTC = pointer[d*N_PORTS + 0] 谢谢
2018-03-12 10:30:12
ARM C语言扩展(ACLE)规范指定源语言扩展和实现C/C++编译器可以实现的选项,以便让程序员更好地利用ARM体系结构。
扩展包括:
提供关于目标体系结构的功能的信息的预定义宏(例如,是否
2023-08-02 06:27:41
用CCS5.2调试controlsuite里的程序时,选择单步调试,在C语言环境下,当遇上子函数时点step into 可以进入,当遇到宏定义时选step into 无法进入,而在对应的汇编窗口
2018-10-29 11:47:02
LED流水灯C语言常用预处理命令 宏定义#define使用:#define 新名称 原内容(不加分号)//对同一个内容,宏定义只能定义一次循环左移和右移函数,包含在instrins.h库函数里边
2022-01-19 06:53:32
如题,labview中有类似于c语言中的宏定义吗 define xxx XXX。。。多谢~
2016-10-05 15:04:39
)颜色。SCROLLBAR_COLOR0_DEFAUL 0xc0c0c0箭头按钮的颜色。SCROLLBAR_USE_3D1启用 3D 支持。如图,类似这些宏定义要在哪里定义啊?是guiconf.h吗?
2020-05-01 04:36:03
在单片机开发中,总有一些C语言基础知识是常常用到的而我们又不易掌握的,今天以STM32单片机为例,总结一下那些常用的C语言基础知识,例如逻辑运算符,结构体,宏定义以及按位运算符。逻辑运算符逻辑运算
2021-07-21 08:28:20
目录前言一、C语言预处理二、宏定义三、函数四、函数库五、自己制作静态链接库(ubuntu 环境下,即使用Linux系统平台上的gcc)六、自己制作动态链接库(ubuntu 环境下,即使用Linux
2022-02-11 06:35:36
,而后者只进行字符替换,没有类型安全检查,并且在字符替换中可能会产生意料不到的错误。有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试。在c++语言中只使用const常量而不使用宏常量,及const可以完全替代宏、
2016-05-06 22:25:33
Protothreads是一种针对C语言封装后的宏函数库,为C语言模拟了一种无堆栈的轻量线程环境,能够实现模拟线程的条件阻塞、信号量操作等操作系统中特有的机制,从而使程序实现多线程操作。每个
2015-10-31 11:13:25
·常见关键字·define 定义常量和宏·指针·结构体正文开始什么是C语言?C语言是一门通用计算机编程语言,广泛应用于底层开发。C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。尽管C语言提供了许多低...
2021-07-01 06:49:06
定义位可以用***it但是定义字节呢?还有就是比如汇编中的DPTR的DPH和DPL在c语言中怎样定义的呢?
2012-02-23 14:50:57
飞了可不是说着玩,当然,这里可以在RAM开辟一个寄存器来用,那就没事了。喜欢的自己改)2 第二部就是定义一些宏的具体数值了(跟C类似)TCCA_ENABLE == 0X04TCCA_DISABLE
2016-10-10 19:27:05
假设我可以在“XC32(全局选项)”的面板上定义宏,比如Project Properties对话框中的配置名称。但我不在面板右侧看到“预处理器宏定义”行。我确实看到xc32-as有这样的选项,但是我
2019-10-15 15:39:03
Read_SP37_ID(unsigned char idata *IDH,unsigned char idata *IDL){*IDH = CBYTE[0x57E0];*IDL = CBYTE[0x57E1];}一.使用C51运行库中预定义宏C51编译器提供了一组宏定义来对51系列单片机的cod
2021-12-02 07:55:42
工程目标:实现按键长按,短按,双击,单机调用不同的回调函数,执行不同的命令。宏定义:#define TRIGGER_CB(event)\if(btn->CallBack_Function
2022-01-05 06:58:20
想通过宏定义来实现,如下面格式#define link(arg) RCC_APB2Periph_##arg返回的结果为RCC_APB2Periph_GPIOC,以方便在时钟使能函数中使用请教该怎么实现——来自宏定义小白
2018-04-20 23:33:11
碰到一个问题:需要根据一个参数的值来使用不同的宏定义,但是之前好像没见过if(xxx == x){#define xxxx}这种语句,有没有哪位大神有好的办法实现这个功能呢
2019-10-08 09:30:03
C语言内宏定义是被预编译器处理还是被编译器处理
2020-03-20 04:35:49
,"ramfuncs");#pragma CODE_SECTION(OffsetISR,"ramfuncs");#endif但是这个FLASH 的宏定义不知在哪里进行
2018-06-11 07:42:39
写好C语言,漂亮的宏定义很重要,使用宏定义可以防止出错,提高可移植性,可读性,方便性 等等。下面列举一些成熟软件中常用得宏定义……
