 电子发烧友App
电子发烧友App


一、前言:
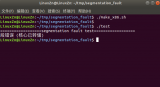
有的程序可以通过编译, 但在运行时会出现Segment fault(段错误). 这通常都是指针错误引起的. 但这不像编译错误一样会提示到文件某一行, 而是没有任何信息, 使得我们的调试变得困难起来.
gdb: 有一种办法是, 我们用gdb的step, 一步一步寻找. 这放在短小的代码中是可行的, 但要让你step一个上万行的代码, 我想你会从此厌恶程序员这个名字, 而把他叫做调试员. 我们还有更好的办法, 这就是core file.
ulimit: 如果想让系统在信号中断造成的错误时产生core文件, 我们需要在shell中按如下设置: #设置core大小为无限 ulimit -c unlimited #设置文件大小为无限 ulimit unlimited 这些需要有root权限, 在ubuntu下每次重新打开中断都需要重新输入上面的第一条命令, 来设置core大小为无限.
用gdb查看core文件: 下面我们可以在发生运行时信号引起的错误时发生core dump了. 发生core dump之后, 用gdb进行查看core文件的内容, 以定位文件中引发core dump的行. gdb [exec file] [core file] 如: gdb ./test test.core 在进入gdb后, 用bt命令查看backtrace以检查发生程序运行到哪里, 来定位core dump的文件->行.
1. 什么是Core:
Sam之前一直以为Core Dump中Core是 Linux Kernel的意思. 今天才发现在这里,Core是另一种意思:
在使用半导体作为内存的材料前,人类是利用线圈当作内存的材料(发明者为王安),线圈就叫作 core ,用线圈做的内存就叫作 core memory。如今 ,半导体工业澎勃发展,已经没有人用 core memory 了,不过,在许多情况下, 人们还是把记忆体叫作 core 。
2. 什么是Core Dump:
我们在开发(或使用)一个程序时,最怕的就是程序莫明其妙地当掉。虽然系统没事,但我们下次仍可能遇到相同的问题。于是这时操作系统就会把程序当掉 时的内存内容 dump 出来(现在通常是写在一个叫 core 的 file 里面),让 我们或是 debugger 做为参考。这个动作就叫作 core dump。
3. Core Dump时会生成何种文件:
Core Dump时,会生成诸如 core.进程号 的文件。
4. 为何有时程序Down了,却没生成 Core文件。
Linux下,有一些设置,标明了resources available to the shell and to processes。 可以使用#ulimit -a 来看这些设置。 (ulimit是bash built-in Command)
-a All current limits are reported
-c The maximum size of core files created
-d The maximum size of a process鈥檚 data segment
-e The maximum scheduling priority ("nice")
-f The maximum size of files written by the shell and its children
-i The maximum number of pending signals
-l The maximum size that m ay be locked into memory
-m The maximum resident set size (has no effect on Linux)
-n The maximum number of open file descriptors (most systems do not allow this value to be set)
-p The pipe size in 512-byte blocks (this may not be set)
-q The maximum number of bytes in POSIX message queues
-r The maximum real-time scheduling priority
-s The maximum stack size
-t The maximum amount of cpu time in seconds
-u The maximum number of processes available to a single user
-v The maximum amount of virtual memory available to the shell
-x The maximum number of file locks
从这里可以看出,如果 -c是显示:core file size (blocks, -c) 如果这个值为0,则无法生成core文件。所以可以使用:
#ulimit -c 1024 或者 #ulimit -c unlimited 来使能 core文件。
如果程序出错时生成Core 文件,则会显示Segmentation fault (core dumped) 。
5. Core Dump的核心转储文件目录和命名规则:
/proc/sys/kernel /core_uses_pid可以控制产生的core文件的文件名中是否添加pid作为扩展,如果添加则文件内容为1,否则为0
6. 如何使用Core文件:
在Linux下,使用:
#gdb -c core.pid program_name
就可以进入gdb模式。
输入where,就可以指出是在哪一行被Down掉,哪个function内,由谁调用等等。
