 电子发烧友App
电子发烧友App


一、前言
由于曾经在Linux2.6.23上工作了多年,我对这个版本还是非常有感情的(抛开感情因素,本来应该选择longterm的2.6.32版本来分析的,^_^),本文主要就是描述Linux2.6.23内核版本中对RCU有哪些修正。所谓修正主要包括两个部分,一部分是bug fixed,一部分是新增的特性。
二、issue修复
1、synchronize_kernel是什么鬼?
仅仅从符号命名上就能看出来synchronize_kernel有点格格不入,其他的rcu API都有rcu这个字符,但是synchronize_kernel没有。该函数的功能其实很多,如下:
(1)等待RCU reader离开临界区(这是大家都熟悉的功能)
(2)等待NMI的handler调用完成
(3)等待所有的interrupt handler调用完成
(4)其他
因此,该函数用途太多,最终被两个函数代替:synchronize_rcu和synchronize_sched。其中synchronize_rcu用于RCU的同步。而synchronize_sched负责其他方面的功能(本质是等待系统中所有CPU退出不可抢占区)。顺便一提的是这两个函数目前的实现代码是一样的,不过由于语义不同,后续应该会有所修改。
2、RCU callback的处理机制
为了实时性,在2.6.11内核中,如果RCU callback数目太多,那么我们会把RCU callback分在若干次的tasklet context中执行,而不是一次性的处理完毕。这样大大降低了调度延迟,不过,又带来了另外一个问题:在负荷比较重的场景,由于每次处理的callback缺省是10个,实际上更多的callback请求会挂入从而导致RCU的链表不断的增大,不断的增大……
因此,在23内核上,批量处理RCU请求的算法进行了调整,增加了三个控制变量:
static int blimit = 10;
static int qhimark = 10000;
static int qlowmark = 100;
如果说RCU是黑盒子,那么这三个变量就是控制黑盒子工作参数的旋钮,如果你对目前系统中的RCU模块工作状态不满意,可以转动这些旋钮,调整一下该模块的工作参数。blimit用来控制一次tasklet上下文中处理的RCU callback个数,类似2.6.11内核中的maxbatch。在各个CPU初始化的时候会进行下面的初始化动作:
rdp->blimit = blimit;
rdp->blimit 是真正控制算法的变量,初始化的时候等于blimit,在运行过程中,该值是动态变化的,具体如何变是根据两个watermark来处理的:qhimark是上限水位,qlowmark 是下限水位。此外,在struct rcu_data数据结构中也增加了一个qlen成员来跟踪目前RCU callback的数目。每次提交一个RCU callback,qlen就加一。当渡过GP之后,调用RCU callback函数的时候qlen减一。
在了解了上述基础信息之后,我们一起看看call_rcu的代码:
if (unlikely(++rdp->qlen > qhimark)) {
rdp->blimit = INT_MAX;-----------------(1)
force_quiescent_state(rdp, &rcu_ctrlblk);---------(2)
}
如果qlen太大,超过了qhimark水位,说明提交的RCU callback太多,tasklet已经忙不过来了,这时候,必须采取两个措施:
(1)不再限制每次tasklet context中处理的请求个数。
(2)加快GP,让各个CPU快点通过QS。如何做呢?其实至于强迫每个CPU上都进行一个进程切换就OK了。对于本CPU可以直接调用set_need_resched,对于其他CPU,只能是调用send_ipi_message函数发送ipi message,以便让其他CPU自己进行进程调度。
看完上限水位的处理,我们再一起看看下限水位如何处理,在rcu_do_batch中:
if (rdp->blimit == INT_MAX && rdp->qlen <= qlowmark)
rdp->blimit = blimit;
当我们采用了上面所说的方法双管齐下,qlen应该会不断的减少,当触及下限水位的时候,将rdp->blimit的值恢复正常。
3、rcu_start_batch函数中的race issue
2.6.11中rcu_start_batch函数的部分代码如下:
if (rcp->next_pending && rcp->completed == rcp->cur) {
cpus_andnot(rsp->cpumask, cpu_online_map, nohz_cpu_mask); -------Arcp->next_pending = 0;
smp_wmb();
rcp->cur++;------------------------------B
}
当重新启动一个批次的RCU callback的Grace Period探测的时候,需要reset cpumask,设置next_pending以及给当前的批次号加一。这里访问了nohz_cpu_mask这个全局变量,主要是为了减轻检测各个CPU通过Quiescent state的工作量,毕竟那些进入idle状态的CPU其实是没有进行QS的检查(注意:这里仅仅限于dynamic tick的情况,对于周期性tick而言,nohz_cpu_mask总是等于0)。不过,如果是上面的代码逻辑,A点和B点之间,如果CPU进入了IDLE,那么这会导致已经进入idle的CPU也进入cpumask,从而延长的GP的时长。如何修正呢?很简单,将A处的代码放到B之后。
