往往不少童鞋写论文苦于数据获取艰难,辗转走上爬虫之路;许多分析师做舆情监控或者竞品分析的时候,也常常使用到爬虫。
2018-06-07 09:17:13 5997
5997 爬虫(crawler)也可以被称为spider和robot,通常是指对目标网站进行自动化浏览的脚本或者程序,包括使用requests库编写脚本等。随着互联网的不断发展,网络爬虫愈发常见,并占用了大量
2022-09-14 09:08:491265 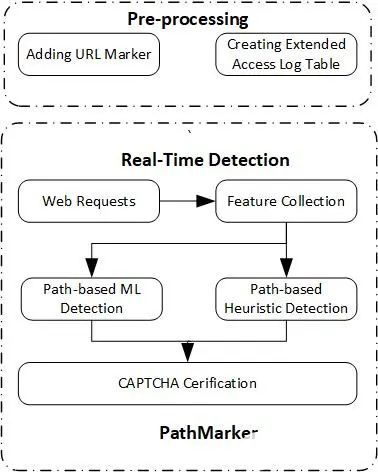
大数据时代,有两种技能可以给自己增加竞争优势。一种是数据分析,旨在挖掘数据的价值,做出最佳决策;另一种是数据获取,即爬虫。学会它,相当于在数据时代掌握了攫取能源的最有效方式。谷歌百度等搜索引擎的崛起
2021-07-25 09:28:28
在实际的爬虫抓取的过程中,由于会存在恶意采集或者恶意攻击的情况,很多网站都会设置相应的防爬取机制,通常防爬程序都是通过ip来识别机器人用户的,因此充足可用的ip信息可以为我们解决很多爬虫中的实际问题
2020-02-04 12:37:26
一、爬虫可以采集哪些数据 1.图片、文本、视频 爬取商品(店铺)评论以及各种图片网站,获得图片资源以及评论文本数据。 掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易
2019-10-15 17:25:40
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
2023-09-25 08:25:22
随着互联网的发展进步,现在互联网上也有许多网络爬虫。网络爬虫通过自己爬虫程序向目标网站采集相关数据信息。当然互联网的网站会有反爬策略。比如某电商网站就会限制一个用户IP的访问频率,从而出现验证码
2020-09-01 17:23:09
/************用户的爬虫程序需要支持API的自动提取代理IP,定期从url中获取代理IP的相关信息,格式如下:(1)默认支持文本(2)json格式(在API链接后面加上&format=json
2020-04-26 17:43:27
每个程序都不可避免地要进行异常处理,爬虫也不例外,假如不进行异常处理,可能导致爬虫程序直接崩掉。以下是网络爬虫出现的异常种类。URLError通常,URLError在没有网络连接(没有路由到特定
2018-05-09 17:26:11
golang语言也是爬虫中的一种框架语言。当然很多网络爬虫新手都会面临选择什么语言适合于爬虫。一般很多爬虫用户都会选择python和java框架语言来写爬虫程序从而进行采集数据。其实除了python
2020-09-09 17:41:32
的话,就需要多线程了,这里给个简单的线程池模板 这个程序只是简单地打印了1-10,但是可以看出是并发的。虽然说python的多线程很鸡肋,但是对于爬虫这种网络频繁型,还是能一定程度提高效率的。from
2019-01-02 14:37:55
Python爬虫和Web开发均是与网页相关的知识技能,无论是自己搭建的网站还是爬虫爬去别人的网站,都离不开相应的Python库,以下是常用的Python爬虫与Web开发库。1.爬虫库
