 电子发烧友App
电子发烧友App


本文首先提出平台相关代码造成的两个问题,然后针对这两个问题循序渐进依次提出解决方案,在分析了前两个方案弱点的基础上,最后着重介绍一种基于多种设计模式的 Linux 平台相关代码的解决方案,并给出此方案的 C++ 实现。
Linux 平台相关代码带来的问题
目前市场上存在着许多不同的 Linux 平台(例如:RedHat, Ubuntu, Suse 等),各大厂商和社区都在针对自己支持的平台进行优化,为使用者带来诸多方便的同时也对软件研发人员在进行编码时带来不少问题:
由于程序中不可避免的存在平台相关代码(系统调用等),软件研发人员为了保证自己的产品在各个 Linux 平台上运行顺畅,一般都需要在源代码中大量使用预编译参数,这样会大大降低程序的可读性和可维护性。
接口平台无关性的原则是研发人员必须遵循的准则。但是在处理平台相关代码时如果处理不当,此原则很有可能被破坏,导致不良的编码风格,影响代码的扩展和维护。
本文将针对这两个问题循序渐进依次提出解决方案。
通过设置预编译选项来处理平台相关代码
通过为每个平台设置相关的预编译宏能够解决 Linux 平台相关代码的问题,实际情况下,很多软件开发人员也乐于单独使用这种方法来解决问题。
假设现有一动态库 Results.so,SomeFunction() 是该库的一个导出函数,该库同时为 Rhel,Suse,Ubuntu 等三个平台的 Linux 上层程序服务。(后文例子均基于此例并予以扩展。)
清单 1. 设置预编译选项示例代码如下:
// Procedure.cpp void SomeFunction() { //Common code for all linux ...... ...... #ifdef RHEL SpecialCaseForRHEL(); #endif #ifdef SUSE SpecialCaseForSUSE(); #endif #ifdef UBUNTU SpecialCaseForUBUNTU(); #endif //Common code for all linux ...... ...... #ifdef RHEL SpecialCase2ForRHEL(); #endif #ifdef SUSE SpecialCase2ForSUSE(); #endif #ifdef UBUNTU SpecialCase2ForUBUNTU(); #endif //Common code for all linux ...... ...... } IT网,http://www.it.net.cn
开发人员可以通过设置 makefile 宏参数或者直接设置 gcc 参数来控制实际编译内容。 IT网,http://www.it.net.cn
例如:
gcc -D RHEL Procedure.cpp -o Result.so -lstdc++ // Use RHEL marco
SpecialCaseForRHEL(),SpecialCaseForSUSE(),SpecialCaseForUBUNTU() 分别在该库 (Results.so) 的其他文件中予以实现。
图 1. 清单 1 代码的结构图

带来的问题
SomeFunction() 函数代码冗余,格式混乱。本例仅涉及三个预编译选项,但实际情况中由于 Linux 版本众多并且可能涉及操作系统位数的问题,增加对新系统的支持会导致预编译选项不断增多,造成 SomeFunction() 函数结构十分混乱。
新增其他平台相关接口(例如:增加 SpecialCase3ForRHEL(),SpecialCase3ForSUSE(),SpecialCase3ForUBUNTU),会成倍增加代码中预编译宏的数量。
破坏了接口平台无关性的原则。SpecialCaseForRHEL(),SpecialCaseForSUSE(),SpecialCaseForUBUNTU() 只是同一功能各个平台的不同实现,属于封装内容,不应该分开暴露给调用者。
可见,简单利用预编译宏来解决平台相关代码产生的问题不是一个好的方法,并没有解决本文开始提出的两个问题。后文将通过三个方案依次解决这些问题。
解决方案 1:根据接口平台无关性原则进行优化
实质上,SpecialCaseForRHEL(),SpecialCaseForSUSE(),SpecialCaseForUBUNTU() 只是同一功能在不同平台上的实现,SpecialCase2ForRHEL(),SpecialCase2ForSUSE(),SpecialCase2ForUBUNTU() 亦如此。对于调用者,应该遵循接口平台无关性的原则,使用统一的接口进行调用,这样才能简化代码,使代码易于维护。
清单 2. 解决方案 1 示例代码如下:
// Procedure.cpp void SomeFunction() { //Common code for all linux ...... ...... SpecialCase(); //Common code for all linux ...... ...... SpecialCase2(); //Common code for all linux ...... ...... } void SpecialCase() { //Common code for all linux ...... ...... #ifdef RHEL SpecialCaseForRHEL(); #endif #ifdef SUSE SpecialCaseForSUSE(); #endif #ifdef UBUNTU SpecialCaseForUBUNTU(); #endif //Common code for all linux ...... ...... } void Special2Case() { //Common code for all linux ...... ...... #ifdef RHEL SpecialCase2ForRHEL(); #endif #ifdef SUSE SpecialCase2ForSUSE(); #endif #ifdef UBUNTU SpecialCase2ForUBUNTU(); #endif //Common code for all linux ...... ...... }
此方案的优点:
遵循了接口平台无关性原则,同样的功能只提供一个接口,每个平台的实现属于实现细节,封装在接口内部。此方案提供了一定的封装性,简化了调用者的操作。
此方案的缺点:
预编译宏泛滥的问题仍然没有解决,每次新增功能函数,就会成倍增加预编译宏的数量。同样每次增加对已有功能新平台的支持,也会不断增加预编译宏的数量。
可见,此方案部分解决了本文开始提出的两个问题中的一个,但仍有问题需要继续解决。
解决方案 2: 通过分层对进行优化
换一个角度来思考,可以在二进制层面对平台相关代码进行优化。通过对库的结构进行分层来优化,为每个 Linux 平台提供单独的实现库,并且把调用端独立提取出来。如下图所示:
图 2: 方案 2 的结构图
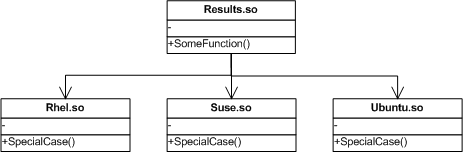
此方案单独将调用端抽象出来,将每个平台实现端的相关代码提取出来做成一个单独的库(Rhel.so,Suse.so,Ubuntu.so)。SpecialCase() 为同一功能在不同平台的实现,采用相同接口名。底层库需要与 Results.so 库同时发布,也就是说,Redhat 版本发布时需同时打包 Results.so 和 Rhel.so,其他版本亦然。 Linux学习,http:// linux.it.net.cn
此方案的优点:
解决了预编译宏泛滥的问题,通过二进制分层可以将代码里的所有预编译选项去掉。遵循了接口平台无关性的原则。
可见,此方案很好地解决了本文开始提出的两个问题。 Linux学习,http:// linux.it.net.cn
此方案的缺点:
每次发布 Results.so 的时候,底层库需要伴随一起发布,导致可执行包文件数量成倍增加。而且很多小程序,小工具的发布往往采取单独的二进制文件,不允许有底层库的存在。
解决方案 3: 结合代理模式,桥接模式和单例模式进行优化
现在针对原始问题继续进行优化,摈弃方案 2 采用的分层手法,在单一库的范围内利用 C++ 多态特性和设计模式进行优化。
目标效果:
源代码中尽可能减少预编译选项出现的频率,避免因功能扩展和平台支持的增加导致预编译宏数量爆炸。
完全遵循接口平台无关性的原则。
清单 3. 解决方案 3 调用端示例代码如下:
// Procedure.cpp void SomeFunction() { //Common code for all linux ...... ...... XXHost::instance()->SpecialCase1(); //Common code for all linux ...... ...... XXHost::instance()->SpecialCase2(); //Common code for all linux ...... ...... } Linux学习,http:// linux.it.net.cn
图 3:方案 3 的具体实现类图
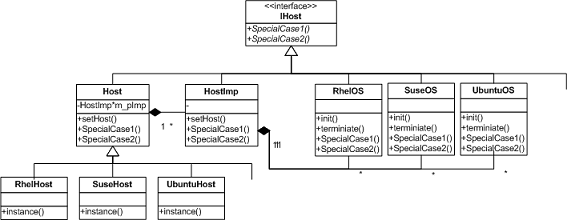
此方案结合改进的代理模式(Proxy),桥接模式(Bridge)和单件模式(Singleton),并利用 C++ 封装、继承和多态特性予以实现。 IT网,http://www.it.net.cn
IHost 是顶层抽象接口类,声明了实现端需要实现的功能函数以及调用端需要调用的接口函数。 Linux学习,http:// linux.it.net.cn
图 3 右半部分派生自 IHost 的各个类为实现端,在实现端, Linux学习,http:// linux.it.net.cn
为每个 Linux 系统单独实现了一个类,相互之间无关联性。该类实现了该操作系统平台相关的功能(SpecialCase1() 和 SpecialCase2()),即实现了平台相关代码。每个实现类采取单件模式。
Init() 和 terminate() 用来初始化和清理操作。Init() 函数首先创建自己(单件模式),其次创建左侧代理类(单件模式,见下段描述),最后将自己的内存地址通过 SetHost() 函数交给左侧代理方。
图 3 左半部分派生自 Host 的各个类为调用端,在调用端, IT网,http://www.it.net.cn