rcu_start_batch函数还有一个小改动,去掉了next_pending参数,改由调用者设定。
4、合并了struct rcu_ctrlblk和struct rcu_state
除了让参数传递变得繁琐,rcu控制块分成两个数据结构是没有什么意义的。
三、新增的功能
1、增加rcu_barrier
有些特殊的场合(例如卸载模块或者umount文件系统)需要当前的所有的RCU callback(也包括nxtlist链表中的刚刚提交请求的那些)都执行完毕。注意:是callback执行完毕而不是仅仅渡过Grace Period。我们可以举一个实际的例子:比如文件系统的unmount函数中一般会释放该文件系统特定的super block数据结构实例,但是,如果RCU callback中还需要操作这个文件系统特定的super block数据结构实例的时候(比如在callback中将该数据结构实例从链表中摘除),在这样的场景中,unmount函数必须要要等到RCU callback执行完毕之后才能free该文件系统特定的super block数据结构实例。
具体如何实现倒是比较简单。每个CPU都定义一个特别用于rcu barrier的callback请求,具体在struct rcu_data数据结构中的barrier成员:
struct rcu_head barrier;
一旦用户调用rcu_barrier函数,那么就在各个CPU上提交这个barrier的请求。如果每一个CPU上的barrier这个RCU callback已经执行完毕,那么就说明系统中所有的(在调用rcu_barrier那一点)callback都已经执行完毕。为了跟踪每一个CPU上的barrier执行情况,需要一个counter:
static atomic_t rcu_barrier_cpu_count;
该counter初始值是0,提交barrier请求的时候该count加一,渡过Grace Period之后,在callback函数中减一,当该counter减到0值的时候,说明所有的CPU的barrier callback函数都执行完毕,也就意味着当前的所有的RCU callback都执行完毕。
2、增加rcu_needs_cpu
在RCU模块发展的同时,其他的内核子系统也不断在演进,例如时间子系统。当一个CPU由于无事可做而进入idle的时候,关闭周期性的tick可以节省功耗,这也就是传说中的tickless(或者dynamic tick)特性。我们首先假设CPU A处于这样的状态:
(1)没有新的请求,即nxtlist链表为空
(2)curlist链表有待处理的批次,虽然分配了批次号,但是还没有启动该批次,也就是说该批次是pending的
(3)当前批次在本cpu的QS状态已经检测通过
(4)没有处理中的callback请求,即donelist链表为空
在这种状态下,周期性tick到来的时候,其实没有什么相关的RUC事情要处理,这时候,__rcu_pending返回0。在这种情况下,似乎停掉tick应该是OK的,但是假设我们停掉了CPU A的tick,让该CPU进入idle状态。如果CPU B是最后一个pass QS的CPU,这时候,该CPU会调用rcu_start_batch启动pending的那个批次(CPU A的curlist上的请求就是该批次的),由于要启动一个新的批次进行GP的检测,因此在该函数中会reset cpumask,代码如下:
cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask);
如果CPU A进入了idle state,并停掉了tick,那么cpumask将不处理CPU A的QS状态,但是,curlist上的请求其实就是该批次的。怎么办?应该在curlist仍然有请求的时候,禁止该CPU进入idle state并停掉tick,因此时间子系统需要RCU欧酷提供一个接口函数,用来收集RCU是否还需要该CPU的信息,这个接口就是rcu_needs_cpu。
3、增加srcu
SRCU其实就是sleepable RCU的缩写,而我们常说的RCU实际上是classic RCU,也就是在reader critical section中不能睡眠的,其在临界区内的代码要求是spin lock一样的。也正因为如此,我们可以在进程调度的时候可以判断该CPU的QS已经通过。SRCU是一个RCU的变种,从名字上也可以看出来,其reader critical section中可以block。一旦放开了这个口子,classic RCU所搭建的一切轰然倒塌,因此,直觉上SRCU是不可能实现的:
(1)一旦在reader critical section中sleep,那么GP就变得非常长了,一直要等到该进程被唤醒并调度执行,这么长的GP系统怎么受得了?毕竟系统需要在GP渡过之后,在callback中释放资源
(2)进程切换的时候判断通过QS的机制失效
不过,realtime linux kernel要求不可抢占的临界区要尽量的短,在这样的需求背景下,spin lock的临界区都因此而修改成为preemptible(只有raw spin lock保持了不可抢占的特性),RCU的临界区也不能豁免,必须作出相应的改动,这也就是srcu的源由。
既然sleepable RCU势在必行,那么我们必须要面对的问题就是如何减少RCU callback请求的数量,要知道SRCU的GP可能非常的长。解决方法如下:
(1)不再提供GP的异步接口(也就是call_rcu API),仅仅保留同步接口。如果提供了call_srcu这样的接口,那么每一个使用rcu的线程可以提交任意多的RCU callback请求。而同步接口synchronize_srcu(类似RCU的synchronize_rcu接口)会阻塞当前的thread,因此可以确保一个线程只会提交一个请求,从而大大降低请求的数目。
(2)细分GP。classic RCU的GP是一个批次一个批次的处理,一个批次的GP是for整个系统的,换句话说,一个RCU reader side临界区如果delay了,那么整个系统的RCU callback都会delay。对于SRCU而言,虽然GP比较长,但是如果能够将使用SRCU的各个内核子系统隔离开来,每个子系统都有自己GP,也就是说,一个RCU reader side临界区如果delay了,那么只是影响该子系统的RCU callback请求处理。
根据上面的思路,在linux2.6.23内核中提供了SRCU机制,提供如下的API:
int init_srcu_struct(struct srcu_struct *sp);
void cleanup_srcu_struct(struct srcu_struct *sp);
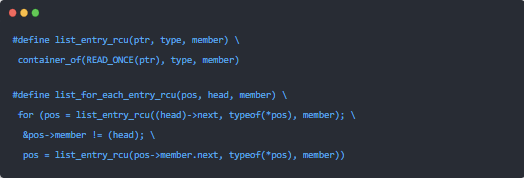
int srcu_read_lock(struct srcu_struct *sp) __acquires(sp);
void srcu_read_unlock(struct srcu_struct *sp, int idx) __releases(sp);
void synchronize_srcu(struct srcu_struct *sp);
由于分隔了各个子系统的GP,因此各个子系统需要一个属于自己的struct srcu_struct数据结构,可以静态定义也可以动态分配,但是都需要调用init_srcu_struct来初始化。如果struct srcu_struct数据结构是动态分配,那么在free该数据结构之前需要调用cleanup_srcu_struct来释放占用的资源。srcu_read_lock和srcu_read_unlock用来界定SRCU的临界区范围,struct srcu_struct数据结构做为该子系统的SRCU句柄传递给srcu_read_lock和srcu_read_unlock是可以理解的,但是idx是什么鬼?srcu_read_lock返回了idx,并做为参数传递给srcu_read_unlock函数,告知GP相关信息,具体后面会进行描述。synchronize_srcu和synchronize_rcu行为类似,都是阻塞当前进程,直到渡过GP之后才会继续执行,不同的是,synchronize_srcu需要struct srcu_struct参数来指明是哪一个子系统的SRCU。
OK,了解了原理和API之后,我们来看看内部实现。对于一个具体的某个子系统中的SRCU而言,三个控制数据就可以完成SRCU的逻辑:
(1)用一个全局变量来跟踪系统中的GP。为了方便,我们可以给GP编号,从0开始,每渡过一个GP,该ID就会加1。如果当前线程阻塞在synchronize_srcu,等到ID=a的GP过去,那么a+1就是pending的GP(也就是下一个要处理的GP ID)。struct srcu_struct中的completed成员就是起这个作用的。
(2)记录各个GP中的位于reader critical section中的数目。当然了,随着系统的运行,各个GP不断的渡过,ID不断的增加,但是在某个具体的时间点上,实际上不需要记录每一个GP的reader临界区的counter,只需要记录current和next pending两个reader临界区的counter就OK了。为了性能,在2.6.23内核中,这个counter是per cpu的,也就是struct srcu_struct中的per_cpu_ref成员,具体的counter定义如下:
struct srcu_struct_array {
int c[2];
};
c[0]和c[1]的counter是不断的toggle的,如果c[0]是current,那么c[1]就是next pending,如果c[1]是current,那么c[0]就是next pending,具体如何选择是根据struct srcu_struct中的completed成员的LSB的那个bit决定的。
根据上面的描述,我们来进行逻辑解析。首先看srcu_read_lock的,该函数的逻辑很简单,就是根据next pending ID(保存在completed成员)的LSB bit确定counter的位置,给这个counter加一。当然srcu_read_unlock执行相反的动作,略过。由于srcu_read_lock和srcu_read_unlock之间有可能会调用synchronize_srcu导致锁定当前pending的状态并将GP ID(也就是completed成员)加一,因此,srcu_read_unlock需要一个额外的index参数,用来告知应该选择哪一个counter。
synchronize_srcu的逻辑也很简单,首先要确定当前GP ID。也就是说,之前next pending的那个就变成current(说的很玄,本质就是选择哪一个counter,c[0]还是c[1]),completed++让随后的srcu_read_lock调用更换到另外一个counter中,成为next pending。然后等待current的counter在各个CPU上的计数变成0。一旦counter计数等于0则返回,说明GP已经过去。
四、参考文献
1、2.6.23 source code
2、https://lwn.net/Articles/202847/












 工商网监
工商网监
评论