 电子发烧友App
电子发烧友App


作者 | Deepu K Sasidharan 译者 | 张卫滨
本文最初发表于 okta 网站,经原作者 Deepu K Sasidharan 授权由 InfoQ 中文站翻译分享,未经许可禁止转载。
Java 19 已经于日前发布,其中最引人注目的特性就要数虚拟线程了,本文介绍了 Loom 项目中虚拟线程和结构化编程的基础知识,并将其与操作系统线程进行了对比分析。
Java 在其发展早期就具有良好的多线程和并发能力,能够高效地利用多线程和多核 CPU。Java 开发工具包(Java Development Kit,JDK)1.1 对平台线程(或操作系统(OS)线程)提供了基本的支持,JDK 1.5 提供了更多的实用工具和更新,以改善并发和多线程。JDK 8 带来了异步编程支持和更多的并发改善。虽然在多个不同的版本中都进行了改进,但在过去三十多年中,除了基于操作系统的并发和多线程支持之外,Java 并没有任何突破性的进展。
尽管 Java 中的并发模型非常强大和灵活,但它并不是最易于使用的,而且开发人员的体验也不是很好。这主要是因为它默认使用的共享状态并发模型。我们必须借助同步线程来避免数据竞争(data race)和线程阻塞这样的问题。我曾经在一篇名为“现代编程语言中的并发:Java”的博客文章中讨论过 Java 并发问题。
1Loom 项目是什么?
Loom 项目致力于大幅减少编写、维护和观察高吞吐量并发应用相关的工作,以最佳的方式利用现有的硬件。
——Ron Pressler(Loom 项目的技术负责人)
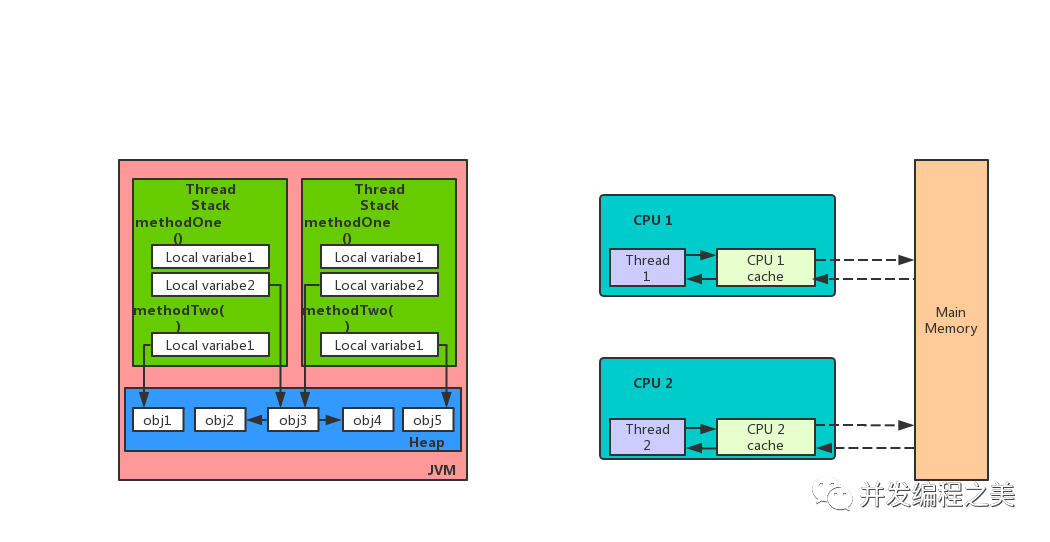
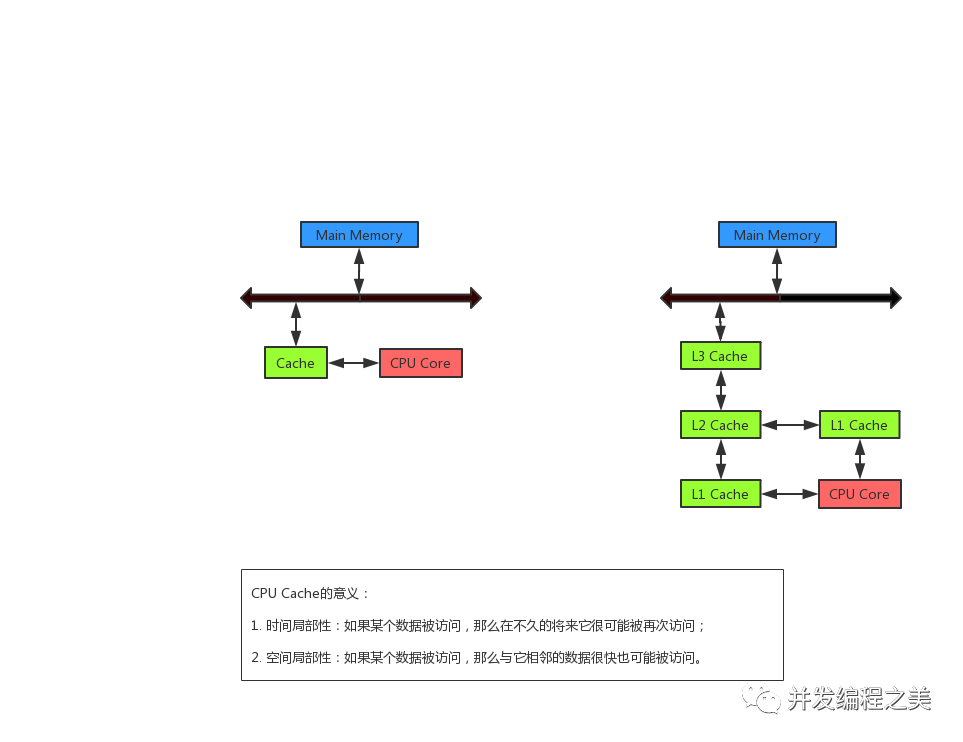
操作系统线程是 Java 并发模型的核心,围绕它们有一个非常成熟的生态系统,但是它们也有一些缺点,如计算方式很昂贵。我们来看一下并发的两个最常见使用场景,以及当前的 Java 并发模型在这些场景下的缺点。