Host 类做了一层封装,RhelHost 等派生类为实际的代理者(调用者),每个 Host 的派生类分别代表一种需求(调用方),是右侧实现类的一个代理,例如 RhelHost 是 RhelOS 的代理,SuseHost 是 SuseOS 的代理,UbuntuHost 是 UbuntuOS 的代理。每个 Host 的派生类采取单件模式。 IT网,http://www.it.net.cn
Host 类和 HostImp 类之间采用桥接的设计模式,利用 C++ 多态特性,最后通过 HostImp 类调用实现端类的实现。调用端的调用过程如下:
通过 RhelHost 的指针调用 SpecialCase(),由于 RhelHost::SpecialCase() 没有覆盖基类虚函数的实现,实际调用的是 Host::SpecialCase()。
Host 的所有调用被桥接到 HostImp 对应的函数。
由 HostImp 类调用确定的实现端的某一个对象的对应实现函数(HostImp 类的 SetHost() 函数记录了右侧类的对象内存地址)。
清单 4. 解决方案 3 框架主要源代码如下:
// Host.h class IHost { public: virtual void SpecialCase1() = 0; virtual void SpecialCase2() = 0; }; class Host : public IHost { public: virtual ~Host() {}; void setHost(IHost* pHost) { m_pImp->setHost(pHost); } virtual void SpecialCase1() { m_pImp->SpecialCase1(); }; virtual void SpecialCase2() { m_pImp->SpecialCase2(); }; protected: Host(HostImp * pImp); private: HostImp* m_pImp; friend class HostImp; }; class RhelHost : public Host { public: static RhelHost* instance(); private: RhelHost(HostImp* pImp); }; RhelHost * RhelHost::instance() { static RhelHost * pThis = new RhelHost (new HostImp()); return pThis; } RhelHost:: RhelHost (HostImp* pImp) : Host(pImp) { } class RhelOS : public IHost { public: static void init() { static RhelOS me; RhelHost::instance()->setHost(&me); } static void term() { RhelHost::instance()->setHost(NULL); } private: virtual void SpecialCase1() { /* Real Operation */ }; virtual void SpecialCase2() { /* Real Operation */ }; }; // HostImp.h class HostImp : public IHost { private: HostImp(const HostImp&); public: HostImp(); virtual ~HostImp() {}; void setHost(IHost* pHost) { m_pHost = pHost; }; virtual void SpecialCase1() { if(m_pHost != NULL) m_pHost->SpecialCase1() } virtual void SpecialCase2() { if(m_pHost != NULL) m_pHost->SpecialCase2() } private: IHost* m_pHost; };
此方案的优点:
遵循接口平台无关性原则。此方案将各平台通用接口提升到最高的抽象层,易于理解和修改。
最大限度地降低预编译选项在源代码中的使用,实际上,本例中只需要在一处使用预编译宏,示例代码如下:
void Init() { #ifdef RHEL RhelOS::init(); #endif #ifdef SUSE SuseOS::init(); #endif #ifdef UBUNTU UbuntuOS::init(); #endif }
源代码其他地方不需要添加预编译宏。
实现端和调用端都通过类的形式进行封装,而且实现端类和调用端类都可以自己单独扩展,完成一些各自需要完成的任务,所要保持一致的只是接口层函数。扩展性和封装性很好。
由此可见,此方案很好地解决了本文开始提出的两个问题,而且代码结构清晰,可维护型好。
