 电子发烧友App
电子发烧友App


一:前言
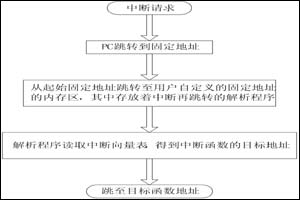
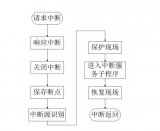
在前一个专题里曾分析过所有IRQ中断处理流程,经过SAVE_ALL保存硬件环境后,都会进入do_IRQ()进行处理,今天接着分析do_IRQ()处理的相关东西.分为两部中断处理程序与软中断两个大的部份进行介绍.
二:中断处理程序
在驱动程序中,通常使用request_irq()来注册中断处理程序.我们先从注册中断处理程序的实现说起.
/*
irq:可断号
handler:中断处理程序
irqflags:中断处理标志.SA_SHIRQ:共享中断线 SA_INTERRUPT:快速处理中断
必须在关中断的情况下运行.SA_SAMPLE_RANDOM:该中断可能用于产生一个随机数
devname dev_id:设备名称与ID
*/
int request_irq(unsigned int irq,
irqreturn_t (*handler)(int, void *, struct pt_regs *),
unsigned long irqflags,
const char * devname,
void *dev_id)
{
int retval;
#if 1
if (irqflags & SA_SHIRQ) {
if (!dev_id)
printk("Bad boy: %s (at 0x%x) called us without a dev_id!\n", devname, (&irq)[-1]);
}
#endif
//参数有效性判断
if (irq >= NR_IRQS)
return -EINVAL;
if (!handler)
return -EINVAL;
// 分配一个irqaction
action = (struct irqaction *)
kmalloc(sizeof(struct irqaction), GFP_ATOMIC);
if (!action)
return -ENOMEM;
action->handler = handler;
action->flags = irqflags;
cpus_clear(action->mask);
action->name = devname;
action->next = NULL;
action->dev_id = dev_id;
//将创建并初始化完在的action加入irq_desc[NR_IRQS]
retval = setup_irq(irq, action);
if (retval)
kfree(action);
return retval;
}
上面涉及到的irqaction结构与irq_desc[]的关系我们在上一节我们已经详细分析过了,这里不再赘述.
转进setup_irq():
int setup_irq(unsigned int irq, struct irqaction * new)
{
int shared = 0;
unsigned long flags;
struct irqaction *old, **p;
irq_desc_t *desc = irq_desc + irq;
//如果hander == no_irq_type:说明中断控制器不支持该IRQ线
if (desc->handler == &no_irq_type)
return -ENOSYS;
sif (new->flags & SA_SAMPLE_RANDOM) {
rand_initialize_irq(irq);
}
/*
* The following block of code has to be executed atomically
*/
spin_lock_irqsave(&desc->lock,flags);
p = &desc->action;
if ((old = *p) != NULL) {
//判断这条中断线上的中断处理程序是否允许SHARE
/* Can't share interrupts unless both agree to */
if (!(old->flags & new->flags & SA_SHIRQ)) {
spin_unlock_irqrestore(&desc->lock,flags);
return -EBUSY;
}
/* add new interrupt at end of irq queue */
do {
p = &old->next;
old = *p;
} while (old);
shared = 1;
}
//将其添加到中断处理函数链的末尾
*p = new;
//如果这一条线还没有被占用,初始化这条中断线
//包含清标志,在8259A上启用这条中断线
if (!shared) {
desc->depth = 0;
desc->status &= ~(IRQ_DISABLED | IRQ_AUTODETECT | IRQ_WAITING | IRQ_INPROGRESS);
desc->handler->startup(irq);
}
spin_unlock_irqrestore(&desc->lock,flags);
//在proc下建立相关的文件
register_irq_proc(irq);
return 0;
}
现在知道怎么打一个中断处理程序挂到irq_desc[NR_IRQS]数组上了,继续分析中断处理中如何调用中断处理函数.从我们开篇时说到的do_IRQ()说起.