2018-05-10 15:21:45
…好了,不说废话了。这次的目标主要是根据网易云中歌手的ID,下载该歌手的热门音乐的歌词和音频,并保存到本地的文件夹中。配置基础PythonSelenium(配置方法参照:Selenium配置)Chrome
2018-10-12 15:11:13
,想从事这方面的工作,需掌握以下知识:1. 学习Python基础知识并实现基本的爬虫过程一般获取数据的过程都是按照发送请求-获得页面反馈-解析并且存储数据 这三个流程来实现的。这个过程其实就是模拟
2018-06-20 17:14:15
Python爬虫练习一、爬虫简介1. 介绍2. 软件配置二、爬取南阳理工OJ题目三、爬取学校信息通知四、总结五、参考一、爬虫简介1. 介绍网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者
2022-01-11 06:32:07
,利用爬虫,我们可以解决部分数据问题,那么,如何学习Python数据爬虫能?1.学习Python基础知识并实现基本的爬虫过程一般获取数据的过程都是按照 发送请求-获得页面反馈-解析并且存储数据 这三个
2018-05-09 17:25:03
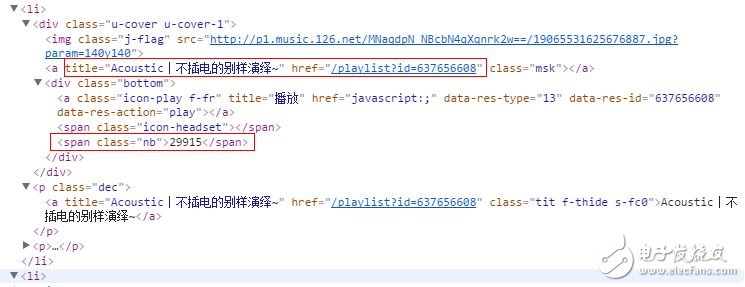
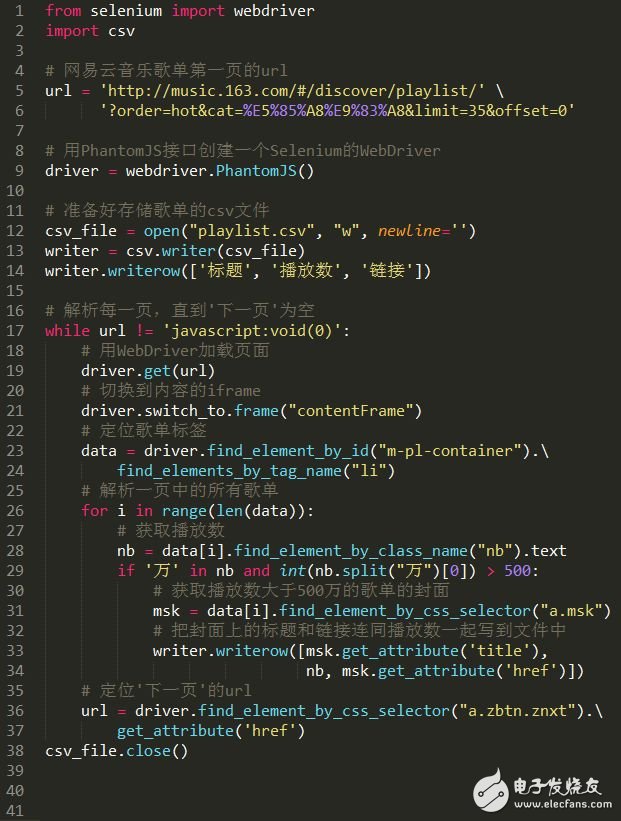
Python数据可视化:网易云音乐歌单
2020-07-19 08:30:42
Scrapy爬虫框架
2019-09-25 14:15:57
Ubuntu 1604后台运行scrapy爬虫程序
2020-05-25 12:32:41
借助.NET,labview实现爬虫功能。爬取12306上的票务信息。懒得搭建python的环境了。用C#编写票务信息爬虫库,然后用labview调用。labview源代码见附件。具体的配置实现细节
2023-04-02 17:20:11
patyon爬虫技术PDF课件
2018-10-31 16:08:00
patyon爬虫技术PDF课件分享
2019-02-14 16:33:29
的数据,从而识别出某用户是否为水军学习爬虫前的技术准备(1). Python基础语言: 基础语法、运算符、数据类型、流程控制、函数、对象 模块、文件操作、多线程、网络编程 … 等(2). W3C标准
2022-03-21 16:51:02
:https://github.com/darknessomi/musicbox功能特性320kbps的高品质音乐歌曲,艺术家,专辑检索网易22个歌曲排行榜网易新碟推荐网易精选歌单网易主播电台私人歌单,每日
2017-11-05 20:27:15
/*名称:播放音乐 说明:程序运行时播放生日快乐歌,未使用定时器中断,所有频率完全用延时实现 */ #include #define uchar unsigned char #define uint
2012-02-17 11:07:00
什么是爬虫?爬虫的价值?最简单的python爬虫爬虫基本架构
2020-11-05 06:13:12
刚接触爬虫的新手经常会问,到底需要使用哪种语言做爬虫,其实,我相信任何语言,只要他具备访问网络的标准库,都可以很轻易的做到这一点。刚刚接触爬虫的时候,我总是纠结于用 Python 来做爬虫,现在
