 电子发烧友App
电子发烧友App


不幸的是,对于一些更加专业的工作,Vanilla Linux(译注:Linux 的内核版本,代号“香草”) 内核的网络速度是不够的。举个例子,在 CloudFlare,我们持续地处理洪水般的数据包。 Vanilla Linux 处理速度仅能达到约 1M pps (译注:单位 packet per seconds),这在我们的工作环境下是不够的,特别是网卡有能力处理大量的数据包。现代 10Gbps 网卡的处理能力通常至少达到 10M pps 。
内核不给力
我们做一个小实验来说明修改 Linux 确实是有必要的。我们看看理想状态下内核能处理多少数据包。把数据包传递到用户空间的代价是高昂的,让我们尝试一下在网络驱动程序收到数据包后就立刻丢弃它们。据我所知,Linux 上不修改内核丢弃数据包最快的方法是在 PREROUTING iptables 上设置一些丢弃规则。
Shell
1
2
3
4
5
6
7
$ sudo iptables -t raw -I PREROUTING -p udp --dport 4321 --dst 192.168.254.1 -j DROP
$ sudo ethtool -X eth2 weight 1
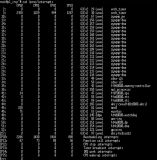
$ watch 'ethtool -S eth2|grep rx'
rx_packets: 12.2m/s
rx-0.rx_packets: 1.4m/s
rx-1.rx_packets: 0/s
...
如上所示, Ethtool(译者注:Ethtool 是 Linux 下用于查询及设置网卡参数的命令)的统计显示,网卡能达到每秒接收 12M 数据包的速度。通过 ethtool -X 来操作网卡上的间接表,可以将所有的数据包引向 0 号 RX 队列。正如我们看到的,在一颗 CPU 上,内核处理队列的速度可以达到 1.4M pps。
在单核上能达到 1.4M pps 是一个相当不错的结果,但不幸的是协议栈却不能扩展。当数据包被分配到多核上,这个成绩会急剧下降。让我们看看把数据包分到 4 个 RX 队列的结果。
Shell
1
2
3
4
5
6
7
$ sudo ethtool -X eth2 weight 1 1 1 1
$ watch 'ethtool -S eth2|grep rx'
rx_packets: 12.1m/s
rx-0.rx_packets: 477.8k/s
rx-1.rx_packets: 447.5k/s
rx-2.rx_packets: 482.6k/s
rx-3.rx_packets: 455.9k/s
此时每个核的处理速度是 480k pps。这是个糟糕的消息。即使乐观地假设增加多个核心不会进一步地造成性能的下降,处理数据包的核心也要多达 20 个才能达到线速度。所以内核是不起作用的。
内核旁路前来救驾
CC BY 2.0 image by Matt Brown
关于 Linux 内核网络性能的局限早已不是什么新鲜事了。在过去的几年中,人们多次尝试解决这个问题。最常用的技术包括创建特别的 API,来帮助高速环境下的硬件去接收数据包。不幸的是,这些技术总是在变动,至今没有出现一个被广泛采用的技术。
这里列出一些广为人知的内核旁路技术。
PACKET_MMAP
Packet mmap 是 Linux 上的API,用来实现数据包快速嗅探。然而它不是严格意义上的内核旁路技术,它是技术列表中的一个特例 —— 可以在 Vanilla 内核上使用。
PF_RING
PF_RING 是另一个已知的技术,用来提升捕获数据包的速度。不像 packet_mmap,PF_RING 不在内核主线中,需要一些特殊模块。通过 ZC 驱动和把模式设置成 transparent_mode = 2(译者注:是 PF_RING 的一种模式),只把数据包传递给 PF_RING 客户端,而不会经过内核网络协议栈。由于内核比较缓慢,这样可以确保高速运转。
Snabbswitch
Snabbswitch 是一个 Lua 网络框架,主要用来写 L2 应用。它可以完全接管一个网卡,并且在用户空间实现硬件驱动。它在一个 PCI 设备上实现了用户空间 IO(UIO),把设备寄存器映射到 sysfs 上(译者注:sysfs 是 Linux 内核中设计较新的一种虚拟的基于内存的文件系统) 。这样就可以非常快地操作,但是这意味着数据包完全跳过了内核网络协议栈。
DPDK
DPDK 是一个用 C 语言实现的网络框架,专门为 Intel 芯片创建。它本质上和 snabbswitch 类似,因为它也是一个基于UIO 的完整框架。
Netmap
Netmap 也是一个丰富的网络框架,但是和 UIO 技术不同,它是由几个内核模块来实现的。为了和网络硬件集成在一起,用户需要给内核网络驱动打补丁。增加复杂性的最大好处是有一个详细文档说明的、设备厂商无关的和清晰的 API。
由于内核旁路技术的目的是不再让内核处理数据包,所以我们排除了 packet_mmap。因为它不能接收数据包 —— 它只是一个嗅探数据包的快速接口。同样,没有 ZC 模块的 PF_RING 也没有什么吸引力,因为它的主要目标是加速 libpcap(译者注:libpcap是unix/linux平台下的网络数据包捕获函数包,大多数网络监控软件都以它为基础)。
我们已经排除了两种技术,但很不幸的是,在余下的解决方案中,也没有我们能够使用的!