asmlinkage unsigned int do_IRQ(struct pt_regs regs)
{
//屏蔽高位,取得中断号
int irq = regs.orig_eax & 0xff; /* high bits used in ret_from_ code */
//取得中断号对应的desc结构
irq_desc_t *desc = irq_desc + irq;
struct irqaction * action;
unsigned int status;
irq_enter();
// 调试用,忽略
#ifdef CONFIG_DEBUG_STACKOVERFLOW
/* Debugging check for stack overflow: is there less than 1KB free? */
{
long esp;
__asm__ __volatile__("andl %%esp,%0" :
"=r" (esp) : "0" (THREAD_SIZE - 1));
if (unlikely(esp < (sizeof(struct thread_info) + STACK_WARN))) {
printk("do_IRQ: stack overflow: %ld\n",
esp - sizeof(struct thread_info));
dump_stack();
}
}
#endif
//更新统计计数
kstat_this_cpu.irqs[irq]++;
spin_lock(&desc->lock);
//给8259 回一个ack.回ack之后,通常中断控制会屏蔽掉此条IRQ线
desc->handler->ack(irq);
//清除IRQ_REPLAY IRQ_WAITING标志
status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
//设置IRQ_PENDING:表示中断被应答,但没有真正被处理
status |= IRQ_PENDING; /* we _want_ to handle it */
/*
* If the IRQ is disabled for whatever reason, we cannot
* use the action we have.
*/
action = NULL;
//中断被屏蔽或者正在处理
//IRQ_DIASBLED:中断被禁用
//IRQ_INPROGRESS:这个类型的中断已经在被另一个CPU处理了
if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
action = desc->action;
status &= ~IRQ_PENDING; /* we commit to handling */
//置位,表示正在处理中...
status |= c; /* we are handling it */
}
desc->status = status;
//没有挂上相应的中断处理例程或者不满足条件
if (unlikely(!action))
goto out;
for (;;) {
irqreturn_t action_ret;
u32 *isp;
union irq_ctx * curctx;
union irq_ctx * irqctx;
curctx = (union irq_ctx *) current_thread_info();
irqctx = hardirq_ctx[smp_processor_id()];
spin_unlock(&desc->lock);
//通常curctx == irqctx.除非中断程序使用独立的4K堆栈.
if (curctx == irqctx)
action_ret = handle_IRQ_event(irq, ®s, action);
else {
/* build the stack frame on the IRQ stack */
isp = (u32*) ((char*)irqctx + sizeof(*irqctx));
irqctx->tinfo.task = curctx->tinfo.task;
irqctx->tinfo.real_stack = curctx->tinfo.real_stack;
irqctx->tinfo.virtual_stack = curctx->tinfo.virtual_stack;
irqctx->tinfo.previous_esp = current_stack_pointer();
*--isp = (u32) action;
*--isp = (u32) ®s;
*--isp = (u32) irq;
asm volatile(
" xchgl %%ebx,%%esp \n"
" call handle_IRQ_event \n"
" xchgl %%ebx,%%esp \n"
: "=a"(action_ret)
: "b"(isp)
: "memory", "cc", "edx", "ecx"
);
}
spin_lock(&desc->lock);
//调试用,忽略
if (!noirqdebug)
note_interrupt(irq, desc, action_ret, ®s);
if (curctx != irqctx)
irqctx->tinfo.task = NULL;
//如果没有要处理的中断了,退出
if (likely(!(desc->status & IRQ_c)))
break;
//又有中断到来了,继续处理
desc->status &= ~c;
}
//处理完了,清除IRQ_INPROGRESS标志
desc->status &= ~IRQ_INPROGRESS;
out:
/*
* The ->end() handler has to deal with interrupts which got
* disabled while the handler was running.
*/
//处理完了,调用中断控制器的end.通常此函数会使中断控制器恢复IRQ线中断
desc->handler->end(irq);
spin_unlock(&desc->lock);
//irq_exit():理论上中断处理完了,可以处理它的下半部了
irq_exit();
return 1;
}
这段代码比较简单,但里面几个标志让人觉的很迷糊,列举如下:
IRQ_DISABLED:相应的IRQ被禁用.既然中断线被禁用了,也就不会产生中断,进入do_IRQ()了?因为电子器件的各种原因可能会产生 “伪中断”上报给CPU.
IRQ_PENDING:CPU收到这个中断信号了,已经给出了应答,但并末对其进行处理.回顾上面的代码,进入do_IRQ后,发送ack,再设置此标志.