2020-01-14 13:51:53
刚接触爬虫的新手经常会问,到底需要使用哪种语言做爬虫,其实,我相信任何语言,只要他具备访问网络的标准库,都可以很轻易的做到这一点。刚刚接触爬虫的时候,我总是纠结于用 Python 来做爬虫,现在
2020-02-03 13:22:09
在如今的互联网时代,网络爬虫成了许多企业的重要岗位之一。当然在数据采集中会遇到各种问题,例如限制IP,出现访问验证码等。这种时候就需要各种反爬策略和使用HTTP代理去解决问题。在爬虫用在使用代理
2020-08-21 17:28:40
scrapy-Redis分布式爬虫
2020-03-24 10:24:02
采用音乐音谱节拍的方式举个栗子,单片机通过蜂鸣器来播放生日快乐歌。#include "reg51.h"#define uchar unsigned char#define
2021-11-25 08:57:53
可使用qplay的的网络数字音乐播放器
2022-03-21 18:06:04
一、概要1.1、功能基于柿饼派实现一个网络音频流播放器,目前实现的基本功能是这样的:扫描附近的WiFi,输入密码后连接WIFi能够播放本地音乐能够搜索音乐能够播放网络音乐能够查看所播放网络音乐的歌词
2022-04-20 14:21:53
文件含有KEIL程序、生日快乐歌曲谱、无源蜂鸣器的频率对应的音调(参考)。是一份相对比较全面的资料,供感兴趣者参考学习。。
2015-01-12 21:31:31
朋友需要从网站上下载大量的数据,一个一个复制粘贴太费事。我写了一个简单的网络爬虫,主要用到正则表达式的东西,可以自动下载网站上的数据。代码如下,仅作交流使用,期望起到抛砖迎玉的效果,matlab其
2012-12-18 15:29:19
大家都知道采集数据是要花时间,可是也不能一直等着,尤其是需要采集大量数据的情况下。那么如何提高爬虫采集效率就是十分关键的,那小编带大伙儿一块去了解如何提高爬虫采集效率问题。 1.尽可能减少网站访问
2019-12-23 17:16:02
本帖最后由 eehome 于 2013-1-5 09:58 编辑
菜鸟不懂,求大家帮忙 如何用单片机 控制唱生日快乐歌,都要哪些元件?是用蜂鸣器有源的还是无源的还是用什么扬声器什么的,具体怎么控制,求PCB图啊,最好 有个仿真 的还有C程序啊,谢谢
2012-12-11 17:40:40
imdbcn爬虫实例 imdbcn网站结构分析 创建爬虫项目 运行imdb爬虫
2020-11-05 07:07:00
抓取策略。几种常见的抓取策略:1、深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,直到处理完这条线路之后才会转入下一个起始页,继续跟踪链接。2、宽度优先遍历策略
2019-11-22 17:25:30
被机器人肆意地滥用,网站的安全和流量费用就会面临严重威胁,因此很多网站都会想办法防止爬虫程序接入。为了能够更好的爬虫,我们需要使用可变的ip地址,建立网络爬虫的第一原则是:所有信息都可以伪造。但是有
2019-12-12 17:39:28
怎样利用51单片机去实现生日快乐歌?其电路该如何去设计?如何去编写程序代码?