接下来对上述源代码继续进行优化。上例 SuseHost/UbuntuHost/SUSEOS/UBUNTUOS 等类的实现被略去,实际上这些类的实现与 RhelHost 和 RHELOS 相似,可以利用宏来进一步优化框架代码结构。 Linux学习,http:// linux.it.net.cn
清单 5. 解决方案 3 框架主要源代码优化:
#define HOST_DECLARE(name) \ class ##nameHost : public Host \ { \ public: \ static ##nameHost* instance(); \ private: \ ##nameHost(HostImp* pImp); \ }; #define HOST_DEFINE(name) \ ##nameHost* ##nameHost::instance() \ { \ static ##nameHost* pThis = new ##nameHost(new HostImp()); \ return pThis; \ } \ ##nameHost::##nameHost(HostImp* pImp) \ : Host(pImp) \ { \ } #define HOST_IMPLEMENTATION(name) \ class ##name##OS : public IHost \ { \ public: \ static void init() \ { \ static ##name##OS me; \ ##nameHost::instance()->setHost(&me); \ } \ static void term() \ { \ ##nameHost::instance()->setHost(NULL); \ } \ private: \ virtual void SpecialCase1(); \ virtual void SpecialCase2(); \ };
使用三个宏来处理相似代码。至此,优化完成。从源代码角度来分析,作为实现端的开发人员,只需要三步就可以完成操作:
调用 init() 函数;
使用 #define HOST_IMPLEMENTATION(name); 例如:#define HOST_IMPLEMENTATION(DEBIAN)
实现 DEBIAN::SpecialCase1() 和 DEBIAN::SpecialCase2()。 作为调用端的开发人员,也只需要三步就可以完成操作:
使用 #define HOST_DECLARE(name) 进行声明; 例如 : #define HOST_DECLARE(DEBIAN)
使用 #define HOST_DEFINE(name) 进行定义; 例如: #define HOST_DEFINE (DEBIAN)
调用接口。 例如: DEBIANHost::instance()->SpecialCase1();DEBIANHost::instance()->SpecialCase2();
可见,优化后方案的代码清晰,不失为一个良好的平台相关代码的解决方案。
由于调用端和实现端往往需要传递参数,可以通过 SpecialCase1() 函数的参数来传递参数,同样的这个参数类可以通过桥接的方式予以实现,本文不再详述,读者可以自己尝试。
对方案 3 的扩展
扩展 1:对单一操作系统多对多的扩展
对于方案 3 的实现,也许有读者会问,调用端只需要 Host 类不需要其派生类即可完成方案 3 中的功能,的确如此,因为方案 3 中的代理类一直是一对一的关系,即 RhelHost 代理 RhelOS,Redhat 下只存在这一对一的关系。但是实际情况下,单一系统下很可能存在多对多的关系。
例如,在单一操作系统中,可能需要同时实现多种风格的窗口。实际上,变成了多对多的代理关系。
图 4:单一操作系统不同 c 风格窗口的实现类图
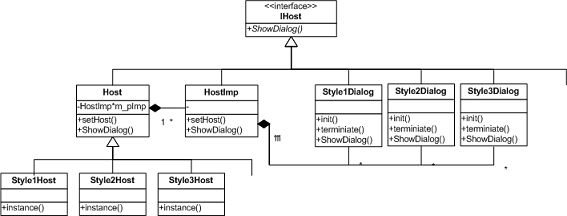
Style1Host 代理 Style1Dialog,Style2Host 代理 Style2Dialog,Style3Host 代理 Style3Dialog,三个窗口同时并存,也就是说左侧三个实现类的实例和右侧三个代理类的实例同时存在。可见,方案 3 的设计模式扩展性良好,实现端和调用端都可以在遵循接口不变性的情况下单独扩展自己的功能。
扩展 2:对多操作系统的扩展
方案 3 不仅可以针对 Linux 平台相关代码进行处理,还可以扩展到其他诸多场合。例如,现在的程序库往往需要针对多个操作系统,包括 Windows, Linux, Mac。每个操作系统往往使用不同的 GUI 库,这样在实现窗口操作的时候必然涉及到平台相关代码。同样可以用方案 3 予以实现。
图 5:多操作系统的实现类图
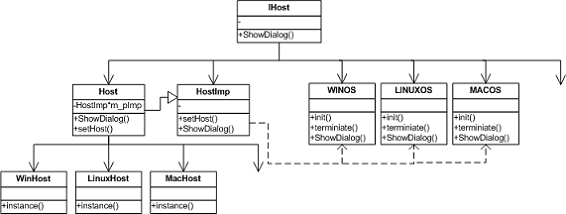
Linux学习,http:// linux.it.net.cn
总结
本文开始提出平台相关代码造成的两个问题,接着循序渐进提出解决方案。在分析了常用的设置预编译选项方法的利弊的基础上,提出了一种新的利用 C++ 多态特性,结合使用代理模式,桥接模式和单件模式处理平台相关代码的方案,并对这一方案予以扩展,给读者提供了一种新的高效的处理平台相关代码的方法。 Li










 工商网监
工商网监
评论