IRQ_ INPROGRESS:表示这条IRQ线的中断正在被处理.为了不弄脏CPU的高速缓存.把相同IRQ线的中断放在一起处理可以提高效率,且使中断处理程序不必重入
举例说明:如果CPU A接收到一个中断信号.回一个ACK,设置c,假设此时末有这个中断线的中断处理程序在处理,继而会将标志位设为IRQ_ INPROGRESS.转去中断处理函数执行.如果此时,CPU B检测到了这条IRQ线的中断信号.它会回一个ACK.设置
IRQ_PENDING.但时此时这条IRQ线的标志为IRQ_ INPROGRESS.所以,它会进经过goto out退出.如果cpu A执行完了中断处理程序,判断它的标志线是否为IRQ_PENDING.因为CPU B已将其设为了IRQ_PENDING.所以继续循环一次.直到循环完后,清除IRQ_INPROGRESS标志
注意上述读写标志都是加锁的.linux采用的这个方法,不能不赞一个 *^_^*
继续看代码:
asmlinkage int handle_IRQ_event(unsigned int irq,
struct pt_regs *regs, struct irqaction *action)
{
int status = 1; /* Force the "do bottom halves" bit */
int ret, retval = 0;
//如果没有设置SA_INTERRUPT.将CPU 中断打开
//应该尽量的避免CPU关中断的情况,因为CPU屏弊本地中断,会使
//中断丢失
if (!(action->flags & SA_INTERRUPT))
local_irq_enable();
//遍历运行中断处理程序
do {
ret = action->handler(irq, action->dev_id, regs);
if (ret == IRQ_HANDLED)
status |= action->flags;
retval |= ret;
action = action->next;
} while (action);
if (status & SA_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
//关中断
local_irq_disable();
return retval;
}
可能会有这样的疑问.如果在一根中断线上挂上了很多个中断处理程序,会不会使这一段程序的效率变得很低下呢?事实上,我们在写驱动程序的过程中,都会首先在中断处理程序里判断设备名字与设备ID,只有条件符合的设备中断才会变处理.
三:软中断
为了提高中断的响应速度,很多操作系统都把中断分成了两个部份,上半部份与下半部份.上半部份通常是响应中断,并把中断所得到的数据保存进下半部.耗时的操作一般都会留到下半部去处理.
接下来,我们看一下软中断的处理模型:
Start_kernel() à softirq_init();
在softirq_init()中会注册两个常用类型的软中断,看具体代码:
void __init softirq_init(void)
{
open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
}
//参数含义:nr:软中断类型 action:软中断处理函数 data:软中断处理函数参数
void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
{
softirq_vec[nr].data = data;
softirq_vec[nr].action = action;
}
static struct softirq_action softirq_vec[32] __cacheline_aligned_in_smp;
struct softirq_action
{
void (*action)(struct softirq_action *);
void *data;
};
在上面的代码中,我们可以看到:open_softirq()中.其实就是对softirq_vec数组的nr项赋值.softirq_vec是一个32元素的数组,实际上linux内核只使用了六项. 如下示:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
SCSI_SOFTIRQ,
TASKLET_SOFTIRQ
}
另外.如果使软中断能被CPU调度,还得要让它激活才可以.激活所使用的函数为__raise_softirq_irqoff()
代码如下:
#define __raise_softirq_irqoff(nr) do { local_softirq_pending() |= 1UL << (nr); } while (0)
这个宏使local_softirq_pending的nr位置1
好了,经过open_softirq()à local_softirq_pending()后,我们来看下软中断怎么被CPU调度.
继续上面中断处理的代码.在处理完硬件中断后,会调用irq_exit().这就是软中断的入口点了,我们来看下
#define irq_exit() \
do { \
preempt_count() -= IRQ_EXIT_OFFSET; \
//注意了,软中断不可以在硬件中断上下文或者是在软中断环境中使用哦 ^_^
//softirq_pending()的判断,注意我们上面分析过的_raise_softirqoff().它判断当前cpu有没有激活软中断
if (!in_interrupt() && softirq_pending(smp_processor_id())) \
do_softirq(); \
preempt_enable_no_resched(); \
} while (0)
跟踪进do_softirq()
asmlinkage void do_softirq(void)
{
__u32 pending;
unsigned long flags;
//在硬件中断环境中,退出
if (in_interrupt())
return;
//禁止本地中断,不要让其受中断的影响
local_irq_save(flags);
pending = local_softirq_pending();
//是否有软中断要处理?
if (pending)
__do_softirq();
//恢复CPU中断
local_irq_restore(flags);
}
转入__do_softirq()
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending();
//禁止软中断,不允许软中断嵌套
local_bh_disable();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
//把挂上去的软中断清除掉,因为我们在这里会全部处理完
local_softirq_pending() = 0;
//开CPU中断
local_irq_enable();
//softirq_vec:32元素数组
h = softirq_vec;
//依次处理挂上去的软中断
do {
if (pending & 1) {
//调用软中断函数
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
pending >>= 1;
} while (pending);
//关CPU 中断
local_irq_disable();
pending = local_softirq_pending();
//在规定次数内,如果有新的软中断了,可以继续在这里处理完
if (pending && --max_restart)
goto restart;
//依然有没有处理完的软中断,为了提高系统响应效率,唤醒softirqd进行处理
if (pending)
wakeup_softirqd();
//恢复软中断
__local_bh_enable();
}
从上面的处理流程可以看到,软中断处理就是调用open_ softirq()的action参数.这个函数对应的参数是软中断本身(h->action(h)),采用这样的形式,可以在改变softirq_action结构的时候,不会重写软中断处理函数
在进入了软中断的时候,使用了in_interrupt()来防止软中断嵌套,和抢占硬中断环境。然后软中断以开中断的形式运行,软中断的处理随时都会被硬件中断抢占,由于在软中断运行之前调用了local_bh_disable(),所以in_interrupt()为真,不会执行软中断.
