 电子发烧友App
电子发烧友App


作者简介:
-
一、编译系统的形成与发展
-
二、编译系统的逻辑结构
-
2.1 狭义编译
-
2.2 最狭义编译
-
2.3 链接过程
-
2.4 组建系统
-
-
三、编译原理简介
-
3.1 词法分析
-
3.2 语法分析
-
3.3 语义分析
-
3.4 中间码生成
-
3.5 中间码优化
-
3.6 机器码生成
-
3.7 机器码优化
-
3.8 小型编译器推荐
-
-
四、静态链接与动态链接
-
4.1 静态链接
-
4.2 动态链接
-
4.3 实例解析
-
-
五、总结回顾
一、编译系统的形成与发展
什么是编译器?为什么要有编译器?编译器的作用是什么?编译系统的组成部分有哪些,它们之间的关系是什么?有一句名言说的非常好:了解一件事情最好从它的历史开始。要想对整个编译系统有个全面透彻地理解,我们就必须要先去认真研究它的发展历史。下面我们就来看一下编译系统的发展历史。
1.1 手工硬件编程
最早开始的时候,我们是手工硬件编程,注意是手工硬件编程,不是面向硬件编程。手工硬件编程是程序员直接用手去改变计算机中的跳线连接方式来编程。把所有的跳线连接都改完之后,插上电源,按执行按钮,计算机就可以执行程序了。很显然这种编程方式很原始、很low、很麻烦。如果我们有两个程序A和B,我们执行完A之后想要执行B,就要先把A毁掉之后再把B给手工编到硬件上去才能执行B。下次再需要执行A的时候还需要重新再把A编到硬件上。这是多么的麻烦,于是大神冯诺依曼就提出了一个想法叫做存储程序设计,就是我们把程序存储到存储器上,计算机每次运行的时候都去存储器读指令来执行就可以了。存储程序设计是一个非常伟大的想法,是计算机历史上发展的一大步。以前当我看到书上对存储程序设计大加赞赏时,我就非常疑惑不解,存储程序,还用你说,程序不是本来就存在硬盘上吗,这不是理所应当的吗,这有什么好夸奖的。当我们对一个东西习以为常、司空见惯的时候,我们就会觉得这个东西没什么,但是实际上这个东西的提出或者发明是非常伟大的。就好比我们都站着走路觉得这个没什么,这不是应该的吗,本来就是这样。但是实际上人类直立行走是人从动物进化到人的过程中非常重要的一步,如果没有直立行走,人类现在说不定还是生活在原始森林里的动物。好,我们接着往下说,有了存储程序设计,我们就从手工硬件编程进化到了面向硬件编程。
1.2 面向硬件编程
面向硬件编程又分为1.0 二进制编程、2.0 手工汇编编程、3.0 汇编编程三个版本。由于计算机硬件采取的是二进制实现方式,所以1.0版本的面向硬件编程就是二进制编程,就是直接用一堆0110101来编程。计算机为什么要采用二进制的方式来实现而不是采用人类最熟悉的十进制方式或者其他进制方式来实现呢?这里面有多个原因,首先是因为二进制是最简单的进制,不可能有比二进制更简单的进制了。二是因为硬件的很多特征正好可以简单对应到二进制的0和1上,比如高电压是1,低电压是0,通路是1,断路是0,非常方便,便于实现。三是因为逻辑运算布尔代数正好可以对应到二进制0和1上。如果采取3进制、5进制、8进制、10进制,将会面临着很多的麻烦。采用二进制也存在一个问题,就是人类熟悉10进制,不熟悉2进制,这个问题可以通过在显示的时候把2进制转换为10进制来解决,人们用电脑时看到的都会是10进制数,没有影响。
