爬虫(crawler)也可以被称为spider和robot,通常是指对目标网站进行自动化浏览的脚本或者程序,包括使用requests库编写脚本等。随着互联网的不断发展,网络爬虫愈发常见,并占用了大量
2022-09-14 09:08:49 1265
1265 
今天给大家分享的是嵌入式里通用微秒(microseconds)计时函数框架设计与实现。
2022-10-14 12:41:331536 大数据时代,有两种技能可以给自己增加竞争优势。一种是数据分析,旨在挖掘数据的价值,做出最佳决策;另一种是数据获取,即爬虫。学会它,相当于在数据时代掌握了攫取能源的最有效方式。谷歌百度等搜索引擎的崛起
2021-07-25 09:28:28
和错误的处理方式,二次开发者无须关心,也无权决定。.2. 创建型模式由于框架通常都涉及到各种不同子类对象的创建,创建型模式是经常使用的。例如一个绘图软件的框架,有一个基类定义了图形对象的接口,基于它可
2020-12-17 16:44:01
爬虫框架scrapy
2019-04-03 15:57:48
在实际的爬虫抓取的过程中,由于会存在恶意采集或者恶意攻击的情况,很多网站都会设置相应的防爬取机制,通常防爬程序都是通过ip来识别机器人用户的,因此充足可用的ip信息可以为我们解决很多爬虫中的实际问题
2020-02-04 12:37:26
。 2.验证码识别工具-OCR 现在验证码几乎在任何一个网站的交互界面中都存在,目的当然是为了防止恶意程序的攻击。 在使用爬虫时,如果获取速度过快,通常会出现验证码验证当前访问的是人还是爬虫,如果
2019-10-15 17:25:40
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
2023-09-25 08:25:22
设计多线程异步IO,实现代理IP并发处理,不仅繁琐,而且影响效率。)2、自动转发的爬虫代理(自动转发的爬虫代理IP”通过固定云代理服务地址,建立专线网络链接,代理平台自动实现毫秒级代理IP切换,保证了网络
2020-09-01 17:23:09
,返回JSON格式)(3)在链接后面加上 &part=分隔符 ,分隔符需要使用url转义而爬虫程序通过获取出来的IP向网站发出请求获取数据。 2自动转发的爬虫代理:通过固定云代理服务地址,建立专线网络
2020-04-26 17:43:27
每个程序都不可避免地要进行异常处理,爬虫也不例外,假如不进行异常处理,可能导致爬虫程序直接崩掉。以下是网络爬虫出现的异常种类。URLError通常,URLError在没有网络连接(没有路由到特定
2018-05-09 17:26:11
了ArkUI是一套用于构建HarmonyOS应用界面的UI开发框架,本期我们将从架构设计上来聊聊ArkUI的设计理念。
ArkUI架构图
从架构图可以看出,ArkUI的设计理念是在端到端整条技术路径设计上建立
2022-12-21 10:26:42
golang语言也是爬虫中的一种框架语言。当然很多网络爬虫新手都会面临选择什么语言适合于爬虫。一般很多爬虫用户都会选择python和java框架语言来写爬虫程序从而进行采集数据。其实除了python
2020-09-09 17:41:32
1、HDF驱动框架之linux驱动开发介绍什么是驱动开发?这个看似不是问题的问题却很重要,我们必须需要从这一步开始理清楚,见下图:HDF 驱动框架探路(一):2、HDF驱动框架之应用态打通内核的框架
2022-03-15 15:31:29
.Request(url,form_data)response = urllib2.urlopen(request)print response.read()2、使用代理IP在开发爬虫过程中经常会遇到IP被封掉的情况,这时
2019-01-02 14:37:55
的接口,一般我们都是和正则结合使用,如果对速度有要求的话,建议用lmxp,它比bs4 速度要快很多。2.Scrapy爬虫的世界里面有没有懒人专用的框架,当然有啦,scrapy就是其中比较有名的,可以快速
2018-05-10 15:21:45
解析网页,便于抽取数据。2.了解非结构化数据的存储爬虫抓取的数据结构复杂传统的结构化数据库可能并不是特别适合我们使用。我们前期推荐使用MongoDB 就可以。3. 掌握一些常用的反爬虫技巧使用代理IP池
2018-06-20 17:14:15
Python爬虫练习一、爬虫简介1. 介绍2. 软件配置二、爬取南阳理工OJ题目三、爬取学校信息通知四、总结五、参考一、爬虫简介1. 介绍网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者
2022-01-11 06:32:07
返回的html。以上是老男孩教育对Django框架设计思想的简要介绍,想要了解更多信息,快来参加老男孩教育Python培训班吧,让您轻松掌握高深Python技能!
