 电子发烧友App
电子发烧友App


一、前言
本文主要描述的是进程优先级这个概念。从用户空间来看,进程优先级就是nice value和scheduling priority,对应到内核,有静态优先级、realtime优先级、归一化优先级和动态优先级等概念,我们希望能在第二章将这些相关的概念描述清楚。为了加深理解,在第三章我们给出了几个典型数据流过程的分析。
二、overview
1、蓝图
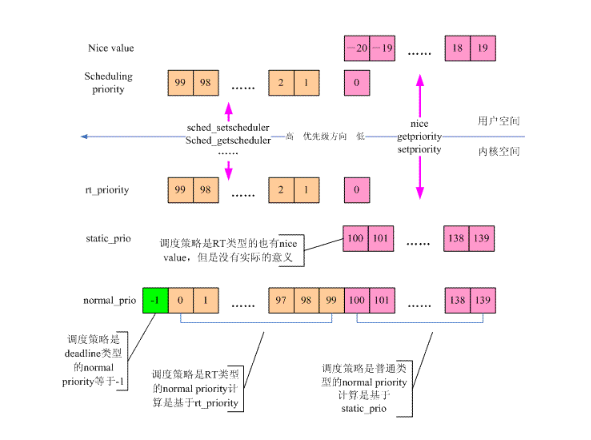
2、用户空间的视角
在用户空间,进程优先级有两种含义:nice value和scheduling priority。对于普通进程而言,进程优先级就是nice value,从-20(优先级最高)~19(优先级最低),通过修改nice value可以改变普通进程获取cpu资源的比例。随着实时需求的提出,进程又被赋予了另外一种属性scheduling priority,而这些进程被称为实时进程。实时进程的优先级的范围可以通过sched_get_priority_min和sched_get_priority_max,对于linux而言,实时进程的scheduling priority的范围是1(优先级最低)~99(优先级最高)。当然,普通进程也有scheduling priority,被设定为0。
3、内核中的实现
内核中,task struct中有若干和进程优先级有个的成员,如下:
struct task_struct {
......
int prio, static_prio, normal_prio;
unsigned int rt_priority;
......
unsigned int policy;
......
}
policy成员记录了该线程的调度策略,而其他的成员表示了各种类型的优先级,下面的小节我们会一一描述。
4、静态优先级
task struct中的static_prio成员。我们称之静态优先级,其特点如下:
(1)值越小,进程优先级越高
(2)0 – 99用于real-time processes(没有实际的意义),100 – 139用于普通进程
(3)缺省值是 120
(4)用户空间可以通过nice()或者setpriority对该值进行修改。通过getpriority可以获取该值。
(5)新创建的进程会继承父进程的static priority。
静态优先级是所有相关优先级的计算的起点,要么继承自父进程,要么用户空间自行设定。一旦修改了静态优先级,那么normal priority和动态优先级都需要重新计算。
5、实时优先级
task struct中的rt_priority成员表示该线程的实时优先级,也就是从用户空间的视角来看的scheduling priority。0是普通进程,1~99是实时进程,99的优先级最高。
6、归一化优先级
task struct中的normal_prio成员。我们称之归一化优先级(normalized priority),它是根据静态优先级、scheduling priority和调度策略来计算得到,代码如下:
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p))
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p))
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p);
return prio;
}
这里我们先聊聊归一化(Normalization)这个看起来稍微有点晦涩的术语。如果你做过音视频定点算法的优化,应该对这个词不陌生。不同的定点数据有不同的表示,有Q31的,有Q15,这些数据的小数点的位置不同,无法进行比较、加减等操作,因此需要归一化,全部转换成某个特定的数据格式(其实就是确定小数点的位置)。在数学上,1米和1mm在进行操作的时候也需要归一化,全部转换成同一个量纲就OK了。对于这里的优先级,调度器需要综合考虑各种因素,例如调度策略,nice value、scheduling priority等,把这些factor全部考虑进来,归一化成一个数轴上的number,以此来表示其优先级,这就是normalized priority。对于一个线程,其normalized priority的number越小,其优先级越大。
调度策略是deadline的进程比RT进程和normal进程的优先级还要高,因此它的归一化优先级是负数:-1。如果采用实时调度策略,那么该线程的normalized priority和rt_priority相关。task struct中的rt_priority成员是用户空间视角的实时优先级(scheduling priority),MAX_RT_PRIO-1是99,MAX_RT_PRIO-1 - p->rt_priority则翻转了实时进程的scheduling priority,最高优先级是0,最低是98。顺便说一句,normalized priority是99的情况是没有意义的。对于普通进程,normalized priority就是其静态优先级。
7、动态优先级