2021-07-06 07:22:21
有没有大神会用LabVIEW编写一个音乐播放器软件啊~求教程!求大神carry啊~新手学LabVIEW,第一次做项目想做一个音乐播放器
2014-08-13 20:26:28
每秒几十万的大规模网络爬虫是如何炼成的?
2019-05-27 15:02:25
全部程序是这样的:#include#define uchar unsigned char#define uint unsigned int***it BEEP=P1^6; //蜂鸣器控制引脚
2013-02-16 14:33:02
能声控发出祝你生日快乐歌的电路
2009-04-13 17:42:21 25
25 无论是通用搜索还是垂直搜索,其关键的核心技术之一就是网络爬虫的设计。本文结合HTMLParser 信息提取方法,对生活类垂直搜索引擎中网络爬虫进行了详细研究。通过深入分
2009-06-03 11:32:2346 本文提出了一种维护WAP 网站的网络爬虫系统,该系统可以自动遍历WAP 网站,并对网页进行分析,检查语法和语义的错误。关键词:WAP、网络爬虫、WML、XHTMLAbstract:This pa
2009-06-11 16:26:0724 网络爬虫如何在限定带宽的条件下进行爬行是一个有巨大应用价值的问题,但是目前对这个方面的研究较少,本文提出了一种基于对站点礼貌
2009-09-11 09:27:1314 网络爬虫是当今网络实时更新和搜索引擎技术的共同产物。文中深入探讨了如何应用网络爬虫技术实现实时更新数据和搜索引擎技术。在对网络爬虫技术进行深入分析的基础上,给出
2010-02-26 14:23:519 无线下载音乐播放器是一种全新的概念,传统的MP3音乐播放器都是使用USB口与PC机通信,从PC机上下载音乐歌曲,这使得在没有PC机的情况下MP3的音乐下载受到一定程度的限制。本文介绍
2011-03-23 17:04:37134 红外遥控六足爬虫机器人设计!资料来源网络,如有侵权,敬请见谅
2015-11-20 15:08:1719 详细用Python写网络爬虫
2017-09-07 08:40:3432 的搜索器——网络爬虫。
多线程网络爬虫程序是从指定的Web页面中按照宽度优先算法进行解析、搜索,并把搜索到的每条URL进行抓取、保存并且以URL为新的入口在互联网上进行不断的爬行的自动执行后台程序。
网络爬虫主要应用socket套接
2018-04-08 15:31:381 学Python,想必大家都是从爬虫开始的吧。毕竟网上类似的资源很丰富,开源项目也非常多。
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
2018-05-19 10:45:454899 本文主要内容:以最短的时间写一个最简单的爬虫,可以抓取论坛的帖子标题和帖子内容。
本文受众:没写过爬虫的萌新。
2018-06-10 09:57:586826 
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。
2018-06-26 11:52:455239 
本文档的主要内容详细介绍的是python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
2018-08-28 15:32:2929 本文档的作用内容详细介绍的是蜂鸣器播放音乐C语音程序免费下载(包含了播放生日快乐歌曲的详细设计资料)
2018-09-13 15:26:4245 在互联网日益发展的今天,计算机应用成为生活中不可或缺的一部分。本文所介绍的网络爬虫程序,是从一个庞大的网站中,将符合预设条件的对象“捕获” 并保存的一种程序。如果将庞大的互联网比作一张蜘蛛网,爬虫程序就像网上游弋的蜘蛛,将网上一个个“猎物”摘取下来。
2018-09-25 08:00:0023 进入大数据时代,爬虫技术越来越重要,因为它是获取数据的一个重要手段,是大数据和云计算的基础。那么,爬虫到底是如何实现数据的获取的呢?今天和大家分享的就是一个系统学习爬虫技术的过程:先掌握爬虫相关知识点,再选择一门合适的语言深耕爬虫技术。
2019-01-02 16:30:0110 爬虫现在越来越火,随之带来的就是一大波的就业岗位,随之越来越多的人转行学习Python,其中不缺乏Java等语言程序员,难道,爬虫在未来会狠狠的压住其他语言,而一直蝉联冠军吗?