2018-06-15 15:01:49
负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。2.了解非结构化数据的存储。爬虫抓取的数据结构复杂 传统的结构化数据库可能并不是特别适合我们使用。我们前期推荐使用MongoDB 就可以
2018-05-09 17:25:03
第12章 STM32F407的HAL库框架设计学习通过本章节,主要是想让大家对HAL库程序设计的基本套路有个了解,防止踩坑。目录第12章 STM32F407的HAL库框架设计学习12.1 初学者重要
2021-08-10 06:23:26
Scrapy爬虫框架
2019-09-25 14:15:57
移植ThreadX的流程是怎样的?怎么实现ThreadX内核模板框架设计?
2021-11-30 06:25:42
借助.NET,labview实现爬虫功能。爬取12306上的票务信息。懒得搭建python的环境了。用C#编写票务信息爬虫库,然后用labview调用。labview源代码见附件。具体的配置实现细节
2023-04-02 17:20:11
patyon爬虫技术PDF课件
2018-10-31 16:08:00
patyon爬虫技术PDF课件分享
2019-02-14 16:33:29
的数据,从而识别出某用户是否为水军学习爬虫前的技术准备(1). Python基础语言: 基础语法、运算符、数据类型、流程控制、函数、对象 模块、文件操作、多线程、网络编程 … 等(2). W3C标准
2022-03-21 16:51:02
什么是爬虫?爬虫的价值?最简单的python爬虫爬虫基本架构
2020-11-05 06:13:12
刚接触爬虫的新手经常会问,到底需要使用哪种语言做爬虫,其实,我相信任何语言,只要他具备访问网络的标准库,都可以很轻易的做到这一点。刚刚接触爬虫的时候,我总是纠结于用 Python 来做爬虫,现在
2020-01-14 13:51:53
刚接触爬虫的新手经常会问,到底需要使用哪种语言做爬虫,其实,我相信任何语言,只要他具备访问网络的标准库,都可以很轻易的做到这一点。刚刚接触爬虫的时候,我总是纠结于用 Python 来做爬虫,现在
2020-02-03 13:22:09
在如今的互联网时代,网络爬虫成了许多企业的重要岗位之一。当然在数据采集中会遇到各种问题,例如限制IP,出现访问验证码等。这种时候就需要各种反爬策略和使用HTTP代理去解决问题。在爬虫用在使用代理
2020-08-21 17:28:40
卷积神经网络的层级结构 卷积神经网络的常用框架
2020-12-29 06:16:44
在网络安全领域,NIST 框架是什么?
2023-04-17 07:56:44
朋友需要从网站上下载大量的数据,一个一个复制粘贴太费事。我写了一个简单的网络爬虫,主要用到正则表达式的东西,可以自动下载网站上的数据。代码如下,仅作交流使用,期望起到抛砖迎玉的效果,matlab其
2012-12-18 15:29:19
次数 单次爬虫的主要把时间消耗在网络请求等待响应上面,所以能减少网站访问就减少网站访问,既减少自身的工作量,也减轻网站的压力,还降低被封的风险。 第一步要做的就是流程优化,尽量精简流程,一些数据
2019-12-23 17:16:02
imdbcn爬虫实例 imdbcn网站结构分析 创建爬虫项目 运行imdb爬虫
2020-11-05 07:07:00
抓取策略。几种常见的抓取策略:1、深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,直到处理完这条线路之后才会转入下一个起始页,继续跟踪链接。2、宽度优先遍历策略
2019-11-22 17:25:30
被机器人肆意地滥用,网站的安全和流量费用就会面临严重威胁,因此很多网站都会想办法防止爬虫程序接入。为了能够更好的爬虫,我们需要使用可变的ip地址,建立网络爬虫的第一原则是:所有信息都可以伪造。但是有
2019-12-12 17:39:28
怎么实现ThreadX内核模板框架设计?
2021-11-29 07:45:52
构架设计,这种构架设计是新的知识希望能够得到一本,可以继续发展构架思维和构架设计灵感。
2023-12-18 11:09:57
每秒几十万的大规模网络爬虫是如何炼成的?