task struct中的prio成员表示了该线程的动态优先级,也就是调度器在进行调度时候使用的那个优先级。动态优先级在运行时可以被修改,例如在处理优先级翻转问题的时候,系统可能会临时调升一个普通进程的优先级。一般设定动态优先级的代码是这样的:p->prio = effective_prio(p),具体计算动态优先级的代码如下:
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
rt_prio是一个根据当前优先级来确定是否是实时进程的函数,包括两种情况,一种情况是该进程是实时进程,调度策略是SCHED_FIFO或者SCHED_RR。另外一种情况是人为的将该进程提升到RT priority的区域(例如在使用优先级继承的方法解决系统中优先级翻转问题的时候)。在这两种情况下,我们都不改变其动态优先级,即effective_prio返回当前动态优先级p->prio。其他情况,进程的动态优先级跟随归一化的优先级。
三、典型数据流程分析
1、用户空间设定nice value
用户空间设定nice value的操作,在内核中主要是set_user_nice函数实现的,无论是sys_nice或者sys_setpriority,在参数检查和权限检查之后都会调用set_user_nice函数,完成具体的设定。代码如下:
void set_user_nice(struct task_struct *p, long nice)
{
int old_prio, delta, queued;
unsigned long flags;
struct rq *rq;
rq = task_rq_lock(p, &flags);
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {-----------(1)
p->static_prio = NICE_TO_PRIO(nice);
goto out_unlock;
}
queued = task_on_rq_queued(p);-------------------(2)
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE);
p->static_prio = NICE_TO_PRIO(nice);----------------(3)
set_load_weight(p);
old_prio = p->prio;
p->prio = effective_prio(p);
delta = p->prio - old_prio;
if (queued) {
enqueue_task(rq, p, ENQUEUE_RESTORE);------------(2)
if (delta < 0 || (delta > 0 && task_running(rq, p)))------------(4)
resched_curr(rq);
}
out_unlock:
task_rq_unlock(rq, p, &flags);
}
(1)如果是实时进程或者deadline类型的进程,那么nice value其实是没有什么实际意义的,不过我们还是设定其静态优先级,当然,这样的设定其实不会起到什么作用的,也不会实际改变调度器行为,因此直接返回,没有dequeue和enqueue的动作。
(2)在step中已经处理了调度策略是RT类和DEADLINE类的进程,因此,执行到这里,只可能是普通进程了,使用CFS算法。如果该task在run queue上(queued 等于true),那么由于我们修改了nice value,调度器需要重新审视当前runqueue中的task。因此,我们需要将该task从rq中摘下,在重新计算优先级之后,再次插入该runqueue对应的runable task的红黑树中。
(3)最核心的代码就是p->static_prio = NICE_TO_PRIO(nice);这一句了,其他的都是side effect。比如说load weight。当cpu一刻不停的运算的时候,其load是100%,没有机会调度到idle进程休息一下。当系统中没有实时进程或者deadline进程的时候,所有的runnable的进程一起来瓜分cpu资源,以此不同的进程分享一个特定比例的cpu资源,我们称之load weight。不同的nice value对应不同的cpu load weight,因此,当更改nice value的时候,也必须通过set_load_weight来更新该进程的cpu load weight。除了load weight,该线程的动态优先级也需要更新,这是通过p->prio = effective_prio(p);来完成的。
(4)delta 记录了新旧线程的动态优先级的差值,当调试了该线程的优先级(delta < 0),那么有可能产生一个调度点,因此,调用resched_curr,给当前正在运行的task做一个标记,以便在返回用户空间的时候进行调度。此外,如果修改当前running状态的task的动态优先级,那么调降(delta > 0)意味着该进程有可能需要让出cpu,因此也需要resched_curr标记当前running状态的task需要reschedule。
2、进程缺省的调度策略和调度参数