1,防止一个头文件被重复
2010-11-13 12:04:34 36
36 本章讲述Verilog HDL指定用户定义原语UDP的能力。UDP的实例语句与基本门的实例语句完全相同,即U D P实例语句的语法与基本门的实例语句语法一致。verilog相关教程材料,有兴趣的同学可以下载学习。
2016-04-25 16:09:3212 深入学习c语言的发烧友可以看看,当然有兴趣的入门者也可以看
2016-05-13 11:28:050 以使用Kernighan和里奇(以下简称K&R)作为本手册的补充。在本手册中引用K&R C(与ISO C相反)指的是C语言中定义的C语言和里奇的C语言。
2018-05-08 09:26:3220 一:C51(单片机C语言)与标准C语言的区别1、 C51语言中定义的库函数与标准c语言中定义的库函数不同。2、 C51语言中的数据类型和标准c语言中的数据类型有一定的区别。3、 C51变量中的存储
2018-10-09 08:00:00134 本文档的主要内容详细介绍的是数据库原理与实践教程之SQL语言基础及数据定义功能内容包括了:1.基本概念2. SQL的数据类型 3数据定义功能
2018-10-19 17:18:156 本章主要介绍了T-SQL语言的数据定义、数据操纵和数据控制功能,介绍了视图、存储过程和触发器,介绍批、脚本、局部变量、全局变量的概念,重点介绍了流程控制语句和游标的使用方法。本章重点要求掌握T-SQL语言的查询和更新功能,灵活掌握视图的作用和用法,掌握流程控制语句和游标的使用方法。
2018-11-28 19:44:1115 如果在两年前,它是一个新的“X Server”,在于改善当前X Server的不足,从而取代它。现在,我们已经可以用更标准的语言来定义Wayland了,那就是:A Simple Display Server。
2019-04-23 15:41:032408 
在计机领域,堆栈是一个不容忽视的概念,我们编写的C语言程序基本上都要用到。但对于很多的初学着来说,堆栈是一个很模糊的概念。堆栈:一种数据结构、一个在程序运行时用于存放的地方,这可能是很多初学者
2019-08-16 17:32:000 在定义格式中除了数据类型和变量名表是必要的,其它都是可选项。存储种类有四种:自动(auto),外部(extern),静态(static)和寄存器(register),缺省类型为自动(auto)。
2019-07-31 17:35:000 描述C。您可以使用Kernighan和Ritchie(以下简称K&R)手册作为本手册的补充。本手册中提及K&R C(而非ISO C)是指第一版Kernighan和Ritchie的C编程语言中定义的C语言。
2019-05-15 08:00:009 Verilog HDL语言不仅定义了语法,而且对每个语法结构都定义了清晰的模拟、仿真语义。因此,用这种语言编写的模型能够使用Verilog仿真器进行验证。语言从C编程语言中继承了多种操作符和结构。
2019-09-27 07:09:001518 
Verilog HDL语言不仅定义了语法,而且对每个语法结构都定义了清晰的模拟、仿真语义。因此,用这种语言编写的模型能够使用Verilog仿真器进行验证。语言从C编程语言中继承了多种操作符和结构
2019-09-19 07:06:001868 
实验目的和要求(1)掌握C语言函数的定义方法、函数的声明及函数的调用方法。(2)掌握函数实参和形参的对应关系以及“值传递”的方式。(3)掌握函数嵌套调用和递归调用的方法。(4)掌握全局变量和局部变量、动态变量和静态变量的定义、说明和使用方法。
2019-12-06 08:00:004 当宏作为常量使用时,C程序员习惯在名字中只使用大写字母。但是并没有如何将用于其他目的的宏大写的统一做法。由于宏(特别是带参数的宏)可能是程序中错误的来源,所以一些程序员更喜欢使用大写字母来引起注意。
2020-07-02 15:04:201246 本文档的主要内容详细介绍的是C语言的声明和定义与引用说明
2020-07-29 08:00:002 结构体、联合体是C语言中的构造类型,结构体我们平时应该都用得很多。但是,对于联合体,一些初学的朋友可能用得并不多,甚至感到陌生。我们先简单看一下联合体: 在C语言中定义联合体的关键字是union
2020-12-24 16:07:485149 
的重要因素之一,这不仅由于系统内存是有限的(尤其在嵌入式系统中),而且内存分配也会直接影响到程序的效率。因此,我们要对C语言中的内存管理,有个系统的了解。 在C语言中,定义了4个内存区间:代码区;全局变量和静态变
2021-02-20 14:25:071300 
电子发烧友网为你提供堆栈在C语言中的定义(单片机的中堆栈相当于栈)资料下载的电子资料下载,更有其他相关的电路图、源代码、课件教程、中文资料、英文资料、参考设计、用户指南、解决方案等资料,希望可以帮助到广大的电子工程师们。
2021-04-16 08:45:2014 C语言中的特殊数据类型包含:结构体、枚举、公用体(联合)、数组、指针。特殊数据类型的定义与变量定义相类似。C语言是强类型语言必须先定义后使用。下面演示变量及数据类定义及使用:变量与常量的定义 变量
2021-11-21 09:06:057 C51 语言的变量定义定义方式:普通变量:(修饰符)数据类型 [存储类型] 变量名 [= 值]指针变量: (修饰符)所指向的地址的数据类型 [所指向的地址的存储类型] *[指针的存储类型] 变量名