有了二进制编程,我们就可以直接书写处理器能直接识别和执行的二进制指令来编程了,比手工硬件编程方便了很多。但是显然直接书写一堆0110101的代码,很违背直觉,很难写,也很容易出错。如果不小心把某个0写成了1,想把这个错误找出来都非常困难。于是人们想出了一个方法,我先在草稿纸上用伪代码编程,比如,加法的指令是10101010,我先用 ADD 来代替。等把程序写好了,我再一个一个地把 ADD SUB JMP 等这些指令助记符手工转换成0110,再输入到电脑上去执行。我们把这种编程方式叫做手工汇编编程,这种编程方式和手工硬件编程、二进制编程相比都有很大的进步,但是依然很麻烦。于是我们就想,把助记符转换成二进制指令的这个过程,我能不能用程序来实现呢,何必非要自己手工去做呢,于是就有了汇编器程序。我们把二进制指令叫做机器语言,把助记符指令叫做汇编语言,你用汇编语言写的程序叫做汇编程序,汇编器程序把你写的汇编程序转换成二进制程序,然后就可以运行了。汇编器程序也是程序啊,该用什么语言来写呢,显然此时只能用二进制编程或者手工汇编编程来写汇编器程序,我们把这个汇编器叫做盘古汇编器。盘古汇编器的特点是它是手工产生的,不需要汇编或者编译来生成。盘古汇编器有了之后,就可以对所有的汇编程序进行汇编了,此时我们就进入了汇编编程时代。既然所有的程序都能用汇编语言编写了,那么我们能不能用汇编语言再写一个汇编器呢,答案是能,我们把这个汇编器叫做女娲汇编器。我们用盘古汇编器汇编女娲汇编器的源码,得到二进制的女娲汇编器,然后就可以用二进制的女娲汇编器汇编女娲汇编器的源码,又得到了新的二进制女娲汇编器。从此我们就可以抛弃盘古汇编器了,实现二进制女娲汇编器和源码女娲汇编器的鸡生蛋、蛋生鸡的循环了。我们就可以不断地改善女娲汇编器的源码,实现女娲汇编器的进化,并且还可以编译其他汇编程序。
第一个编译器是怎么来的?
在此我们提前回答一个问题,编译器也是程序,也需要被编译,那么第一个编译器是怎么来的,是谁编译的呢。第一个C语言编译器是用B语言写的,用B语言编译器编译的,有个这个盘古C语言编译器,我们就可以再用C语言来重新写一个C语言编译器了,叫做女娲C语言编译器。用二进制的C语言盘古编译器编译源码形式的女娲C语言编译器,就得到了二进制的女娲C语言编译器,然后二进制的女娲C语言编译器再去编译源码形式的女娲C语言编译器,就可以实现类似女娲汇编器的循环了。同理你会问那么第一个B语言编译器是怎么来的呢,第一个B语言编译器是用BCPL语言书写的,是用BCPL语言编译器编译的。一直这么追问下去,第一个编译器是怎么实现的呢?第一个编译器是用汇编语言写的,汇编器汇编出来的。再往前推,第一个汇编器是手工书写的二进制代码。所以编译器的源头是我们人类直接用机器语言书写的盘古汇编器,它不需要编译也不需要汇编,能直接在机器上运行。
1.3 高级语言编程
面向硬件编程3.0版本–汇编编程,虽然已经很先进了,但它仍然是面向硬件编程啊,程序员仍然需要了解很多的硬件细节,不能专注于程序自身的逻辑。实际上绝大部分程序,它的功能实现都和硬件无关,而且用汇编语言写的程序不具有跨平台性,程序员要为每个硬件平台都写一份程序或者要移植一下,这非常麻烦。能不能发明一种语言,屏蔽各种硬件细节,只注重于实现程序自身的逻辑,实现源码级的跨平台性呢,于是高级语言诞生了。第一个高级语言大概是Algol吧,然后从Algol一路发展到BCPL、B、C、C++、JAVA、C# 等。在高级语言里面没有各种硬件指令,没有寄存器,没有复杂的寻址模式,取而代之的是各种数据类型的数据定义,和对数据的直观操作,以及if、for、while、switch等控制语句,还有一些更高级的语法构造如类、模板等,都是用接近于人类自然语言的方式来表达的,可读性非常强。如果想要了解学习一些高级语言,如C和C++,可以参看《深入理解C与C++》。