最常见的并发使用场景之一就是借助服务器在网络上为请求提供服务。在这样的场景中,首选的方法是“每个请求一个线程(thread-per-request)”模型,即由一个单独的线程处理每个请求。这种系统的吞吐量可以用 Little 定律来计算,该定律指出,在一个稳定的系统中,平均并发量(服务器并发处理的请求数)L 等于吞吐量(请求的平均速率)λ乘以延迟(处理每个请求的平均时间)W。基于此,我们可以得出,吞吐量等于平均并发除以延迟(λ = L/W)。
因此,在“每个请求一个线程”模型中,吞吐量将受到操作系统线程数量的限制,这取决于硬件上可用的物理核心 / 线程数。为了解决这个问题,我们必须使用共享线程池或异步并发,这两种方法各有缺点。线程池有很多限制,如线程泄漏、死锁、资源激增等。异步并发意味着必须要适应更复杂的编程风格,并谨慎处理数据竞争。它们还有可能出现内存泄漏、线程锁定等问题。
另一个常见的使用场景是并行处理或多线程,我们可能会把一个任务分成跨多个线程的子任务。此时,我们必须编写避免数据损坏和数据竞争的解决方案。在有些情况下,当执行分布在多个线程上的并行任务时,还必须要确保线程同步。这种实现会非常脆弱,并且将大量的责任推给了开发人员,以确保没有像线程泄露和取消延迟这样的问题。
Loom 项目旨在通过引入两个新特性来解决当前并发模型中的这些问题,即虚拟线程(virtual thread)和结构化并发(structured concurrency)。
2虚拟线程
Java 19 已经于 2022 年 9 月 20 日发布,虚拟线程是其中的一项预览功能。
虚拟线程是轻量级的线程,它们不与操作系统线程绑定,而是由 JVM 来管理。它们适用于“每个请求一个线程”的编程风格,同时没有操作系统线程的限制。我们能够创建数以百万计的虚拟线程而不会影响吞吐。这与 Go 编程语言(Golang)的协程(如 goroutines)非常相似。
Java 19 中的虚拟线程新特性很易于使用。在这里,我将其与 Golang 的 goroutines 以及 Kotlin 的 coroutines 进行了对比。
虚拟线程
Thread.startVirtualThread(() -> {
System.out.println("Hello, Project Loom!");
});
Goroutine
go func() {
println("Hello, Goroutines!")