(gdb) where
或者输入 bt。
(gdb) bt
7. 如何让一个正常的程序down:
#kill -s SIGSEGV pid
8. 察看Core文件输出在何处:
存放Coredump的目录即进程的当前目录,一般就是当初发出命令启动该进程时所在的目录。但如果是通过脚本启动,则脚本可能会修改当前目录,这时进程真正的当前目录就会与当初执行脚本所在目录不同。这时可以查看”/proc/<进程pid>/cwd“符号链接的目标来确定进程真正的当前目录地址。通过系统服务启动的进程也可通过这一方法查看。
9. 嵌入式设备下如何使用Core dump:
linux coredump配置与调试
Linux
二、Core Dump 配置与调试
1.core文件的生成开关和大小限制
---------------------------------
1)使用ulimit -c 命令可查看core文件的生成开关。若结果为0,则表示关闭了此功能,不会生成core文件。
2)使用ulimit -c filesize命令,可以限制core文件的大小(filesize的单位为kbyte)。若ulimit -c unlimited,则表示core文件的大小不受限制。如果生成的信息超过此大小,将会被裁剪,最终生成一个不完整的core文件。在调试此core文件的时候,gdb会提示错误。
2.core文件的名称和生成路径
----------------------------
若系统生成的core文件不带其它任何扩展名称,则全部命名为core。新的core文件生成将覆盖原来的core文件 。
1)/proc/sys /kernel/core_uses_pid可以控制core文件的文件名中是否添加pid作为扩展。文件内容为1,表示添加pid作为扩展名,生成的 core文件格式为core.xxxx;为0则表示生成的core文件同一命名为core。
可通过以下命令修改此文件:
echo"1" >/proc/sys/kernel/core_uses_pid
2)proc/sys/kernel/core_pattern可以控制core文件保存位置和文件名格式。
可通过以下命令修改此文件:
echo"/corefile/core-%e-%p-%t" >core_pattern,可以将core文件统一生成到/corefile目录下,产生的文件名为core-命令名-pid-时间戳
以下是参数列表:
%p - insert pid into filename 添加pid
%u - insert current uid into filename 添加当前uid
%g - insert current gid into filename 添加当前gid
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加命令名
3.用gdb查看core文件:
下面我们可以在发生运行时信号引起的错误时发生core dump了.
发生 core dump之后,用gdb进行查看core文件的内容,以定位文件中引发core dump的行.
gdb [exec file] [core file]
如:gdb ./test test.core
在进入gdb后,用 bt命令查看backtrace以检查发生程序运行到哪里,来定位core dump的文件->行.
4.开发板上使用core文件调试
-----------------------------
如果开发板的操作系统也是linux,core调试方法依然适用。如果开发板上不支持gdb,可将开发板的环境(头文件、库)、可执行文件和core文件拷贝到PC的linux下,运行相关命令即可。
注意:待调试的可执行文件,在编译的时候需要加-g,core文件才能正常显示出错信息!
注意的问题:
在Linux下要保证程序崩溃时生成 Coredump要注意这些问题:
一、要保证存放Coredump的目录存在且进程对该目录有写权限。存放Coredump 的目录即进程的当前目录,一般就是当初发出命令启动该进程时所在的目录。但如果是通过脚本启动,则脚本可能会修改当前目录,这时进程真正的当前目录就会与当初执行脚本所在目录不同。这时可以查看”/proc/进程pid>/cwd“符号链接的目标来确定进程真正的当前目录地址。通过系统服务启动的进程也可通过这一方法查看。
二、若程序调用了seteuid()/setegid()改变了进程的有效用户或组,则在默认情况下系统不会为这些进程生成Coredump。很多服务程序都会调用seteuid(),如MySQL,不论你用什么用户运行 mysqld_safe启动MySQL,mysqld进行的有效用户始终是msyql用户。如果你当初是以用户A运行了某个程序,但在ps里看到的
这个程序的用户却是B的话,那么这些进程就是调用了seteuid了。为了能够让这些进程生成core dump,需要将/proc/sys/fs/suid_dumpable 文件的内容改为1(一般默认是0)。
三、这个一般都知道,就是要设置足够大的Core文件大小限制了。程序崩溃时生成的 Core文件大小即为程序运行时占用的内存大小。但程序崩溃时的行为不可按平常时的行为来估计,比如缓冲区溢出等错误可能导致堆栈被破坏,因此经常会出现某个变量的值被修改成乱七八糟的,然后程序用这个大小去申请内存就可能导致程序比平常时多占用很多内存。因此无论程序正常运行时占用的内存多么少,要保证生成Core文件还是将大小限制设为unlimited为好。
ulimit -- 用户资源限制命令
1、说明 :ulimit用于shell启动进程所占用的资源.
2、类别 :shell内建命令
3、语法格式 :ulimit [-acdfHlmnpsStvw] [size]
4、参数介绍 :
-H 设置硬件资源限制.
-S 设置软件资源限制.
-a 显示当前所有的资源限制.
