 电子发烧友App
电子发烧友App


前 言
虽然CPU主频的提升会带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构、指令结构、信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特别是与CPU/内存之间的存取速度有关。若CPU工作速度较高,但内存存取速度较低,则造成CPU等待,降低处理速度,浪费CPU的能力。如500MHz的PⅢ,一次指令执行时间为2ns,与其相配的内存(SDRAM)存取时间为10ns,比前者慢5倍,CPU和PC的性能怎么发挥出来?
如何减少CPU与内存之间的速度差异?有4种办法:一种是在基本总线周期中插入等待,这样会浪费CPU的能力。另一种方法是采用存取时间较快的SRAM作存储器,这样虽然解决了CPU与存储器间速度不匹配的问题,但却大幅提升了系统成本。第3种方法是在慢速的DRAM和快速CPU之间插入一速度较快、容量较小的SRAM,起到缓冲作用;使CPU既可以以较快速度存取SRAM中的数据,又不使系统成本上升过高,这就是Cache法。还有一种方法,采用新型存储器。目前,一般采用第3种方法。它是PC系统在不大增加成本的前提下,使性能提升的一个非常有效的技术。
本文简介了Cache的概念、原理、结构设计以及在PC及CPU中的实现。
Cache的工作原理
Cache的工作原理是基于程序访问的局部性。
对大量典型程序运行情况的分析结果表明,在一个较短的时间间隔内,由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内。指令地址的分布本来就是连续的,再加上循环程序段和子程序段要重复执行多次。因此,对这些地址的访问就自然地具有时间上集中分布的倾向。数据分布的这种集中倾向不如指令明显,但对数组的存储和访问以及工作单元的选择都可以使存储器地址相对集中。这种对局部范围的存储器地址频繁访问,而对此范围以外的地址则访问甚少的现象,就称为程序访问的局部性。
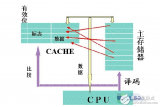
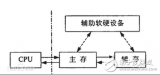
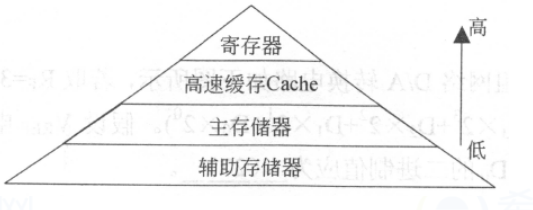
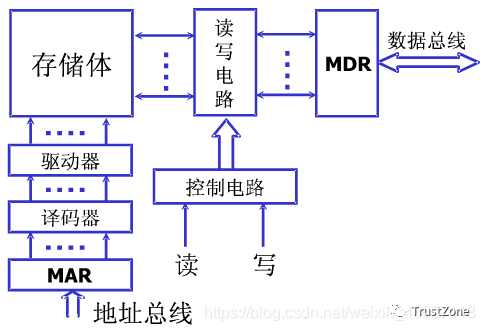
根据程序的局部性原理,可以在主存和CPU通用寄存器之间设置一个高速的容量相对较小的存储器,把正在执行的指令地址附近的一部分指令或数据从主存调入这个存储器,供CPU在一段时间内使用。这对提高程序的运行速度有很大的作用。这个介于主存和CPU之间的高速小容量存储器称作高速缓冲存储器(Cache)。
系统正是依据此原理,不断地将与当前指令集相关联的一个不太大的后继指令集从内存读到Cache,然后再与CPU高速传送,从而达到速度匹配。CPU对存储器进行数据请求时,通常先访问Cache。由于局部性原理不能保证所请求的数据百分之百地在Cache中,这里便存在一个命中率。即CPU在任一时刻从Cache中可靠获取数据的几率。命中率越高,正确获取数据的可靠性就越大。一般来说,Cache的存储容量比主存的容量小得多,但不能太小,太小会使命中率太低;也没有必要过大,过大不仅会增加成本,而且当容量超过一定值后,命中率随容量的增加将不会有明显地增长。只要Cache的空间与主存空间在一定范围内保持适当比例的映射关系,Cache的命中率还是相当高的。一般规定Cache与内存的空间比为4:1000,即128kB Cache可映射32MB内存;256kB Cache可映射64MB内存。在这种情况下,命中率都在90%以上。至于没有命中的数据,CPU只好直接从内存获取。获取的同时,也把它拷进Cache,以备下次访问。