}()
Kotlin coroutine
runBlocking {
launch {
println("Hello, Kotlin coroutines!")
}
}
冷知识:在 JDK 1.1 之前,Java 曾经支持过绿色线程(又称虚拟线程),但该功能在 JDK 1.1 中移除了,因为当时该实现并没有比平台线程更好。
虚拟线程的新实现是在 JVM 中完成的,它将多个虚拟线程映射为一个或多个操作系统线程,开发人员可以按需使用虚拟线程或平台线程。这种虚拟线程实现还有如下几个注意事项:
在代码、运行时、调试器和剖析器(profiler)中,它是一个 Thread。
它是一个 Java 实体,并不是对原生线程的封装。
创建和阻塞它们是代价低廉的操作。
它们不应该放到池中。
虚拟线程使用了一个基于任务窃取(work-stealing)的 ForkJoinPool 调度器。
可以将可插拔的调度器用于异步编程中。
虚拟线程会有自己的栈内存。
虚拟线程的 API 与平台线程非常相似,因此更容易使用或移植。
我们看几个展示虚拟线程威力的样例。
线程的总数量
首先,我们看一下在一台机器上可以创建多少个平台线程和虚拟线程。我的机器是英特尔酷睿 i9-11900H 处理器,8 个核心、16 个线程、64GB 内存,运行的操作系统是 Fedora 36。
平台线程
var counter = new AtomicInteger(); while (true) { new Thread(() -> { int count = counter.incrementAndGet(); System.out.println("Thread count = " + count); LockSupport.park(); }).start(); }
在我的机器上,在创建 32,539 个平台线程后代码就崩溃了。
虚拟线程
var counter = new AtomicInteger();
while (true) {
Thread.startVirtualThread(() -> {
int count = counter.incrementAndGet();
System.out.println("Thread count = " + count);
LockSupport.park();
});
}
在我的机器上,进程在创建 14,625,956 个虚拟线程后被挂起,但没有崩溃,随着内存逐渐可用,它一直在缓慢进行。你可能想知道为什么会出现这种情况。这是因为被 park 的虚拟线程会被垃圾回收,JVM 能够创建更多的虚拟线程并将其分配给底层的平台线程。
任务吞吐量
我们尝试使用平台线程来运行 100,000 个任务。
try (var executor = Executors.newThreadPerTaskExecutor(Executors.defaultThreadFactory())) { IntStream.range(0, 100_000).forEach(i -> executor.submit(() -> { Thread.sleep(Duration.ofSeconds(1)); System.out.println(i); return i; })); }
在这里,我们使用了带有默认线程工厂的 newThreadPerTaskExecutor 方法,因此使用了一个线程组。运行这段代码并计时,我得到了如下的结果。当使用 Executors.newCachedThreadPool() 线程池时,我得到了更好的性能。
# 'newThreadPerTaskExecutor' with 'defaultThreadFactory' 0:18.77 real, 18.15 s user, 7.19 s sys, 135% 3891pu, 0 amem, 743584 mmem # 'newCachedThreadPool' with 'defaultThreadFactory' 0:11.52 real, 13.21 s user, 4.91 s sys, 157% 6019pu, 0 amem, 2215972 mmem
看着还不错。现在,让我们用虚拟线程完成相同的任务。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 100_000).forEach(i -> executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(i);
return i;
}));
}
运行这段代码并计时,我得到了如下结果:
0:02.62 real, 6.83 s user, 1.46 s sys, 316% 14840pu, 0 amem, 350268 mmem
这比基于平台线程的线程池要好得多。当然,这些都是很简单的使用场景,线程池和虚拟线程的实现都可以进一步优化以获得更好的性能,但这不是这篇文章的重点。
用同样的代码运行 Java Microbenchmark Harness(JMH),得到的结果如下。可以看到,虚拟线程的性能比平台线程要好很多。
