 电子发烧友App
电子发烧友App


对于GNU Make或许很多Windows开发的程序员并不是很了解,因为Windows中的很多集成开发环境(IDE)都帮我们做了这件事。但是作为一个专业从事Linux嵌入式开发的程序员就必须要了解GNU Make,会不会使用GNU Make从一定角度上反应了一个人是否具备大型工程能力。本文主要围绕Make命令展开,介绍Linux下Make的使用以及Makefile的语法和使用Make进行源码安装。
一、什么是GNU Make
GNU Make是一个控制从程序的源文件中生成程序的可执行文件和其他非源文件的工具。
Make可以从一个名为Makefile的文件中获得如何构建程序的知识,该文件列出了每个非源文件以及如何从其他文件计算它。当你编写一个程序时,你应该为它编写一个Makefile文件,这样就可以使用Make来编译和安装这个程序。
二、如何获取Make
Make可以在GNU的主要FTP服务器上找到:http : //ftp.gnu.org/gnu/make/ (通过HTTP)和 ftp://ftp.gnu.org/gnu/make/ (通过FTP)。它也可以在GNU镜像列表上找到; 请尽可能GNU的镜像列表。
三、为什么需要Make
任何一种技能或知识都是源之于某种社会需求,那为什么要用Make呢?当项目源文件很少的时候,我们也许还可以手动使用gcc命令来进行编译,但是当项目发展到一个庞大的规模时,再手动敲gcc命令去编译就变得不可能的事情。所以呢,在这样的历史背景下,就出现了一位大牛(斯图亚特·费尔德曼),在1977年贝尔实验室制作了这样一个软件,它的名字就叫做Make。所以实际开发中,我们在编译大型项目的时候往往会使用Make进行编译,为此我们还需要了解Make软件所依赖的Makefile规则文件。
四、Makefile
Makefile 文件需要按照某种语法进行编写,文件中需要说明如何编译各个源文件并连接生成可执行文件,并要求定义源文件之间的依赖关系。Makefile的语法还是略微有些复杂,因篇幅有限,本文只能简述Makefile的编写原则。
(1)Makefile的组成部分
Makefile包含五个东西:显示规则,隐式规则,变量定义,文件指示,注释。
《1》显式规则,显式规则说明了,如何生成一个或多的的目标文件。这是由Makefile的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
《2》隐式规则,由于我们的make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写Makefile,这是由make所支持的。
《3》变量的定义,在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点你C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
《4》文件指示,其包括了三个部分,一个是在一个Makefile中引用另一个Makefile,就像C语言中的include一样;另一个是指根据某些情况指定Makefile中的有效部分,就像C语言中的预编译#if一样;还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
《5》注释,Makefile中只有行注释,和UNIX的Shell脚本一样,其注释是用“#”字符,这个就像C/C++中的“//”一样。如果你要在你的Makefile中使用“#”字符,可以用反斜框进行转义,如:“/#”。
(2) Makefile的规则
我们先来粗略地看一看Makefile的规则。
target.。。 : prerequisites 。。.
command
。。.
。。.
target也就是一个目标文件,可以是Object File,也可以是执行文件。还可以是一个标签(Label),对于标签这种特性,在后续的“伪目标”章节中会有叙述。
prerequisites就是,要生成那个target所需要的文件或是目标。
command也就是make需要执行的命令。(一定要以Tab键作为开头)
这是一个文件的依赖关系,也就是说,target这一个或多个的目标文件依赖于prerequisites中的文件,其生成规则定义在command中。说白一点就是说,prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。这就是Makefile的规则。也就是Makefile中核心的内容。