我们先思考这样的一个问题:在用户空间设定调度策略和调度参数之前,一个线程的default scheduling policy是什么呢?这需要追溯到fork的时候(具体代码在sched_fork函数中),这个和task struct中sched_reset_on_fork设定相关。如果没有设定这个flag,那么说明在fork的时候,子进程跟随父进程的调度策略,如果设定了这个flag,则说明子进程的调度策略和调度参数不能继承自父进程,而是需要设定为default。代码片段如下:
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
……
p->prio = current->normal_prio; -------------------(1)
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {----------(2)
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = __normal_prio(p); ------------(3)
set_load_weight(p);
p->sched_reset_on_fork = 0;
}
……
}
(1)sched_fork只是fork过程中的一个片段,在fork一开始,dup_task_struct已经复制了一个和父进程完全一个的进程描述符(task struct),因此,如果没有步骤2中的重置,那么子进程是跟随父进程的调度策略和调度参数(各种优先级),当然,有时候为了解决PI问题而临时调升父进程的动态优先级,在fork的时候不宜传递到子进程中,因此这里重置了动态优先级。
(2)缺省的调度策略是SCHED_NORMAL,静态优先级等于120(也就是说nice value等于0),rt priority等于0(普通进程)。不管父进程如何,即便是deadline的进程,其fork的子进程也需要恢复到缺省参数。
(3)既然调度策略和静态优先级已经修改了,那么也需要更新动态优先级和归一化优先级。此外,load weight也需要更新。一旦子进程中恢复到了缺省的调度策略和优先级,那么sched_reset_on_fork这个flag已经完成了历史使命,可以clear掉了。
OK,至此,我们了解了在fork过程中对调度策略和调度参数的处理,这里还是要追加一个问题:为何不一切继承父进程的调度策略和参数呢?为何要在fork的时候reset to default呢?在linux中,对于每一个进程,我们都会进行资源限制。例如对于那些实时进程,如果它持续消耗cpu资源而没有发起一次可以引起阻塞的系统调用,那么我们猜测这个realtime进程跑飞了,从而锁住了系统。对于这种情况,我们要进行干预,因此引入了RLIMIT_RTTIME这个per-process的资源限制项。但是,如果用户空间的realtime进程通过fork其实也可以绕开RLIMIT_RTTIME这个限制,从而肆意的攫取cpu资源。然而,机智的内核开发人员早已经看穿了这一切,为了防止实时进程“泄露”到其子进程中,sched_reset_on_fork这个flag被提出来。
3、用户空间设定调度策略和调度参数
通过sched_setparam接口函数可以修改rt priority的调度参数,而通过sched_setscheduler功能会更强一些,不但可以设定rt priority,还可以设定调度策略。而sched_setattr是一个集大成之接口,可以设定一个线程的调度策略以及该调度策略下的调度参数。当然,对于内核,这些接口都通过__sched_setscheduler这个内核函数来完成对指定线程调度策略和调度参数的修改。
__sched_setscheduler分成两个部分,首先进行安全性检查和参数检查,其次进行具体的设定。
我们先看看安全性检查。如果用户空间可以自由的修改调度策略和调度优先级,那么世界就乱套了,每个进程可能都想把自己的调度策略和优先级提升上去,从而获取足够的CPU 资源。因此用户空间设定调度策略和调度参数要遵守一定的规则:如果没有CAP_SYS_NICE的能力,那么基本上该线程能被允许的操作只是降级而已。例如从SCHED_FIFO修改成SCHED_NORMAL,异或不修改scheduling policy,而是降低静态优先级(nice value)或者实时优先级(scheduling priority)。这里例外的是SCHED_DEADLINE的设定,按理说如果进程本身的调度策略就是SCHED_DEADLINE,那么应该允许“优先级”降低的操作(这里用优先级不是那么合适,其实就是减小run time,或者加大period,这样可以放松对cpu资源的获取),但是目前的4.4.6内核不允许(也许以后版本的内核会允许)。此外,如果没有CAP_SYS_NICE的能力,那么设定调度策略和调度参数的操作只能是限于属于同一个登录用户的线程。如果拥有CAP_SYS_NICE的能力,那么就没有那么多限制了,可以从普通进程提升成实时进程(修改policy),也可以提升静态优先级或者实时优先级。
具体的修改比较简单,是通过__setscheduler_params函数完成,其实也就是是根据sched_attr中的参数设定到task struct相关成员中,大家可以自行阅读代码进行理解。
参考文档:
1、linux下的各种man page
2、linux 4.4.6内核源代码











 工商网监
工商网监
评论