 电子发烧友App
电子发烧友App


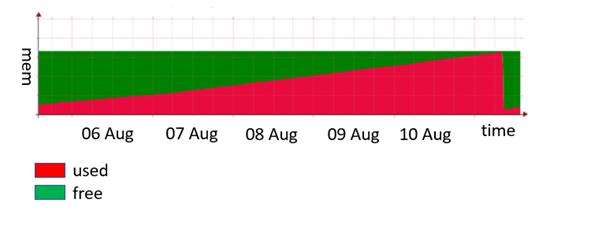
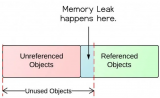
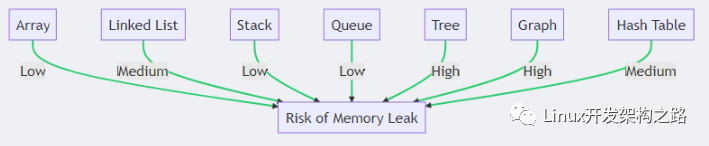
在实际的项目中,最难缠的问题就是内存泄漏,当然还有panic之类的,内存泄漏分为两部分用户空间的和内核空间的.我们就分别从这两个层面分析一下.
用户空间查看内存泄漏和解决都相对简单。定位问题的方法和工具也很多相对容易.我们来看看.
1. 查看内存信息
cat /proc/meminfo、free、cat /proc/slabinfo等
2. 查看进程的状态信息
top、ps、cat /proc/pid/maps/status/fd等
通常我们定位问题先在shell下ps查看当前运行进程的状态,嵌入式上可能显示的信息会少一些.
点击(此处)折叠或打开
root@hos-machine:~# ps -uaxw
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 119872 3328 ? Ss 8月10 0:24 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 8月10 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 8月10 0:44 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 8月10 0:00 [kworker/0:0H]
root 7 0.0 0.0 0 0 ? S 8月10 3:50 [rcu_sched]
root 8 0.0 0.0 0 0 ? S 8月10 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 8月10 0:12 [migration/0]
root 10 0.0 0.0 0 0 ? S 8月10 0:01 [watchdog/0]
root 11 0.0 0.0 0 0 ? S 8月10 0:01 [watchdog/1]
root 12 0.0 0.0 0 0 ? S 8月10 0:12 [migration/1]
root 13 0.0 0.0 0 0 ? S 8月10 1:18 [ksoftirqd/1]
root 15 0.0 0.0 0 0 ? S< 8月10 0:00 [kworker/1:0H]
root 16 0.0 0.0 0 0 ? S 8月10 0:01 [watchdog/2]
root 17 0.0 0.0 0 0 ? S 8月10 0:12 [migration/2]
root 18 0.0 0.0 0 0 ? S 8月10 1:19 [ksoftirqd/2]
root 20 0.0 0.0 0 0 ? S< 8月10 0:00 [kworker/2:0H]
root 21 0.0 0.0 0 0 ? S 8月10 0:01 [watchdog/3]
root 22 0.0 0.0 0 0 ? S 8月10 0:13 [migration/3]
root 23 0.0 0.0 0 0 ? S 8月10 0:41 [ksoftirqd/3]
root 25 0.0 0.0 0 0 ? S< 8月10 0:00 [kworker/3:0H]
root 26 0.0 0.0 0 0 ? S 8月10 0:00 [kdevtmpfs]
root 27 0.0 0.0 0 0 ? S< 8月10 0:00 [netns]
root 329 0.0 0.0 0 0 ? S< 8月10 0:00 [ext4-rsv-conver]
root 339 0.0 0.0 0 0 ? S< 8月10 0:05 [kworker/1:1H]
root 343 0.0 0.0 0 0 ? S< 8月10 0:11 [kworker/3:1H]
root 368 0.0 0.0 39076 1172 ? Ss 8月10 0:10 /lib/systemd/systemd-journald
root 373 0.0 0.0 0 0 ? S 8月10 0:00 [kauditd]
root 403 0.0 0.0 45772 48 ? Ss 8月10 0:01 /lib/systemd/systemd-udevd
root 444 0.0 0.0 0 0 ? S< 8月10 0:09 [kworker/2:1H]
systemd+ 778 0.0 0.0 102384 516 ? Ssl 8月10 0:04 /lib/systemd/systemd-timesyncd
root 963 0.0 0.0 191264 8 ? Ssl 8月10 0:00 /usr/bin/vmhgfs-fuse -o subtype=vmhgfs-fuse,allow_other /mnt/hgfs
root 987 9.6 0.0 917024 0 ? Ssl 8月10 416:08 /usr/sbin/vmware-vmblock-fuse -o subtype=vmware-vmblock,default_permi
root 1007 0.2 0.1 162728 3084 ? Sl 8月10 10:14 /usr/sbin/vmtoolsd
root 1036 0.0 0.0 56880 844 ? S 8月10 0:00 /usr/lib/vmware-vgauth/VGAuthService -s
root 1094 0.0 0.0 203216 388 ? Sl 8月10 1:48 ./ManagementAgentHost
root 1100 0.0 0.0 28660 136 ? Ss 8月10 0:02 /lib/systemd/systemd-logind