# Throughput Benchmark Mode Cnt Score Error Units LoomBenchmark.platformThreadPerTask thrpt 5 0.362 ± 0.079 ops/s LoomBenchmark.platformThreadPool thrpt 5 0.528 ± 0.067 ops/s LoomBenchmark.virtualThreadPerTask thrpt 5 1.843 ± 0.093 ops/s # Average time Benchmark Mode Cnt Score Error Units LoomBenchmark.platformThreadPerTask avgt 5 5.600 ± 0.768 s/op LoomBenchmark.platformThreadPool avgt 5 3.887 ± 0.717 s/op LoomBenchmark.virtualThreadPerTask avgt 5 1.098 ± 0.020 s/op
你可以在 GitHub 上找到该基准测试的源代码。如下是其他几个有价值的虚拟线程基准测试:
在 GitHub 上,Elliot Barlas 使用 ApacheBench 做的一个有趣的基准测试。
Alexander Zakusylo 在 Medium 上使用 Akka actors 的基准测试。
在 GitHub 上,Colin Cachia 做的 I/O 和非 I/O 任务的 JMH 基准测试。
3结构化并发
结构化并发是 Java 19 中的一个孵化功能。
结构化并发的目的是简化多线程和并行编程。它将在不同线程中运行的多个任务视为一个工作单元,简化了错误处理和任务取消,同时提高了可靠性和可观测性。这有助于避免线程泄漏和取消延迟等问题。作为一个孵化功能,在稳定过程中可能会经历进一步的变更。
我们考虑如下这个使用 java.util.concurrent.ExecutorService 的样例。
void handleOrder() throws ExecutionException, InterruptedException {
try (var esvc = new ScheduledThreadPoolExecutor(8)) {
Future inventory = esvc.submit(() -> updateInventory());
Future order = esvc.submit(() -> updateOrder());
int theInventory = inventory.get(); // Join updateInventory
int theOrder = order.get(); // Join updateOrder
System.out.println("Inventory " + theInventory + " updated for order " + theOrder);
}
}
我们希望 updateInventory() 和 updateOrder() 这两个子任务能够并发执行。每一个任务都可以独立地成功或失败。理想情况下,如果任何一个子任务失败,handleOrder() 方法都应该失败。然而,如果某个子任务发生失败的话,事情就会变得难以预料。
设想一下,updateInventory() 失败并抛出了一个异常。那么,handleOrder() 方法在调用 invent.get() 时将会抛出异常。到目前为止,还没有什么大问题,但 updateOrder() 呢?因为它在自己的线程上运行,所以它可能会成功完成。但是现在我们就有了一个库存和订单不匹配的问题。假设 updateOrder() 是一个代价高昂的操作。在这种情况下,我们白白浪费了资源,不得不编写某种防护逻辑来撤销对订单所做的更新,因为我们的整体操作已经失败。
假设 updateInventory() 是一个代价高昂的长时间运行操作,而 updateOrder() 抛出一个错误。即便 updateOrder() 抛出了错误,handleOrder() 任务依然会在 inventory.get() 方法上阻塞。理想情况下,我们希望 handleOrder() 任务在 updateOrder() 发生故障时取消 updateInventory(),这样就不会浪费时间了。
如果执行 handleOrder() 的线程被中断,那么中断不会被传播到子任务中。在这种情况下,updateInventory() 和 updateOrder() 会泄露并继续在后台运行。
对于这些场景,我们必须小心翼翼地编写变通方案和故障防护措施,把所有的职责推到了开发人员身上。
我们可以使用下面的代码,用结构化并发实现同样的功能。
void handleOrder() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future inventory = scope.fork(() -> updateInventory());
Future order = scope.fork(() -> updateOrder());