2019-05-27 15:02:25
RTOS。或者使用RTOS,在整体思路上比较迷茫,不知从何入手,所以本文来聊聊我对单片机程序的整体框架设计的一些思路体会。为啥要讨论架构单片机系统开发人员的目标之一是在编程环境中创建固件,以实现低成本系...
2022-02-23 07:30:04
无论是通用搜索还是垂直搜索,其关键的核心技术之一就是网络爬虫的设计。本文结合HTMLParser 信息提取方法,对生活类垂直搜索引擎中网络爬虫进行了详细研究。通过深入分
2009-06-03 11:32:23 46
46 本文提出了一种维护WAP 网站的网络爬虫系统,该系统可以自动遍历WAP 网站,并对网页进行分析,检查语法和语义的错误。关键词:WAP、网络爬虫、WML、XHTMLAbstract:This pa
2009-06-11 16:26:0724 网络爬虫如何在限定带宽的条件下进行爬行是一个有巨大应用价值的问题,但是目前对这个方面的研究较少,本文提出了一种基于对站点礼貌
2009-09-11 09:27:1314 本文在分析建立城乡公交信息系统意义的基础上,通过详细调研城乡公交工作需求,规划和设计了基于GIS 的城乡公交信息系统的框架设计,功能结构,并根据系统功能需要,在简
2009-12-19 14:12:458 网络爬虫是当今网络实时更新和搜索引擎技术的共同产物。文中深入探讨了如何应用网络爬虫技术实现实时更新数据和搜索引擎技术。在对网络爬虫技术进行深入分析的基础上,给出
2010-02-26 14:23:519 架设一台FTP服务器其实很简单。首先,要保证你的机器能上网,而且有不低于ADSL 512Kbps的网络速度。其次,硬件性能要能满足你的需要。最后,需要安装FTP
2006-03-07 22:02:07864 该框架采用模块化思想进行设计,由可用宽带计算、接入控制、资源预留等功能模块组成,提出了新的AdHoc网络QoS源路由框架设计
2011-05-26 15:44:0332 本文提供了一个Web环境下基于构件的IERP系统软件的框架设计,在论文中首先分析了IERP的定义,包括IERP、ERP的含义和集成过程。
2011-06-14 10:07:441477 
红外遥控六足爬虫机器人设计!资料来源网络,如有侵权,敬请见谅
2015-11-20 15:08:1719 易乐思标准版Plus室外迷你半球型网络摄像机
2016-12-25 00:34:540 易乐思标准版Plus室内迷你半球型网络摄像机
2016-12-25 00:34:190 基于CAN总线的通讯系统软件框架设计
2017-01-24 16:54:2421 详细用Python写网络爬虫
2017-09-07 08:40:3432 基于ARM Cortex-M4的MQX中断机制分析与中断程序框架设计
2017-09-25 08:29:386 基于ARMCortex_M4的MOX中断机制分析与中断程序框架设计