message+ 1101 0.0 0.1 44388 2608 ? Ss 8月10 0:21 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile
root 1110 0.0 0.0 173476 232 ? Ssl 8月10 0:54 /usr/sbin/thermald --no-daemon --dbus-enable
root 1115 0.0 0.0 4400 28 ? Ss 8月10 0:14 /usr/sbin/acpid
root 1117 0.0 0.0 36076 568 ? Ss 8月10 0:01 /usr/sbin/cron -f
root 1133 0.0 0.0 337316 976 ? Ssl 8月10 0:00 /usr/sbin/ModemManager
root 1135 0.0 0.2 634036 5340 ? Ssl 8月10 0:19 /usr/lib/snapd/snapd
root 1137 0.0 0.0 282944 392 ? Ssl 8月10 0:06 /usr/lib/accountsservice/accounts-daemon
syslog 1139 0.0 0.0 256396 352 ? Ssl 8月10 0:04 /usr/sbin/rsyslogd -n
avahi 1145 0.0 0.0 44900 1092 ? Ss 8月10 0:11 avahi-daemon: running [hos-machine.local]
这个是ubuntu系统里的信息比较详细,我们可以很清晰看到VMZ和RSS的对比信息.VMZ就是这个进程申请的虚拟地址空间,而RSS是这个进程占用的实际物理内存空间.
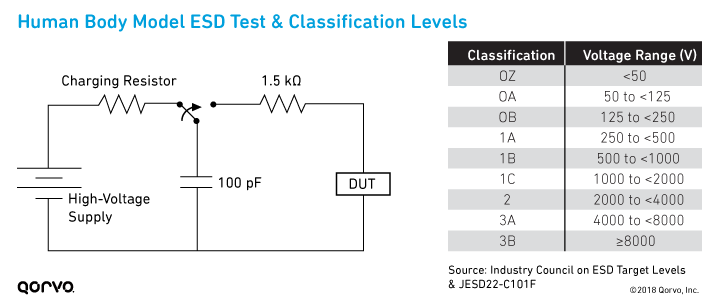
通常一个进程如果有内存泄露VMZ会不断增大,相对的物理内存也会增加,如果是这样一般需要检查malloc/free是否匹配。根据进程ID我们可以查看详细的VMZ相关的信息。例:
点击(此处)折叠或打开
root@hos-machine:~# cat /proc/1298/status
Name: sshd
State: S (sleeping)
Tgid: 1298
Ngid: 0
Pid: 1298
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 128
Groups:
NStgid: 1298
NSpid: 1298
NSpgid: 1298
NSsid: 1298
VmPeak: 65620 kB
VmSize: 65520 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 5480 kB
VmRSS: 5452 kB
VmData: 580 kB
VmStk: 136 kB
VmExe: 764 kB
VmLib: 8316 kB
VmPTE: 148 kB
VmPMD: 12 kB
VmSwap: 0 kB
HugetlbPages: 0 kB
Threads: 1
SigQ: 0/7814
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000001000
SigCgt: 0000000180014005
CapInh: 0000000000000000
CapPrm: 0000003fffffffff
CapEff: 0000003fffffffff
CapBnd: 0000003fffffffff
CapAmb: 0000000000000000
Seccomp: 0
Cpus_allowed: ffffffff,ffffffff
Cpus_allowed_list: 0-63
Mems_allowed: 00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 1307
nonvoluntary_ctxt_switches: 203
如果我们想查看这个进程打开了多少文件可以
ls -l /proc/1298/fd/* | wc
查看进程详细的内存映射信息
cat /proc/7393/maps
我们看一下meminfo各个注释:参考documentation/filesystem/proc.txt
MemTotal: Total usable ram (i.e. physical ram minus a few reserved bits and the kernel binary code)
MemFree: The sum of LowFree+HighFree
Buffers: Relatively temporary storage for raw disk blocks shouldn't get tremendously large (20MB or so)
Cached: in-memory cache for files read from the disk (the pagecache). Doesn't include
SwapCached SwapCached: Memory that once was swapped out, is swapped back in but still also is in the swapfile (if memory is needed it
doesn't need to be swapped out AGAIN because it is already in the swapfile. This saves I/O)
Active: Memory that has been used more recently and usually not reclaimed unless absolutely necessary.