编译器的定义:好,说到这里,大家对什么是编译器心里应该已经很明白了。我们来总结一下,什么是编译器,编译器是人类和计算机之间的一个矛盾的产物。这个矛盾就是计算机能够理解和执行二进制格式的程序却不能理解和执行文本格式的程序。而人类正好相反,人类能理解和书写文本格式的程序却难以理解和书写二进制格式的程序。于是编译器出现了,用来帮助人类解决这个矛盾。人类书写文本格式的程序,编译器给翻译成二进制格式的程序,计算机再来执行。
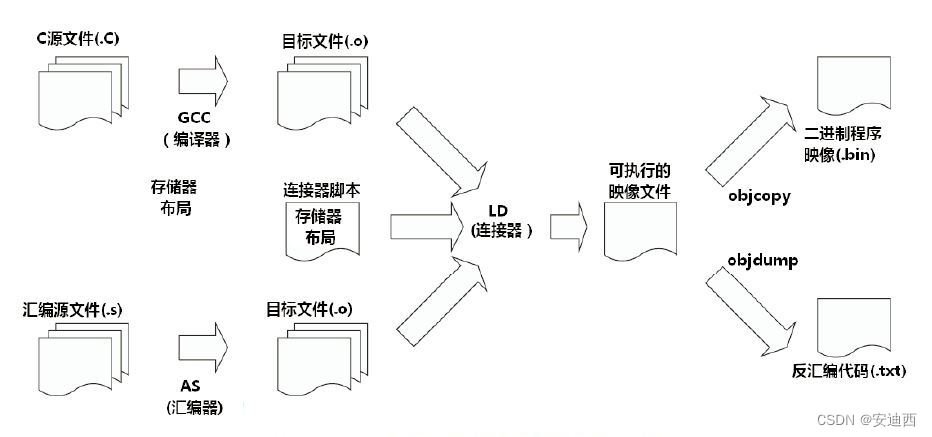
1.4 编译系统的组成
上面我们把什么是编译器给解释清楚了,我们再继续顺着这个思路来解释一下什么是链接、加载和组建。刚开始的时候,程序都很简单,一个C文件就搞定了,我们可以把一个C文件直接编译成可执行程序。但是后来随着程序越来越庞大,再把程序全写到一个C文件里就不合适了,一个C文件写几千行还算合理,但是写几万行,几十万行甚至几百万行就不合理了。于是我们把程序写到多个文件里,每个文件单独编译,生成中间目标文件,再把这些中间目标文件连接合并成一个可执行程序,这个连接合并过程就叫做链接,执行链接的程序叫做链接器。后来随着程序的更加复杂庞大,这种链接方式也有问题,因为有很多公共程序,你把它们都链接到每个程序中,这样每个程序都自己包含一份库程序,这会导致浪费大量的磁盘空间,而且运行时也很浪费物理内存,如果一个库程序更新了,每个可执行程序都要重新链接一遍,也很麻烦。为了解决这几个问题,于是诞生了动态链接,于是就把之前的链接方式叫做静态链接。我们把一些公共库程序做成动态链接库,每个可执行程序链接到动态库时只是在程序内部做了一个链接记录,并不会把动态库复制到可执行程序本身,这样整个磁盘里面就只有一份这个动态库。运行时,这个动态库也只需要加载进物理内存一次,然后分别映射到不同进程的虚拟内存空间中就可以了,这个动作叫做加载。至此我们明白了编译、链接、静态链接、动态链接、加载这几个概念,做编译的是编译器,做链接的是链接器,做加载的是加载器。
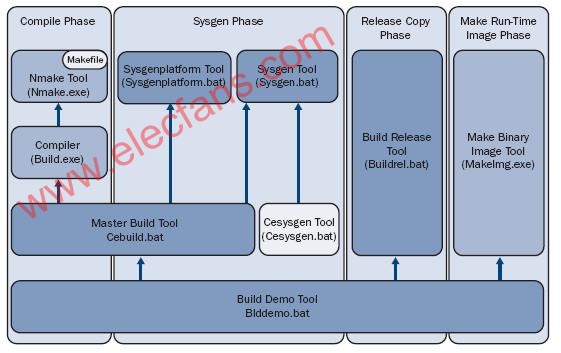
下面我们说一说什么是组建,假设我们有个软件由十几个文件夹几百个C文件组成,我们每次想编译时该怎么做,一个一个地编译每个C文件,然后再把所有的中间目标文件静态链接、动态链接起来生成最终的可执行程序,每次都手工输入那么多命令是多么麻烦啊。我们该怎么办,一个最简单直接的方式是把这些命令都写到脚本里,后面每次都执行这个脚本就可以了。这个想法很好,也解决了问题,但是还存在问题,就是写这个脚本比较麻烦,修改这个脚本也比较麻烦。于是就出现了一些可以自动生成这个脚本的方法,你写一些简单的配置和规则,然后用一个程序处理这个规则,就可以自动生成这个脚本,再执行这个脚本就可以编译整个程序了。后来你发现,你的解析程序解析你的规则文件后,直接在内部生成这个脚本执行这个脚本就可以了,没必要非要把这个脚本显式地写出来再去执行,这一套东西就叫做组建系统。组建系统由两部分组成,解析程序和规则文件。最著名的组建系统就是make了,make由两部分组成,make程序和Makefile文件。你按照Makefile的要求去书写Makefile文件,然后执行make命令就可以编译整个程序了。后来随着程序的更加庞大和复杂化,Makefile也变得越来越庞大越难以书写了,于是又产生了元组建系统,来帮你生成Makefile文件。