Cache的基本结构
Cache通常由相联存储器实现。相联存储器的每一个存储块都具有额外的存储信息,称为标签(Tag)。当访问相联存储器时,将地址和每一个标签同时进行比较,从而对标签相同的存储块进行访问。
Cache的3种基本结构如下:
全相联Cache
在全相联Cache中,存储的块与块之间,以及存储顺序或保存的存储器地址之间没有直接的关系。程序可以访问很多的子程序、堆栈和段,而它们是位于主存储器的不同部位上。因此,Cache保存着很多互不相关的数据块,Cache必须对每个块和块自身的地址加以存储。当请求数据时,Cache控制器要把请求地址同所有地址加以比较,进行确认。这种Cache结构的主要优点是,它能够在给定的时间内去存储主存器中的不同的块,命中率高;缺点是每一次请求数据同Cache中的地址进行比较需要相当的时间,速度较慢。
表1 pc中部分已实现的cache技术
系统
l0
l1cache
l2cache
l3cache
cache
主存储器
8088
无
无
无
无
dram
80286
无
无
无
无
无
dram
80386dx
无
外部sram
无
无
sram
dram
80486dx
无
内部8kb
外部sram
无
sram
dram
pentium
无
内部8kb+8kb
外部sram
无
sram
dram
ppro
无
内部8kb+8kb
内部封装256kb或512kb
无
sram
dram
mmx
无
内部16kb+16kb
外部sram
无
sram
dram
pⅡ/pⅢ
无
内部16kb+16kb
卡上封装512kb~1mb
无
sram
dram
k6-Ⅲ
内部32kb+32kb
芯片背上封装256kb
外部1mb
sram
dram
直接映像Cache
直接映像Cache不同于全相联Cache,地址仅需比较一次。在直接映像Cache中,由于每个主存储器的块在Cache中仅存在一个位置,因而把地址的比较次数减少为一次。其做法是,为Cache中的每个块位置分配一个索引字段,用Tag字段区分存放在Cache位置上的不同的块。单路直接映像把主存储器分成若干页,主存储器的每一页与Cache存储器的大小相同,匹配的主存储器的偏移量可以直接映像为Cache偏移量。Cache的Tag存储器(偏移量)保存着主存储器的页地址(页号)。以上可以看出,直接映像Cache优于全相联Cache,能进行快速查找,其缺点是当主存储器的组之间做频繁调用时,Cache控制器必须做多次转换。
组相联Cache
组相联Cache是介于全相联Cache和直接映像Cache之间的一种结构。这种类型的Cache使用了几组直接映像的块,对于某一个给定的索引号,可以允许有几个块位置,因而可以增加命中率和系统效率。
Cache与DRAM存取的一致性
在CPU与主存之间增加了Cache之后,便存在数据在CPU和Cache及主存之间如何存取的问题。读写各有2种方式。
贯穿读出式(Look Through)
该方式将Cache隔在CPU与主存之间,CPU对主存的所有数据请求都首先送到Cache,由Cache自行在自身查找。如果命中,则切断CPU对主存的请求,并将数据送出;不命中,则将数据请求传给主存。该方法的优点是降低了CPU对主存的请求次数,缺点是延迟了CPU对主存的访问时间。
旁路读出式(Look Aside)
在这种方式中,CPU发出数据请求时,并不是单通道地穿过Cache,而是向Cache和主存同时发出请求。由于Cache速度更快,如果命中,则Cache在将数据回送给CPU的同时,还来得及中断CPU对主存的请求;不命中,则Cache不做任何动作,由CPU直接访问主存。它的优点是没有时间延迟,缺点是每次CPU对主存的访问都存在,这样,就占用了一部分总线时间。
写穿式(Write Through)