Inactive: Memory which has been less recently used. It is more eligible to be reclaimed for other purposes
HighTotal:
HighFree: Highmem is all memory above ~860MB of physical memory Highmem areas are for use by userspace programs, or
for the pagecache. The kernel must use tricks to access this memory, making it slower to access than lowmem.
LowTotal:
LowFree: Lowmem is memory which can be used for everything that highmem can be used for, but it is also available for the
kernel's use for its own data structures. Among many other things, it is where everything from the Slab is
allocated. Bad things happen when you're out of lowmem.
SwapTotal: total amount of swap space available
SwapFree: Memory which has been evicted from RAM, and is temporarily on the disk
Dirty: Memory which is waiting to get written back to the disk
Writeback: Memory which is actively being written back to the disk
AnonPages: Non-file backed pages mapped into userspace page tables
AnonHugePages: Non-file backed huge pages mapped into userspace page tables
Mapped: files which have been mmaped, such as libraries
Slab: in-kernel data structures cache
SReclaimable: Part of Slab, that might be reclaimed, such as caches
SUnreclaim: Part of Slab, that cannot be reclaimed on memory pressure
PageTables: amount of memory dedicated to the lowest level of page tables.
NFS_Unstable: NFS pages sent to the server, but not yet committed to stable storage
Bounce: Memory used for block device "bounce buffers"
WritebackTmp: Memory used by FUSE for temporary writeback buffers
CommitLimit: Based on the overcommit ratio ('vm.overcommit_ratio'), this is the total amount of memory currently available to
be allocated on the system. This limit is only adhered to if strict overcommit accounting is enabled (mode 2 in
'vm.overcommit_memory').
The CommitLimit is calculated with the following formula: CommitLimit = ('vm.overcommit_ratio' * Physical RAM) + Swap
For example, on a system with 1G of physical RAM and 7G
of swap with a `vm.overcommit_ratio` of 30 it would
yield a CommitLimit of 7.3G.
For more details, see the memory overcommit documentation in vm/overcommit-accounting.
Committed_AS: The amount of memory presently allocated on the system. The committed memory is a sum of all of the memory which
has been allocated by processes, even if it has not been
"used" by them as of yet. A process which malloc()'s 1G
of memory, but only touches 300M of it will only show up as using 300M of memory even if it has the address space
allocated for the entire 1G. This 1G is memory which has been "committed" to by the VM and can be used at any time
by the allocating application. With strict overcommit enabled on the system (mode 2 in 'vm.overcommit_memory'),
allocations which would exceed the CommitLimit (detailed above) will not be permitted. This is useful if one needs
to guarantee that processes will not fail due to lack of memory once that memory has been successfully allocated.
VmallocTotal: total size of vmalloc memory area
VmallocUsed: amount of vmalloc area which is used
VmallocChunk: largest contiguous block of vmalloc area which is free
我们只需要关注几项就ok. buffers/cache/slab/active/anonpages
Active= Active(anon) + Active(file) (同样Inactive)
AnonPages: Non-file backed pages mapped into userspace page tables
buffers和cache的区别注释说的很清楚了.
有时候不是内存泄露,同样也会让系统崩溃,比如cache、buffers等占用的太多,打开太多文件,而等待系统自动回收是一个非常漫长的过程.
从proc目录下的meminfo文件了解到当前系统内存的使用情况汇总,其中可用的物理内存=memfree+buffers+cached,当memfree不够时,内核会通过
回写机制(pdflush线程)把cached和buffered内存回写到后备存储器,从而释放相关内存供进程使用,或者通过手动方式显式释放cache内存
点击(此处)折叠或打开
drop_caches
Writing to this will cause the kernel to drop clean caches, dentries and inodes from memory, causing that memory to become free.
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes:
echo 3 > /proc/sys/vm/drop_caches
As this is a non-destructive operation and dirty objects are not freeable, the user should run `sync`first
用户空间内存检测也可以通过mtrace来检测用法也非常简单,之前文章我们有提到过. 包括比较有名的工具valgrind、以及dmalloc、memwatch等.各有特点.