来看下in_interrupt() local_bh_disable() __local_bh_enable()的具体代码:
#define in_interrupt() (irq_count())
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK))
#define local_bh_disable() \
do { preempt_count() += SOFTIRQ_OFFSET; barrier(); } while (0)
#define __local_bh_enable() \
do { barrier(); preempt_count() -= SOFTIRQ_OFFSET; } while (0)
相当于local_bh_disable设置了preempt_count的SOFTIRQ_OFFSET。In_interrupt判断就会返回一个真值
相应的__local_bh_enable()清除了SOFTIRQ_OFFSET标志
还有几个常用的判断,列举如下:
in_softirq():判断是否在一个软中断环境
hardirq_count():判断是否在一个硬中断环境
local_bh_enable()与__local_bh_enable()作用是不相同的:前者不仅会清除SOFTIRQ_OFFSET,还会调用do_softirq(),进行软中断的处理
上述几个判断的代码都很简单,可自行对照分析
四:几种常用的软中断分析
经过上面的分析,看到了linux的软中断处理模式,我们具体分析一下2.6kernel中常用的几种软中断
1:tasklet分析
Tasklet也是俗称的小任务机制,它使用比较方法,另外,还分为了高优先级tasklet与一般tasklet。还记得我们刚开始分析过的softirq_init()这个函数吗
void __init softirq_init(void)
{
//普通优先级
open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
//高优先级
open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
}
它们的软中断处理函数其实是tasklet_action与tasklet_hi_action.
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
//禁止本地中断
local_irq_disable();
//per_cpu变量
list = __get_cpu_var(tasklet_vec).list;
//链表置空
__get_cpu_var(tasklet_vec).list = NULL;
//恢复本地中断
local_irq_enable();
//接下来要遍历链表了
while (list) {
struct tasklet_struct *t = list;
list = list->next;
//为了避免竞争,下列操作都是在加锁情况下进行的
if (tasklet_trylock(t)) {
//t->count为零才会调用task_struct里的函数
if (!atomic_read(&t->count)) {
//t->count 为1。但又没有置调度标志。系统BUG
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
//调用tasklet函数
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
//注意 :所有运行过的tasklet全被continue过去了,只有没有运行的tasklet才会重新加入到链表里面
//禁本地中断
local_irq_disable();
//把t放入队列头,准备下一次接收调度
t->next = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = t;
//置软中断调用标志。下次运行到do_softirq的时候,可以继续被调用
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
//启用本地中断
local_irq_enable();
}
}
高优先级tasklet的处理其实与上面分析的函数是一样的,只是per_cpu变量不同而已。
另外,有几个问题值得考虑:
1) cpu怎么计算软中断优先级的
在do_softirq()à__do_softirq()有:
{
pending = local_softirq_pending();
......
do {
if (pending & 1) {
h->action(h);
rcu_bh_qsctr_inc(cpu);
}
h++;
pending >>= 1;
} while (pending);
......