2019-03-20 15:09:085075 通用网络爬虫根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器去掉页面上的HTML
2019-03-21 17:05:2527795 本视频主要详细介绍了网络爬虫的爬行策略,分别是PartialPageRank策略、宽度优先遍历策略、大站优先策略、反向链接数策略、OPIC策略策略、深度优先遍历策略。
2019-03-21 17:08:076483 该算法是指网络爬虫会从选定的一个超链接开始,按照一条线路,一个一个链接访问下去,直到达到这条线路的叶子节点,即不包含任何超链接的HTML文件,处理完这条线路之后再转入下一个起始页,继续访问新的起始页面所包含的链接中的一条,直到到达叶子结点。这个方法有个优点是网络爬虫在设计的时候比较容易。
2019-03-21 17:10:4614064 网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。如下图是深度优先的一种遍历方式是A到B到D到E到C到F(ABDECF)而宽度优先的遍历方式ABCDEF。
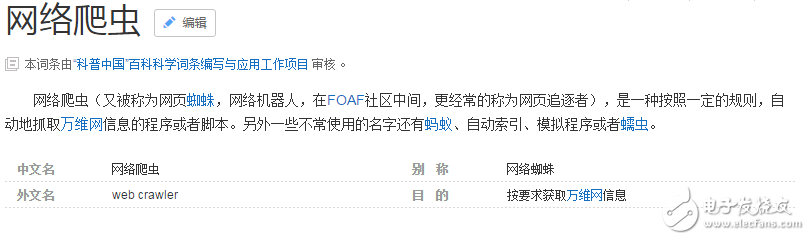
2019-03-21 17:13:1612400 网络爬虫又被称为网页蜘蛛,聚焦爬虫,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
2019-03-21 17:15:3830917 网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到按照某种策略把互联网上所有的网页都抓取完为止的技术。
2019-03-21 17:18:019423 网络爬虫在大多数情况中都不违法,其实我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的(百度自营的产品除外,如百度知道、百科等),所以网络爬虫作为一门技术,技术本身是不违法的,且在大多数情况下你都可以放心大胆的使用爬虫技术。
2019-03-21 17:20:0111445 本视频主要详细介绍了常用的网络爬虫软件,分别是神箭手云爬虫、火车头采集器、八爪鱼采集器、后羿采集器。
2019-03-21 17:25:2428738 网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
2019-03-22 16:31:055763 如果你在爬虫过程中有遇到“您的请求太过频繁,请稍后再试”,或者说代码完全正确,可是爬虫过程中突然就访问不了。
2019-04-24 09:47:174832 
你以为你真的会写爬虫了吗?快来看看真正的爬虫架构!
2019-05-02 17:02:003483 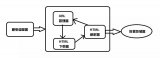
音乐编码----生日快乐歌,基于c51单片机编写简单蜂鸣器音乐程序的方法,乐普编辑应用程序,谱曲软件,音乐乐谱提取软件,制作51单片机音乐盒的程序资料合集免费下载。
2019-05-05 08:00:0049 本书讲解 了 如何使用Python 来编写网络爬虫程序 , 内 容包括 网络爬虫简介 , 从页面 中 抓取数据 的三种方法 , 提取缓存 中 的 数据 , 使用 多 个线程和进程来进行并发抓取
2019-07-08 08:00:009 有的朋友希望能够深层次地了解搜索引擎的爬虫工作原理,或者希望自己能够开发出款私人搜索引擎,那么此时,学习爬虫是非常有必要的。简单来说,我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息
2019-09-18 11:35:586534 我之前写了很多关于爬虫的文章,涉及了各种各样的爬取策略;也爬了不少主流非主流的网站。从我刚入门爬虫到现在,每一个爬虫对应的文章都可以在我的博客上找到,不论是最最简单的抓取,还是scrapy的使用。
2019-09-18 11:39:532747 近日,多家通过爬虫技术开展大数据信贷风控的公司被查。短短几天时间,“爬虫”技术被推上了风口浪尖,大数据风控行业也迎来了前所未有的“震荡”。业内人士透露,这些被调查的大数据公司基本都是涉嫌利用网络爬虫技术侵犯个人隐私,并将这些数据信息转卖给其他机构获利。