内核内存泄露的定位比较复杂,先判断是否是内核泄露了,然后在具体定位什么操作,然后再排查一些可疑的模块,内核内存操作基本都是kmalloc
即通过slab/slub/slob机制,所以如果meminfo里slab一直增长那么很有可能是内核的问题.我们可以更加详细的查看slab信息
cat /proc/slabinfo
如果支持slabtop更好,基本可以判断内核是否有内存泄漏,并且是在操作什么对象的时候发生的。
点击(此处)折叠或打开
cat /proc/slabinfo
slabinfo - version: 2.1
# name : tunables : slabdata
fuse_request 0 0 288 28 2 : tunables 0 0 0 : slabdata 0 0 0
fuse_inode 0 0 448 18 2 : tunables 0 0 0 : slabdata 0 0 0
fat_inode_cache 0 0 424 19 2 : tunables 0 0 0 : slabdata 0 0 0
fat_cache 0 0 24 170 1 : tunables 0 0 0 : slabdata 0 0 0
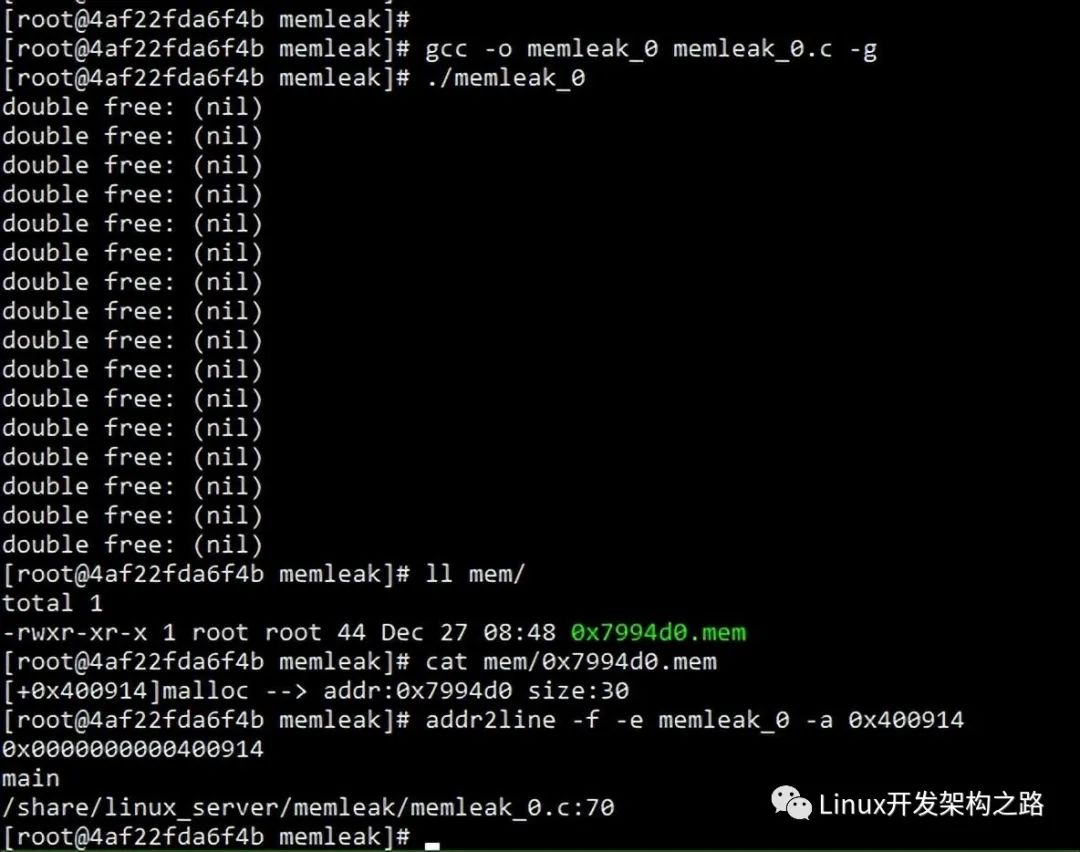
在内核的配置中里面已经支持了一部分memleak自动检查的选项,可以打开来进行跟踪调试.
这里没有深入的东西,算是抛砖引玉吧~.




















 工商网监
工商网监
评论