2017-09-28 09:13:064 不断提高和完善防御的方法和手段。针对此问题,提出了一种基于Scrapy的爬虫框架的Web应用程序漏洞检测方法。通过框架提供的便利条件对页面进行提取分析,根据不同的攻击方式生成特有的攻击向量,最后使页面注入点与攻击向量组合达到测试是否具有漏洞
2017-12-07 09:48:312 的软件人知识通信( CSMKC)框架。首先,对知识通信框架中的消息层、知识层和情景层进行了设计;然后,从消息层实现、知识层实现和情景层实现三个方面介绍情景驱动的软件人知识通信实现的关键点;最后,基本实现了不同软件人之间知
2018-01-22 15:55:071 学Python,想必大家都是从爬虫开始的吧。毕竟网上类似的资源很丰富,开源项目也非常多。
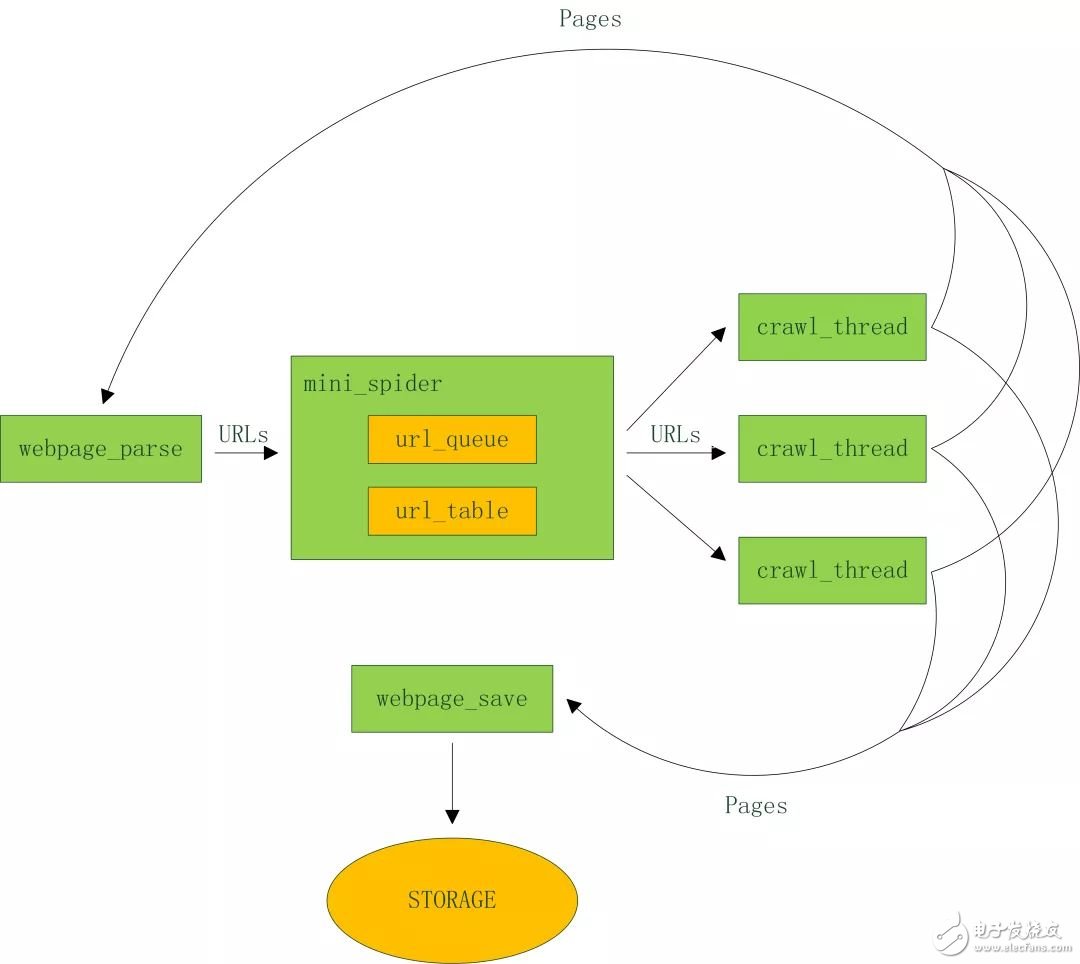
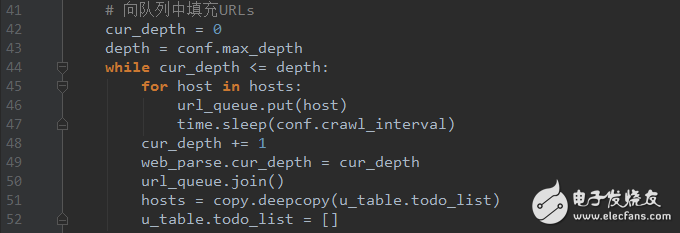
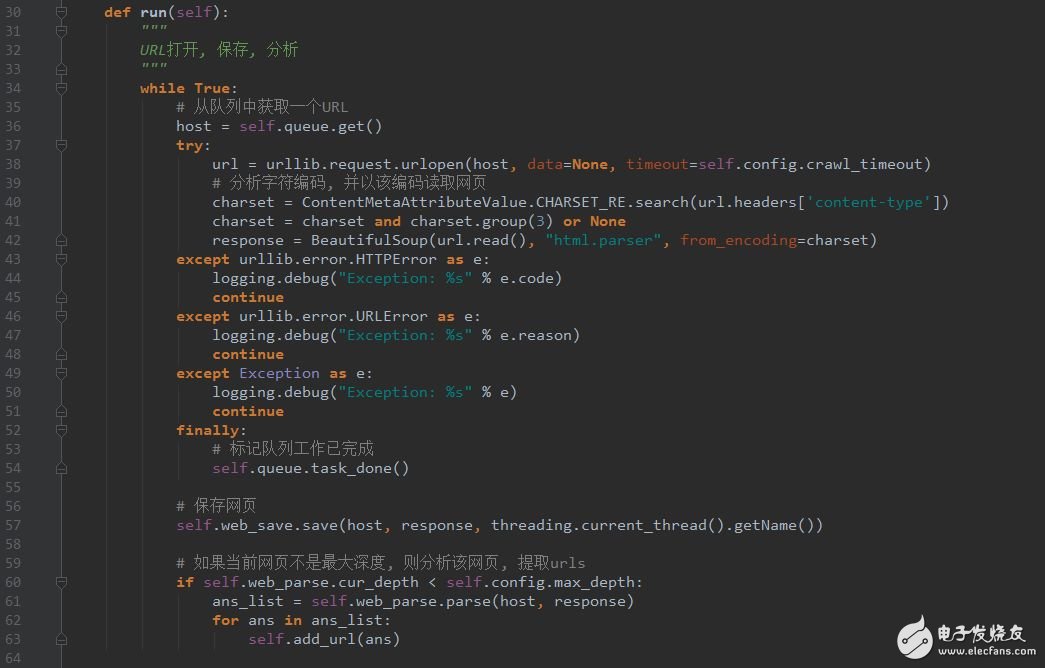
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
2018-05-19 10:45:454899 本文主要内容:以最短的时间写一个最简单的爬虫,可以抓取论坛的帖子标题和帖子内容。
本文受众:没写过爬虫的萌新。
2018-06-10 09:57:586826 
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。
2018-06-26 11:52:455239 
本文档的主要内容详细介绍的是python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
2018-08-28 15:32:2929 在互联网日益发展的今天,计算机应用成为生活中不可或缺的一部分。本文所介绍的网络爬虫程序,是从一个庞大的网站中,将符合预设条件的对象“捕获” 并保存的一种程序。如果将庞大的互联网比作一张蜘蛛网,爬虫程序就像网上游弋的蜘蛛,将网上一个个“猎物”摘取下来。
2018-09-25 08:00:0023 tart_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
2018-12-07 16:12:3323032 
针对数字城市研究手段不足,尤其在收集大量研究文献的基础上对数字城市进行整体研究上的欠缺,本文基于R语言和Selenium框架设计了稳定、高效的爬虫程序,获取了中国知网2018年5月前收录的数字城市
2018-12-20 15:50:133 进入大数据时代,爬虫技术越来越重要,因为它是获取数据的一个重要手段,是大数据和云计算的基础。那么,爬虫到底是如何实现数据的获取的呢?今天和大家分享的就是一个系统学习爬虫技术的过程:先掌握爬虫相关知识点,再选择一门合适的语言深耕爬虫技术。