2019-09-21 11:16:403993 在此活动中,小爱触屏音箱立省100元,该音箱原售价299元,现在入手仅需199元。小爱触屏音箱能播放视频,可以同步QQ音乐歌单,内置海量优质有声读物,支持语音控制,拥有600+种实用技能。
2019-11-11 15:15:20811 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
2019-12-04 08:00:003 本文档的主要内容详细介绍的是使用单片机编写的音乐程序。
2020-01-21 12:18:005392 
技术无罪?江湖传言,互联网上50%以上的流量都是由爬虫创造的,很多人都表示:无爬虫就无互联网的繁荣。也正因为此,网上各种爬虫教程风靡不绝,惹各路大神小白观之参与之。但是,无节制的背后往往隐藏着
2020-02-04 14:45:552580 写爬虫,是一个非常考验综合实力的活儿。有时候,你轻而易举地就抓取到了想要的数据;有时候,你费尽心思却毫无所获。
2020-02-05 11:49:554962 网络大数据要抓取信息,大多需要经过python爬虫工作,爬虫能够帮助我们将页面的信息抓取下来。
2020-06-28 16:25:061759 最近,我们经常能够听到XX公司做违法爬虫被一锅端,程序员坐牢。还有XX公司的爬虫给12306网站带来重压等等新闻,在看热闹的同时,很多人都会提出疑问爬虫到底是啥?今天就彻底给您讲明白。 按照定义网络
2020-10-12 16:05:151737 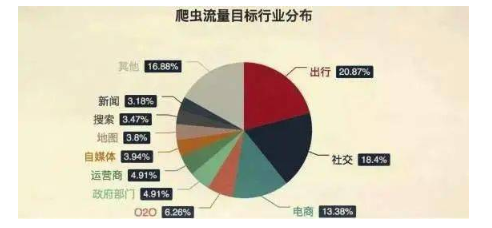
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,网络爬虫(web crawler)随之而生。
2020-12-25 18:28:43868 昨日(1月5日),虾米音乐宣布即将关停。这一消息引发公众关注的同时,也让其他音乐播放平台作出反应。当天,QQ音乐上线了“虾米歌曲一键搬家”功能。1月6日凌晨,网易云音乐发布公告,教你“如何一键迁移虾米歌单到网易云音乐”。两者不约而同地选择“送会员”作为引流方式,试图吸引“无家可归”的虾米用户。
2021-01-06 10:41:503026 用Python写网络爬虫的方法说明。
2021-06-01 11:55:3221 最近在学爬虫时发现许多网站都有自己的反爬虫机制,这让我们没法直接对想要的数据进行爬取,于是了解这种反爬虫机制就会帮助我们找到解决方法。 常见的反爬虫机制有判别身份和IP限制两种,下面我们将一一来进行
2021-07-29 15:58:314649 
网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下几种类型: 通用网络爬虫:就是
2022-03-21 16:50:551585 ./oschina_soft/yun-playlist-downloader.zip
2022-06-01 10:35:305 如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
2022-12-14 10:10:24869 网络爬虫(被称为 网页蜘蛛,网络机器人 ),就是 模拟客户端发送网络请求 ,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序
2023-02-16 15:55:28374 
爬虫的本质就是模仿人类自动访问网站的程序,你在浏览器中做的大部分动作基本都可以通过网络爬虫程序来实现。
2023-02-23 14:11:42517 
利用 Python编写简单网络爬虫实例2
实验环境python版本:3.3.5(2.7下报错
2023-02-24 11:05:2613 今天推荐一款更加简单、轻量级,且功能强大的爬虫框架:feapder 项目地址: https://github.com/Boris-code/feapder 2. 介绍及安装 和 Scrapy 类似
2023-11-01 09:48:16509 想要学习爬虫,如果比较详细的了解web开发的前端知识会更加容易上手,时间不够充裕,仅仅了解html的相关知识也是够用的。
2023-11-14 14:44:49203 
正在加载...
 电子发烧友App
电子发烧友App




















 工商网监
工商网监
评论