让我告诉你原因。为了用 剩下的技术 实现内核旁路技术:Snabbswitch、DPDK 和 netmap 会接管整个网卡,不允许网卡的任何流量经过内核。我们在 CloudFlare,根本不可能让一个分担负载的应用程序独占整个网卡。
话说回来,很多人使用上面的技术。在其他环境中占用一个网卡,来实现旁路也许是可以接受的。
Solarflare 上的 EF_VI
虽然上面列出的技术需要占用整个网卡,但还有其它的选择。

Solarflare 网卡支持 OpenOnload,一个神奇的网卡加速器。它通过如下方式来实现内核旁路,在用户空间实现网络协议栈,并使用 LD_PRELOAD 覆盖目标程序的网络系统调用。在底层访问网卡时依靠 “EF_VI” 库。这个库可以直接使用并且有很好的说明文档。
EF_VI 作为一个专用库,仅能用在 Solarflare 网卡上,你可能想知道它实际是如何工作的。 EF_VI 是以一种非常聪明的方式重新使用网卡的通用功能。
在底层,每个 EF_VI 程序可以访问一条特定的 RX 队列,这条 RX 队列对内核不可见的。默认情况下,这个队列不接收数据,直到你创建了一个 EF_VI “过滤器”。这个过滤器只是一个隐藏的流控制规则。你用 ethtool -n 也看不到,但实际上这个规则已经存在网卡中了。对于 EF_VI 来说,除了分配 RX 队列并且管理流控制规则,剩下的任务就是提供一个API 让用户空间可以访问这个队列。
分叉驱动
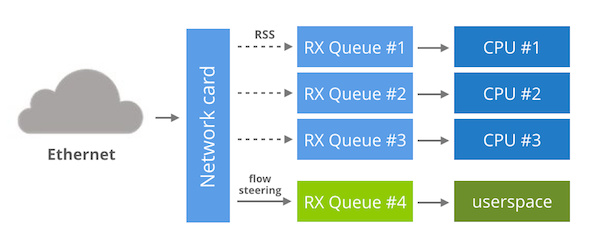
虽然 EF_VI 是 Solarflare 所特有的,其他网卡还是可以复制这个技术。首先我们需要一个支持多队列的网卡,同时它还支持流控制和操作间接表。
有了这些功能,我们可以:
正常启动网卡,让内核来管理一切。
修改间接表以确保没有数据包流向任一 RX 队列。比如说我们选择 16 号 RX 队列。
通过流控制规则将一个特定的网络流引到 16号 RX 队列。
完成这些,剩下的步骤就是提供一个用户空间的 API ,从 16 号 RX 队列上接收数据包,并且不会影响其他任何队列。
这个想法在 DPDK 社区被称为“分叉驱动”。它们打算在 2014 年创建分叉驱动,不幸的是 这个补丁 还没进入内核的主线。
虚拟化方法
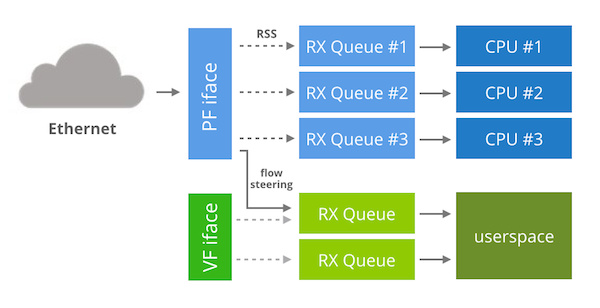
针对 intel 82599 还有另外一种选择。我们可以利用网卡上的虚拟化功能来实现内核旁路,而不需要通过分叉驱动程序。
首先我简单说下背景。有结果证明,在虚拟化世界中将数据包从主机传递到客户机,虚拟机通常是瓶颈。因此,这些年对虚拟化性能的需求与日俱增,通过软件模拟网络硬件的仿真技术成为了影响性能的主要障碍。
网卡厂商增加一些特性来加速虚拟客户端。其中一项虚拟化技术,要求网卡虚拟成多个 PCI 设备。虚拟客户端可以操作这些虚拟接口,无需与主机操作系统进行任何合作。我演示一下它是如何工作的。举个例子,这是我本机上的 82599 网卡。这个“真实的”设备被称为 PF(物理功能)接口:
Shell
1
2
$ lspci