2021-11-23 16:51:233 目录前言一、C语言预处理二、宏定义三、函数四、函数库五、自己制作静态链接库(ubuntu 环境下,即使用Linux系统平台上的gcc)六、自己制作动态链接库(ubuntu 环境下,即使用Linux
2021-12-07 21:06:072 在单片机中断中可以使用宏定义代替函数,减小系统运行时间。1.带参数宏定义的优点:用带参数宏代替函数可以在中断中可以节省更多的运行时间,不至于中断时间过长造成其他的处理程序无法正常运行。宏展开不占
2022-01-13 12:52:136 二进制和十进制二进制十进制011021131004101511061117100081001910101011111111255十六进制和十进制十六进制十进制十六进制十进制00B1111C1222D1333E1444F15551016661117771218881319
2022-01-13 12:55:141 C语言宏定义使用do{}while(0)的好处1. 概述 经常写项目代码,有时需要用到宏定义,而宏定义的用法是否标准,则是会影响到是否能快速查错以及代码拓展性的问题。在宏定义的用法上大家
2022-01-13 13:06:182 调试单片机常用,参考正点原子USMART写了个简单的自用核心内容如下1、C语言(stm32)定义typedef struct ShellFun_CLASS{ void* func; //函数
2022-01-13 13:25:221 不管在什么语言中,定义一个变量时必然要在内存中开辟一个相应大小的空间来存储该变量。不同的数据类型在内存所占的空间大小不同,其所能表示的数据范围也不相同。在单片机C语言中,常用的基本数据类型分为四类
2022-01-13 15:05:461 C语言里函数是非常重要的知识点,一个完整的C语言程序就是由主函数和各个子函数组成的,主函数调用子函数完成各个逻辑功能。 这篇文章作为C语言函数知识点的第一章,介绍函数定义、声明、传参、变量的作用域、返回值、调用方法等知识点。
2022-08-14 09:57:481560 存放CPU执行的机器指令。通常,代码区是可共享的(即另外的执行程序可以调用它),因为对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指令。另外,代码区还规划了局部变量的相关信息。
2022-10-19 15:43:21688 ,在单个封装中具有多个芯片,无法通过边界扫描描述语言(BSDL)定义板级JTAG测试。应用笔记包含外部引脚映射表、内部芯片焊盘键合表和联系信息,因此设计人员可以快速实现精确的JTAG边界扫描板测试。
2023-01-09 20:18:21713 使用STM32开发的朋友不知道是否有发现过这样的一些宏定义?
2023-02-01 14:36:261196 C语言中定义字符串有哪些方法?
2023-03-31 09:41:492722 UML-Unified Modeling Language 统一建模语言,又称标准建模语言。是用来对软件密集系统进行可视化建模的一种语言。UML的定义包括UML语义和UML表示法两个元素。
2023-05-05 10:15:59543 
在 Linux 内核中,经常会看到do{} while(0)这样的语句,许多人开始都会疑惑,认为do{} while(0)毫无意义,因为它只会执行一次,加不加do{} while(0)效果是完全一样的,其实do {}while(0)的用法主要用于宏定义中。
2023-06-11 10:59:29442 宏定义会在编译的时候进行替换展开。最好将宏中的参数用括号括起来。这样就避免了当一个表达式同时含有宏定义和其他高优先级运算符时,破坏整个表达式的运算顺序 。
2023-07-31 09:39:33468 c语言宏定义可以嵌套吗? C语言宏定义可以嵌套,也就是一个宏定义可以包含另一个宏定义,这也被称为宏定义的嵌套扩展。 宏定义是C语言中一种很重要的语法结构,它类似于一种预处理指令,用于在程序编译之前
2023-09-04 17:38:322399 c语言带参数的宏定义 C语言宏定义是一种宏替换机制,它可以将一个标识符替换为一个代码片段。宏定义通常在程序中用来方便地进行常量定义或函数模板定义。在C语言中,宏定义有以下几种类型: 1. 简单
2023-09-04 17:45:181514 写好C语言,使用宏定义可以防止出错,提高可移植性、可读性等。下文列举一些成熟软件中常用的宏定义。
2023-10-07 10:54:49184 
C语言中,数组是一种用来存储相同类型元素的数据结构。它可以存储多个元素,并通过一个共同的名称来引用这些元素。数组是一种很重要的数据结构,可以用于解决很多实际的问题。 在C语言中,定义数组的语法如下
2023-11-24 10:11:20577 在科技飞速发展的当今时代,人工智能技术成为社会进步的关键推动力之一。在广泛关注的人工智能领域中,大语言模型以其引人注目的特性备受瞩目。 大语言模型的定义及发展历史 大语言模型是一类基于深度学习技术
2023-12-21 17:53:59551
正在加载...
 电子发烧友App
电子发烧友App












 工商网监
工商网监
评论