-c size:设置core文件的最大值.单位:blocks
-d size:设置数据段的最大值.单位:kbytes
-f size:设置创建文件的最大值.单位:blocks
-l size:设置在内存中锁定进程的最大值.单位:kbytes
-m size:设置可以使用的常驻内存的最大值.单位:kbytes
-n size:设置内核可以同时打开的文件描述符的最大值.单位:n
-p size:设置管道缓冲区的最大值.单位:kbytes
-s size:设置堆栈的最大值.单位:kbytes
-t size:设置CPU使用时间的最大上限.单位:seconds
-v size:设置虚拟内存的最大值.单位:kbytes 5,简单实例:
5、举例
在Linux下写程序的时候,如果程序比较大,经常会遇到“段错误”(segmentationfault)这样的问题,这主要就是由于Linux系统初始的堆栈大小(stack size)太小的缘故,一般为10M。我一般把stacksize设置成256M,这样就没有段错误了!命令为:ulimit -s 262140
如果要系统自动记住这个配置,就编辑/etc/profile文件,在 “ulimit -S -c 0 > /dev/null 2>&1”行下,添加“ulimit -s 262140”,保存重启系统就可以了!
1] 在RH8的环境文件/etc/profile中,我们可以看到系统是如何配置ulimit的:
#grep ulimit /etc/profile
ulimit -S -c 0 > /dev/null 2>&1
这条语句设置了对软件资源和对core文件大小的设置
2] 如果我们想要对由shell创建的文件大小作些限制,如:
#ll h
-rw-r--r-- 1 lee lee 150062 7月 22 02:39 h
#ulimit -f 100 #设置创建文件的最大块(一块=512字节)
#cat h>newh
File size limit exceeded
#ll newh
-rw-r--r-- 1 lee lee 51200 11月 8 11:47 newh
文件h的大小是150062字节,而我们设定的创建文件的大小是512字节x100块=51200字节,当然系统就会根据你的设置生成了51200字节的newh文件.
3] 可以像实例1]一样,把你要设置的ulimit放在/etc/profile这个环境文件中.
用途:设置或报告用户资源极限。
语法:ulimit [ -H ] [ -S ] [ -a ] [ -c ] [ -d ] [ -f ] [ -m ] [ -n ] [ -s ] [ -t ] [ Limit ]
描述:ulimit 命令设置或报告用户进程资源极限,如 /etc/security/limits 文件所定义。文件包含以下缺省值极限:
fsize = 2097151
core = 2097151
cpu = -1
data = 262144
rss = 65536
stack = 65536
nofiles = 2000
当新用户添加到系统中时,这些值被作为缺省值使用。当向系统中添加用户时,以上值通过 mkuser 命令设置,或通过 chuser 命令更改。
极限分为软性或硬性。通过 ulimit 命令,用户可将软极限更改到硬极限的最大设置值。要更改资源硬极限,必须拥有 root 用户权限。
很多系统不包括以上一种或数种极限。 特定资源的极限在指定 Limit 参数时设定。Limit 参数的值可以是每个资源中指定单元中的数字,或者为值 unlimited。要将特定的 ulimit 设置为 unlimited,可使用词 unlimited。
注:在 /etc/security/limits 文件中设置缺省极限就是设置了系统宽度极限, 而不仅仅是创建用户时用户所需的极限。
省略 Limit 参数时,将会打印出当前资源极限。除非用户指定 -H 标志,否则打印出软极限。当用户指定一个以上资源时,极限名称和单元在值之前打印。如果未给予选项,则假定带有了 -f 标志。
由于 ulimit 命令影响当前 shell 环境,所以它将作为 shell 常规内置命令提供。如果在独立的命令执行环境中调用该命令,则不影响调用者环境的文件大小极限。以下示例中正是这种情况:
nohup ulimit -f 10000
env ulimit 10000
一旦通过进程减少了硬极限,若无 root 特权则无法增加,即使返回到原值也不可能。
关于用户和系统资源极限的更多信息,请参见 AIX 5L Version 5.3 Technical Reference: BaseOperating System and Extensions Volume 1 中的 getrlimit、setrlimit 或vlimit 子例程。
标志
-a 列出所有当前资源极限。
-c 以 512 字节块为单位,指定核心转储的大小。
-d 以 K 字节为单位指定数据区域的大小。
-f 使用 Limit 参数时设定文件大小极限(以块计),或者在未指定参数时报告文件大小极限。缺省值为 -f 标志。
-H 指定设置某个给定资源的硬极限。如果用户拥有 root 用户权限,可以增大硬极限。任何用户均可减少硬极限。
-m 以 K 字节为单位指定物理存储器的大小。
-n 指定一个进程可以拥有的文件描述符的数量的极限。
-s 以 K 字节为单位指定堆栈的大小。
-S 指定为给定的资源设置软极限。软极限可增大到硬极限的值。如果 -H 和 -S 标志均未指定,极限适用于以上二者。
-t 指定每个进程所使用的秒数 。
退出状态
返回以下退出值:
0 成功完成。

















 工商网监
工商网监
评论