2019-01-02 16:30:0110 本视频主要详细介绍了网络爬虫的爬行策略,分别是PartialPageRank策略、宽度优先遍历策略、大站优先策略、反向链接数策略、OPIC策略策略、深度优先遍历策略。
2019-03-21 17:08:076483 该算法是指网络爬虫会从选定的一个超链接开始,按照一条线路,一个一个链接访问下去,直到达到这条线路的叶子节点,即不包含任何超链接的HTML文件,处理完这条线路之后再转入下一个起始页,继续访问新的起始页面所包含的链接中的一条,直到到达叶子结点。这个方法有个优点是网络爬虫在设计的时候比较容易。
2019-03-21 17:10:4614064 网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。如下图是深度优先的一种遍历方式是A到B到D到E到C到F(ABDECF)而宽度优先的遍历方式ABCDEF。
2019-03-21 17:13:1612400 网络爬虫又被称为网页蜘蛛,聚焦爬虫,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
2019-03-21 17:15:3830917 网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到按照某种策略把互联网上所有的网页都抓取完为止的技术。
2019-03-21 17:18:019423 网络爬虫在大多数情况中都不违法,其实我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的(百度自营的产品除外,如百度知道、百科等),所以网络爬虫作为一门技术,技术本身是不违法的,且在大多数情况下你都可以放心大胆的使用爬虫技术。
2019-03-21 17:20:0111445 本视频主要详细介绍了常用的网络爬虫软件,分别是神箭手云爬虫、火车头采集器、八爪鱼采集器、后羿采集器。
2019-03-21 17:25:2428738 本视频主要详细介绍了python爬虫框架有哪些,分别是Django、CherryPy、Web2py、TurboGears、Pylons、Grab、BeautifulSoup、Cola。
2019-03-22 16:13:446385 爬虫系统首先从互联网页面中精心选择一部分网页,以这些网页的链接地址作为种子URL,将这些种子放入待抓取URL队列中,爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。
2019-03-22 16:19:315678 网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
2019-03-22 16:31:055763 你以为你真的会写爬虫了吗?快来看看真正的爬虫架构!