(3)Makefile之模式规则
模式规则其实也是普通规则,但它使用了如%这样的通配符。如下面的例子:
此规则描述了一个.o文件如何由对应的.c文件创建。规则的命令行中使用了自动化变量“$《”和“$@”,其中自动化变量“$《”代表规则的依赖,“$@”代表规则的目标。此规则在执行时,命令行中的自动化变量将根据实际的目标和依赖文件取对应值。
其含义是,字指出了从所有的.c文件生成相应的.o文件的规则。如果要生成的目标是”a.o b.o”,那么 %.c”就是”a.c b.c”。
在模式规则中,目标的定义需要有“%”字符。“%”定义对文件名的匹配,表示任意长度的非空字符串。在依赖目标中同样可以使用“%”,只是依赖目标中“%”的取值,取决于其目标。
注意:模式规则中“%”的展开和变量与函数的展开是有区别的,“%”的展开发生在变量和函数的展开之后。变量和函数的展开发生在make载入Makefile时,而“%”的展开则发生在运行时。
《1》 自动化变量
自动化变量只应出现在规则的命令中。
变量含义
$@表示规则中的所有目标文件的集合。在模式规则中如果有多个目标,“$@”就是匹配于目标中模式定义的集合
$%仅当目标是函数库文件时,表示规则中的目标成员名,如果目标不是函数库文件(UNIX下是.a,Windows是.lib),其值为空。
$《依赖目标中的第一个目标名字,如果依赖目标是以模式(即”%“)定义的,则”$《”是符合模式的一系列的文件集
$?所有比目标新的依赖目标的集合,以空格分隔
$^所有依赖目标的集合,以空格分隔。如如果在依赖目标中有多个重复的,则自动去除重复的依赖目标,只保留一份
$+同”$^”,也是所有依赖目标的集合,只是它不去除重复的依赖目标。
$*目标模式中“%”及其之前的部分
$(@D)“$@”的目录部分(不以斜杠作为结尾),如果”$@”中没有包含斜杠,其值为“。”(当前目录)
$(@F)“$@”的文件部分,相当于函数”$(notdir $@)”
$(*D)同”$(@D)”,取文件的目录部分
$(*F)同”$(@F)”,取文件部分,但不取后缀名
$(%D)函数包文件成员的目录部分
$(%F)函数包文件成员的文件名部分
$(《D)依赖目标中的第一个目标的目录部分
$(《F)依赖目标中的第一个目标的文件名部分
$(^D)所有依赖目标文件中目录部分(无相同的)
$(^F)所有依赖目标文件中文件名部分(无相同的)
$(+D)所有依赖目标文件中的目录部分(可以有相同的)
$(+F)所有依赖目标文件中的文件名部分(可以有相同的)
$(?D)所有被更新文件的目录部分
$(?F)所有被更新文件的文件名部分
《2》$VAR和$$VAR的区别:
makefile文件中的规则绝大部分都是使用shell命令来实现的,这里就涉及到了变量的使用,包括makefile中的变量和shell命令范畴内的变量。在makefile的规则命令行中使用$var就是在命令中引用makefile的变量,这里仅仅是读取makefile的变量然后扩展开,将其值作为参数传给了一个shell命令;而$$var是在访问一个shell命令内定义的变量,而非makefile的变量。如果某规则有n个shell命令行构成,而相互之间没有用‘;’和‘’连接起来的话,就是相互之间没有关联的shell命令,相互之间也不能变量共享。
(4)Makefile之伪目标
使用其原因一:避免和同名文件冲突
在现实中难免存在所定义的目标与所存在的目标是同名的,采用Makefile如何处理这种情况呢?Makefile中的假目标(phony target)可以解决这个问题。
假目标可以使用.PHONY关键字进行声明,对于假目标,可以想象,因为不依赖于某文件,make该目标的时候,其所在规则的命令都会被执行。
如果编写一个规则,并不产生目标文件,则其命令在每次make 该目标时都执行。
例如:
clean:
rm *.o temp
因为“rm”命令并不产生“clean”文件,则每次执行“make clean”的时候,该命令都会执行。如果目录中出现了“clean”文件,则规则失效了:没有依赖文件,文件“clean”始终是新的,命令永远不会执行;为避免这个问题,可使用“.PHONY”指明该目标。如:
.PHONY : clean