04:00.1 Ethernet controller: Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connection (rev 01)
我们要求这个设备创建一个 VF(虚拟功能)设备:
Shell
1
2
3
4
$ echo 1 > /sys/class/net/eth3/device/sriov_numvfs
$ lspci
04:00.1 Ethernet controller: Intel Corporation 82599EB 10-Gigabit SFI/SFP+ Network Connection (rev 01)
04:10.1 Ethernet controller: Intel Corporation 82599 Ethernet Controller Virtual Function (rev 01)
比如说一个 KVM 客户端很容易使用这个假的 PCI 设备。同时,我们还是能够使用主机环境。要做到这些仅需要加载 “ixgbevf” 内核模块,之后会出现另一个 “ethX” 接口。
你或许想知道内核旁路技术干了什么。内核没有利用“ixgbevf”设备正常联网,我们可以把它专门用在内核旁路上。这样看起来可以在 “ixgbevf” 设备运行 DPDK。
概括来说:这个想法可以让 PF 设备正常处理内核工作,而 VF 接口专门用在内核旁路技术上。由于 VF 是专用的,所以我们可以运行“接管整个网卡”的技术。
这听起来似乎不错,实际上却没那么简单。首先,只有 DPDK 支持“ixgbevf”设备,netmap,snabbswtich 和 PF_RING 是不支持的。默认情况下, VF 接口不能接收任何数据包。若通过 PF 发送数据给 VF ,你需要给 ixgbe 打上这个补丁。有了它,你可以对 VF 进行寻址,即在ethtool中对“活动”“队列号的高位进行编码。
Shell
1
$ ethtool -N eth3 flow-type tcp4 dst-ip 192.168.254.30 dst-port 80 action 4294967296
最后一个障碍出现了,在 82599 芯片上启用 VF 功能,RSS 组的最大规模变小了(译者注:Really Simple Syndication,简易信息聚合)。没有虚拟化时,82599 可以在 16 个 CPU 核上进行 RSS 。但随着 VF 的启用,这个数量却变成了 4。如果 PF 上的流量比较低,只使用 4 个核来发布可能还好。不幸的是,我们在 Cloudflare 需要处理大规模的 RSS 组。
结束语
完成内核旁路技术没有那么简单。虽然存在很多开源的技术,但它们看起来都需要一块专用的的网卡。这里我们展示了 3 个可以选择的框架:
类似 EF_VI, 隐藏 RX 队列
DPDK 分叉驱动
VF 技术
不幸的是,在我们的环境下,这么多技术中能起作用的似乎只有 EF_VI。我们祈祷开源的内核旁路 API 赶紧出现,唯一的要求是不需要一块专用的网卡。














 工商网监
工商网监
评论