2019-05-02 17:02:003483 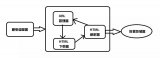
本书讲解 了 如何使用Python 来编写网络爬虫程序 , 内 容包括 网络爬虫简介 , 从页面 中 抓取数据 的三种方法 , 提取缓存 中 的 数据 , 使用 多 个线程和进程来进行并发抓取
2019-07-08 08:00:009 有的朋友希望能够深层次地了解搜索引擎的爬虫工作原理,或者希望自己能够开发出款私人搜索引擎,那么此时,学习爬虫是非常有必要的。简单来说,我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息
2019-09-18 11:35:586534 我之前写了很多关于爬虫的文章,涉及了各种各样的爬取策略;也爬了不少主流非主流的网站。从我刚入门爬虫到现在,每一个爬虫对应的文章都可以在我的博客上找到,不论是最最简单的抓取,还是scrapy的使用。
2019-09-18 11:39:532747 近日,多家通过爬虫技术开展大数据信贷风控的公司被查。短短几天时间,“爬虫”技术被推上了风口浪尖,大数据风控行业也迎来了前所未有的“震荡”。业内人士透露,这些被调查的大数据公司基本都是涉嫌利用网络爬虫技术侵犯个人隐私,并将这些数据信息转卖给其他机构获利。
2019-09-21 11:16:403993 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
2019-12-04 08:00:003 技术无罪?江湖传言,互联网上50%以上的流量都是由爬虫创造的,很多人都表示:无爬虫就无互联网的繁荣。也正因为此,网上各种爬虫教程风靡不绝,惹各路大神小白观之参与之。但是,无节制的背后往往隐藏着
2020-02-04 14:45:552580 网络大数据要抓取信息,大多需要经过python爬虫工作,爬虫能够帮助我们将页面的信息抓取下来。
2020-06-28 16:25:061759 最近,我们经常能够听到XX公司做违法爬虫被一锅端,程序员坐牢。还有XX公司的爬虫给12306网站带来重压等等新闻,在看热闹的同时,很多人都会提出疑问爬虫到底是啥?今天就彻底给您讲明白。 按照定义网络
2020-10-12 16:05:151737 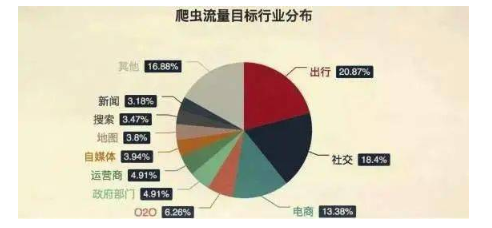
InsideiCoupler®技术:封装和引线框架设计
2021-05-18 19:12:053 用Python写网络爬虫的方法说明。
2021-06-01 11:55:3221 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下几种类型: 通用网络爬虫:就是
2022-03-21 16:50:551585 涉及智慧楼宇方案框架
2022-06-08 14:29:020 网络爬虫(被称为 网页蜘蛛,网络机器人 ),就是 模拟客户端发送网络请求 ,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序
2023-02-16 15:55:28374 
爬虫的本质就是模仿人类自动访问网站的程序,你在浏览器中做的大部分动作基本都可以通过网络爬虫程序来实现。
2023-02-23 14:11:42517 
利用 Python编写简单网络爬虫实例2
实验环境python版本:3.3.5(2.7下报错
2023-02-24 11:05:2613 今天推荐一款更加简单、轻量级,且功能强大的爬虫框架:feapder 项目地址: https://github.com/Boris-code/feapder 2. 介绍及安装 和 Scrapy 类似
2023-11-01 09:48:16509 想要学习爬虫,如果比较详细的了解web开发的前端知识会更加容易上手,时间不够充裕,仅仅了解html的相关知识也是够用的。
2023-11-14 14:44:49203 
 电子发烧友App
电子发烧友App






















 工商网监
工商网监
评论