这样执行“make clean”会无视“clean”文件存在与否。
已知phony 目标并非是由其它文件生成的实际文件,make 会跳过隐含规则搜索。这就是声明phony 目标会改善性能的原因,即使你并不担心实际文件存在与否。
完整的例子如下:
.PHONY : clean
clean :
rm *.o temp
使用其原因二:提高执行make的效率
当一个目标被声明为伪目标后,make在执行此规则时不会试图去查找隐含规则来创建这个目标。这样也提高了make的执行效率,同时我们也不用担心由于目标和文件名重名而使我们的期望失败。
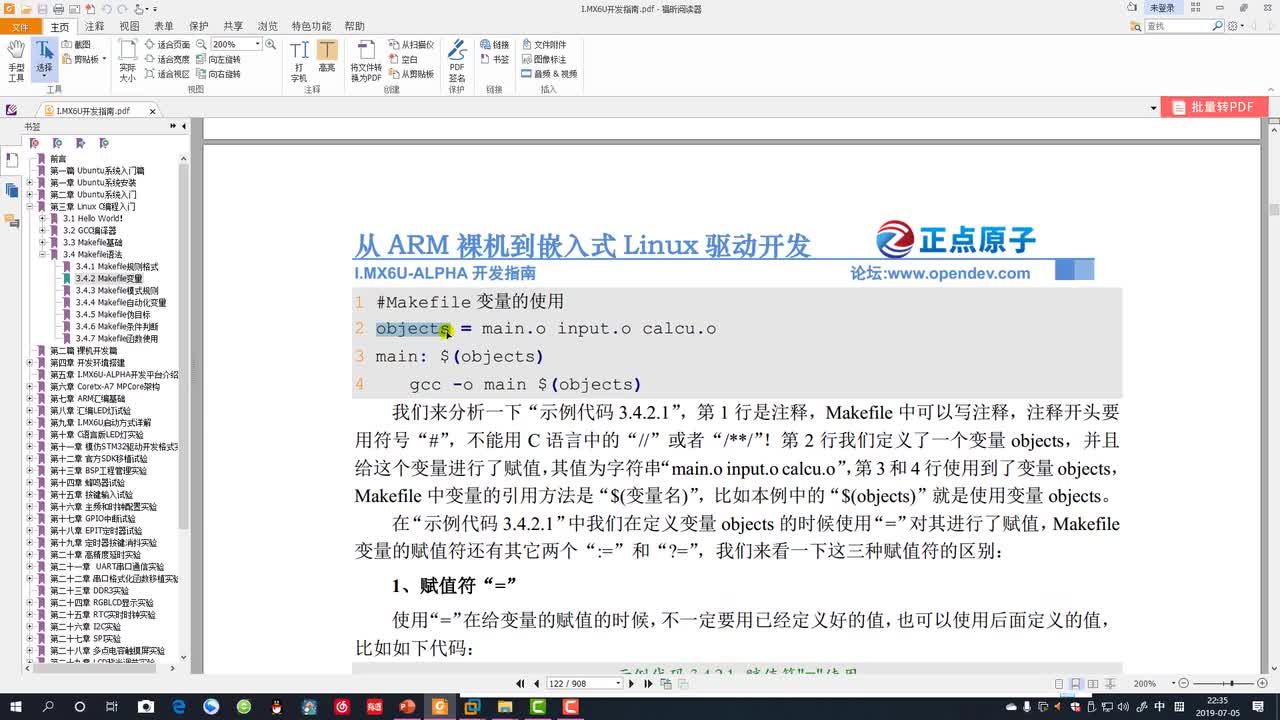
(5)Makefile的赋值
[=]和[:=]符号的区别。
=
可以先使用后定义,这就导致makefile在全部展开后才能决定变量的值。
有可能出现循环递归,无法暂开的问题。
:=
必须先定义然后再使用,在当前的位置就可以决定变量的值。
?=
相当于选择疑问句,如果前面的变量没被赋值,那就做赋值操作
+=
相当于递加操作
(6)Makefile之执行过程
1. 依次读取变量“MAKEFILES”定义的makefile文件列表
2. 读取工作目录下的makefile文件(根据命名的查找顺序“GNUmakefile”,“makefile”,“Makefile”,首先找到那个就读取那个)
3. 依次读取工作目录makefile文件中使用指示符“include”包含的文件
4. 查找重建所有已读取的makefile文件的规则(如果存在一个目标是当前读取的某一个makefile文件,则执行此规则重建此makefile文件,完成以后从第一步开始重新执行)
5. 初始化变量值并展开那些需要立即展开的变量和函数并根据预设条件确定执行分支
6. 根据“终极目标”以及其他目标的依赖关系建立依赖关系链表
7. 执行除“终极目标”以外的所有的目标的规则(规则中如果依赖文件中任一个文件的时间戳比目标文件新,则使用规则所定义的命令重建目标文件)
8. 执行“终极目标”所在的规则
五、使用Make进行源码安装
(1)正常的编译安装/卸载:
源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(make install)。
configure文件是一个可执行的脚本文件,它有很多选项,在待安装的源码目录下使用命令。/configure –help可以输出详细的选项列表。
其中--prefix选项是配置安装目录,如果不配置该选项,安装后可执行文件默认放在/usr /local/bin,库文件默认放在/usr/local/lib,配置文件默认放在/usr/local/etc,其它的资源文件放在/usr /local/share,比较凌乱。
如果配置了--prefix,如:
$ 。/configure --prefix=/usr/local/test
安装后的所有资源文件都会被放在/usr/local/test目录中,不会分散到其他目录。
使用--prefix选项的另一个好处是方便卸载软件或移植软件;当某个安装的软件不再需要时,只须简单的删除该安装目录,就可以把软件卸载得干干净净;而移植软件只需拷贝整个目录到另外一个机器即可(相同的操作系统下)。
当然要卸载程序,也可以在原来的make目录下用一次make uninstall,但前提是Makefile文件有uninstall命令(nodejs的源码包里有uninstall命令,测试版本v0.10.35)。
(2)卸载:
如果没有配置--prefix选项,源码包也没有提供make uninstall,则可以通过以下方式可以完整卸载:
找一个临时目录重新安装一遍,如:
$ 。/configure --prefix=/tmp/to_remove && make install
然后遍历/tmp/to_remove的文件,删除对应安装位置的文件即可(因为/tmp/to_remove里的目录结构就是没有配置--prefix选项时的目录结构)。
当下载了源码就可以按照此种方法,就可以进行软件的安装和卸载。
六、总结
关于Makefile的用法,我们今天就讨论到这里,对于一个Linux程序员来说Makefile的作用和重要。对于程序的编译以及程序员对项目的了解有很大的帮助。


















 工商网监
工商网监
评论