scope.join(); // Join both forks
scope.throwIfFailed(); // ... and propagate errors
// Here, both forks have succeeded, so compose their results
System.out.println("Inventory " + inventory.resultNow() + " updated for order " + order.resultNow());
}
}
与之前使用 ExecutorService 的样例不同,我们现在使用 StructuredTaskScope 来实现同样的结果,并将子任务的生命周期限制在词法的作用域内,在本例中,也就是 try-with-resources 语句体内。这段代码更易读,而且意图也很清楚。StructuredTaskScope 还自动确保以下行为:
基于短路的错误处理:如果 updateInventory() 或 updateOrder() 失败,另一个将被取消,除非它已经完成。这是由 ShutdownOnFailure() 实现的取消策略来管理的,我们还可以使用其他策略。
取消传播:如果运行 handleOrder() 的线程在调用 join() 之前或调用过程中被中断的话,当该线程退出作用域时,两个分支(fork)都会被自动取消。
可观察性:线程转储文件将清楚地显示任务层次,运行 updateInventory() 和 updateOrder() 的线程被显示为作用域的子线程。
4Loom 项目状况
Loom 项目开始于 2017 年,经历了许多变化和提议。虚拟线程最初被称为 fibers,但后来为了避免混淆而重新进行了命名。如今随着 Java 19 的发布,该项目已经交付了上文讨论的两个功能。其中一个是预览状态,另一个是孵化状态。因此,这些特性的稳定化之路应该会更加清晰。
5这对普通的 Java 开发人员意味着什么?
当这些特性生产环境就绪时,应该不会对普通的 Java 开发人员产生太大的影响,因为这些开发人员可能正在使用某些库来处理并发的场景。但是,在一些比较罕见的场景中,比如你可能进行了大量的多线程操作但是没有使用库,那么这些特性就是很有价值的了。虚拟线程可以毫不费力地替代你现在使用的线程池。根据现有的基准测试,在大多数情况下它们都能提高性能和可扩展性。结构化并发有助于简化多线程或并行处理,使其能加健壮,更易于维护。
6这对 Java 库开发人员意味着什么?
当这些特性生产环境就绪时,对于使用线程或并行的库和框架来说,将是一件大事。库作者能够实现巨大的性能和可扩展性提升,同时简化代码库,使其更易维护。大多数使用线程池和平台线程的 Java 项目都能够从切换至虚拟线程的过程中受益,候选项目包括 Tomcat、Undertow 和 Netty 这样的 Java 服务器软件,以及 Spring 和 Micronaut 这样的 Web 框架。我预计大多数 Java web 技术都将从线程池迁移到虚拟线程。Java web 技术和新兴的反应式编程库,如 RxJava 和 Akka,也可以有效地使用结构化并发。但这并不意味着虚拟线程将成为所有问题的解决方案,异步和反应式编程仍然有其适用场景和收益。
了解更多关于 Java、多线程和 Loom 项目的信息:
On the Performance of User-Mode Threads and Coroutines
https://inside.java/2020/08/07/loom-performance/
State of Loom
http://cr.openjdk.java.net/~rpressler/loom/loom/sol1_part1.html
Project Loom: Modern Scalable Concurrency for the Java Platform
https://www.youtube.com/watch?v=EO9oMiL1fFo
Thinking About Massive Throughput? Meet Virtual Threads!
https://foojay.io/today/thinking-about-massive-throughput-meet-virtual-threads/
Does Java 18 finally have a better alternative to JNI?
https://developer.okta.com/blog/2022/04/08/state-of-ffi-java
OAuth for Java Developers
https://developer.okta.com/blog/2022/06/16/oauth-jav
Cloud Native Java Microservices with JHipster and Istio https://developer.okta.com/blog/2022/06/09/cloud-native-java-microservices-with-istio
编辑:黄飞









 工商网监
工商网监
评论