任一从CPU发出的写信号送到Cache的同时,也写入主存,以保证主存的数据能同步地更新。它的优点是操作简单,但由于主存的慢速,降低了系统的写速度并占用了总线的时间。
回写式(Copy Back)
为了克服贯穿式中每次数据写入时都要访问主存,从而导致系统写速度降低并占用总线时间的弊病,尽量减少对主存的访问次数,又有了回写式。它是这样工作的:数据一般只写到Cache,这样有可能出现Cache中的数据得到更新而主存中的数据不变(数据陈旧)的情况。但此时可在Cache 中设一标志地址及数据陈旧的信息,只有当Cache中的数据被再次更改时,才将原更新的数据写入主存相应的单元中,然后再接受再次更新的数据。这样保证了Cache和主存中的数据不致产生冲突。
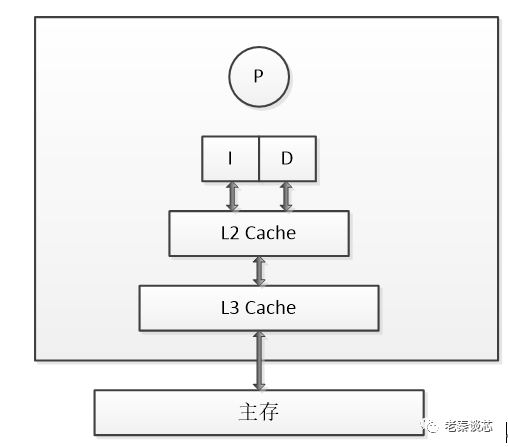
Cache的分级体系设计
微处理器性能由如下几种因素估算:性能=k(fⅹ1/CPI-(1-H)ⅹN) 式中:k为比例常数,f为工作频率,CPI为执行每条指令需要的周期数,H为Cache的命中率,N为存储周期数。
虽然,为了提高处理器的性能,应提高工作频率,减少执行每条指令需要的周期数,提高Cache的命中率。同时分发多条指令和采用乱序控制,可以减少CPI值;采用转移预测和增加Cache容量,可以提高H值。为了减少存储周期数N,可采用高速的总线接口和不分块的Cache方案。以前提高处理器的性能,主要靠提高工作频率和提高指令级的并行度,今后则主要靠提高Cache的命中率。设计出无阻塞Cache分级结构。
Cache分级结构的主要优势在于,对于一个典型的一级缓存系统的80%的内存申请都发生在CPU内部,只有20%的内存申请是与外部内存打交道。而这20%的外部内存申请中的80%又与二级缓存打交道。因此,只有4%的内存申请定向到DRAM中。
Cache分级结构的不足在于高速缓存组数目受限,需要占用线路板空间和一些支持逻辑电路,会使成本增加。综合比较结果还是采用分级Cache。
L1 Cache的设计有在片一级分离和统一设计两种方案。
Intel、AMD、原DEC等公司将L1 Cache设计成指令Cache与数据Cache分离型。因为这种双路高速缓存结构减少了争用高速缓存所造成的冲突,改进了处理器效能,以便数据访问和指令调用在同一时钟周期内进行。
但是,仅依靠增加在片一级Cache的容量,并不能使微处理器性能随之成正比例地提高,还需设置二级Cache。
在L1 Cache结构方面,一般采用回写式静态随机存储器(SRAM)。目前,L1 Cache容量有加大的趋势。
L2 Cache的设计分芯片内置和外置两种设计。
如AMD K6-3内置的256kB L2 Cache与CPU同步工作。外置L2 Cache,一般都要使二级Cache与CPU实现紧密耦合,并且与在片一级Cache形成无阻塞阶层结构。同时还要采用分离的前台总线(外部I/O总线)和后台总线(二级Cache总线)模式。显然,将来随着半导体集成工艺的提高,如果CPU与二级Cache集成在单芯片上,则CPU与二级Cache的耦合效果可能更佳。
由于L2 Cache内置,因此,还可以在原主板上再外置大容量缓存1MB~2MB,它被称为L3 Cache。
PC中的Cache技术的实现
PC中Cache的发展是以80386为界的。主要内容请参见“跟着CPU的脚步”一文。
目前,PC中部分已实现的Cache技术如表1所示。
结 语
目前,PC系统的发展趋势之一是CPU主频越做越高,系统架构越做越先进,而主存DRAM的结构和存取时间改进较慢。因此,Cache技术愈显重要,在PC系统中Cache越做越大。广大用户已把Cache做为评价和选购PC系统的一个重要指标。本文小结了Cache的源脉。希望可以给广大用户一个较系统的参考。



















 工商网监
工商网监
评论