}
从上面看到,从softirq_vec[]中取项是由pending右移位计算的。
另外,在激活软中断的操作中:
#define __raise_softirq_irqoff(nr) do { local_softirq_pending() |= 1UL << (nr); } while (0)
可以看到 nr越小的就会越早被do_softirq遍历到
2) 在什么条件下才会运行tasklet 链表上的任务
我们在上面的代码里看到只有在t->count为零,且设置了TASKLET_STATE_SCHED标志才会被遍历到链表上对应的函数
那在我们自己的代码里该如何使用tasklet呢?举个例子:
#include
#include
#include
#include
static void tasklet_test_handle(unsigned long arg)
{
printk("in tasklet test\n");
}
//声明一个tasklet
DECLARE_TASKLET(tasklet_test,tasklet_test_handle,0);
MODULE_LICENSE("GPL xgr178@163.com");
int kernel_test_init()
{
printk("test_init\n");
//调度这个tasklet
tasklet_schedule(&tasklet_test);
}
int kernel_test_exit()
{
printk("test_exit\n");
//禁用这个tasklet
tasklet_kill(&tasklet_test);
return 0;
}
module_init(kernel_test_init);
module_exit(kernel_test_exit);
示例模块里涉及到tasklet通用的三个API.分别是DECLARE_TASKLET(), tasklet_schedule(),tasklet_kill()
跟踪一下内核代码:
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
实际上,DECLARE_TASKLET就是定义了一个tasklet_struct的变量.相应的tasklet调用函数为func().函数参数为data
static inline void tasklet_schedule(struct tasklet_struct *t)
{
//如果tasklet没有置调度标置,也就是说该tasklet没有被调度
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
void fastcall __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
//把tasklet加到__get_cpu_var(tasklet_vec).list链表头
local_irq_save(flags);
t->next = __get_cpu_var(tasklet_vec).list;
__get_cpu_var(tasklet_vec).list = t;
//激活相应的软中断
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
这个函数比较简单,不详细分析了
void tasklet_kill(struct tasklet_struct *t)
{
//不允许在中断环境中进行此操作
if (in_interrupt())
printk("Attempt to kill tasklet from interrupt\n");
//一直等待tasklet被调度完
while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) {
do
yield();
while (test_bit(TASKLET_STATE_SCHED, &t->state));
}
//一直等待tasklet被运行完
tasklet_unlock_wait(t);
//清除调度标志
clear_bit(TASKLET_STATE_SCHED, &t->state);
}
该函数会一直等待该tasklet调度并运行完,可能会睡眠,所以不能在中断环境中使用它
2:网络协议栈里专用软中断
在前面分析网络协议协的时候分析过,网卡有两种模式,一种是中断,即数据到来时给CPU上传中断,等到CPU处理中断.第二种是轮询,即在接收到第一个数据包之后,关闭中断,CPU每隔一定时间就去网卡DMA缓冲区取数据.其实,所谓的轮询就是软中断.接下来就来研究一下网络协议栈的软中断
static int __init net_dev_init(void)
{
……
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
……
}
在这里注册了两个软中断,一个用于接收一个用于发送,函数大体差不多,我们以接收为例.从前面的分析可以知道,软中断的处理函数时就是它调用open_softirq的action参数.在这里即是net_rx_action.代码如下:
static void net_rx_action(struct softirq_action *h)
{
//per_cpu链表.所有网卡的轮询处理函数都通过napi_struct结构存放在这链表里面
struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
unsigned long start_time = jiffies;
int budget = netdev_budget;
void *have;
//关中断
local_irq_disable();
//遍历链表
while (!list_empty(list)) {
struct napi_struct *n;
int work, weight;
if (unlikely(budget <= 0 || jiffies != start_time))
goto softnet_break;
local_irq_enable();
// 取链表里的相应数据
n = list_entry(list->next, struct napi_struct, poll_list);
have = netpoll_poll_lock(n);
weight = n->weight;
work = 0;
//如果允许调度,则运行接口的poll函数
if (test_bit(NAPI_STATE_SCHED, &n->state))
work = n->poll(n, weight);
WARN_ON_ONCE(work > weight);
budget -= work;
//关中断
local_irq_disable();
if (unlikely(work == weight)) {
//如果被禁用了,就从链表中删除
if (unlikely(napi_disable_pending(n)))
__napi_complete(n);
Else
//否则加入链表尾,等待下一次调度
list_move_tail(&n->poll_list, list);
}
netpoll_poll_unlock(have);
}
out:
//启用中断
local_irq_enable();
//选择编译部份,忽略
#ifdef CONFIG_NET_DMA
/*
* There may not be any more sk_buffs coming right now, so push
* any pending DMA copies to hardware
*/
if (!cpus_empty(net_dma.channel_mask)) {
int chan_idx;
for_each_cpu_mask(chan_idx, net_dma.channel_mask) {
struct dma_chan *chan = net_dma.channels[chan_idx];
if (chan)
dma_async_memcpy_issue_pending(chan);
}
}
#endif
return;
softnet_break:
__get_cpu_var(netdev_rx_stat).time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
一般在接口驱动中,会调用__napi_schedule.将其添加进遍历链表.代码如下示:
void fastcall __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
//加至链表末尾
list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);
//激活软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
local_irq_restore(flags);
}
关于网卡选择哪一种模式最为合适,我们在前面已经讲述过,这里不再赘述.
五:小结
本节主要分析了中断程序的处理过程与软中断的实现.虽然软中断实现有很多种类,究其模型都是一样的,就是把中断的一些费时操作在响应完中断之后再进行.另外,中断与软中断处理中有很多临界区,需要关闭CPU中断和打开CPU中断.其中的奥妙还需要慢慢的体会















 工商网监
工商网监
评论