元组建系统也由两部分组成,解析程序和规则文件,你按照它的要求书写规则文件,然后执行解析程序生成Makefile,然后再执行make命令编译整个程序。针对make的比较著名的元组建系统有CMake、autoconf/automake等。由于make运行时需要把每个文件夹下Makefile都include进来,这对于小规模的程序来说还能忍受,但是当程序非常庞大、源码下的文件夹比较多的时候,这个耗时就难以忍受了,于是人们开发出了ninja组建系统,它运行时只解析一个build文件,运行效率就比较高。不过要手工写ninja的build文件是很麻烦的,对大型程序来说几乎是不现实的,所以对ninja组建系统几乎是必配元组建系统,当只修改源码内容时可以直接运行ninja命令,但是当程序结构发生变化时必须要先运行一下元组建系统重新生成一下ninja的build文件。
现在我们看到整个编译系统由3部分组成,编译、链接、组建,执行它们的分别是编译器、链接器、组建系统。我们在命令行编译一个程序的时候,只需要调用一个组建命令,组建系统就会帮我们自己编译、链接整个程序,还会做一些其他辅助工作如打包、签名等。有些同学可能会说我从来没用过什么编译器、链接器、组建系统,我每次编程都是直接写程序,然后直接按一个按钮就行了,这个东西就叫做集成开发环境,它把文本编辑器、编译器、链接器、组建系统、调试器都集成在一起了,可以方便大家的开发工作,但也使得很多人都不了解它背后的工作原理。所以说命令行虽然不太好用,但是它的不太好用是指学会用它比较麻烦,但是一旦学会用它,你会发现它非常强大,而且同时你对它背后的原理也理解地比较深刻。
很多时候我们在工作的时候会经常说到编译这个词,但是在不同的场景下它的含义是不一样的。下面我们来进行一下名词解析,说一下编译的四种不同含义:
- 最广义的编译:就是组建过程,包括编译、链接、打包、签名等
- 广义的编译:包括狭义的编译和链接
- 狭义的编译:就是单指编译,把源文件编译成目标文件的过程
- 最狭义的编译:就是编译原理中的编译,不包括开头的预处理和最后的汇编过程(如果有的话)。
编译原理里面讲的编译就是指这个最狭义的编译,一般是没有这个汇编过程的,就是直接生成目标文件,如果有汇编过程的则不包括汇编过程,很多编译器采取的方式是有汇编的过程的。
为什么要在这里做个名词解析呢,因为在工作和一些讨论中会因为大家说的编译这个词的含义不同而产生一些说不清的争论。比如说我们在编译整个程序的时候,我们只会说编译这个程序,而不会去说组建这个程序,也不会去说编译加链接加打包这个程序,这样说会显得很别扭,所以很多时候会因为编译的含义不同而产生一些不必要的争论。例如有一次服务器编译出错了,我说编译出错了,有一个同事说编译没有错,是打包出错了。还有一次有个同事编译出错了,让我帮忙看看是怎么回事,我看了之后说编译过程没问题,链接阶段出错了,找不到符号,他一脸疑惑的说,这编译不是出错了吗。还有些同学不明白编译原理中的编译和工作中的编译的不同,会问一些非常有意思的问题,比如有人问过我,预处理的时候为什么不能提前发现语法错误呢,我说预处理的时候还没到编译阶段呢,他说预处理不是编译吗。如果我们知道了编译的四个不同广度的含义就能更好地沟通清楚我们要表达的意思。
二、编译系统的逻辑结构
前面一章我们对编译的概念和编译系统的组成已经有了基本的了解,这一章我们来具体讲讲它们之间的结构关系和每个组成部分的功能作用。
2.1 狭义编译
我们首先来看一下狭义编译:
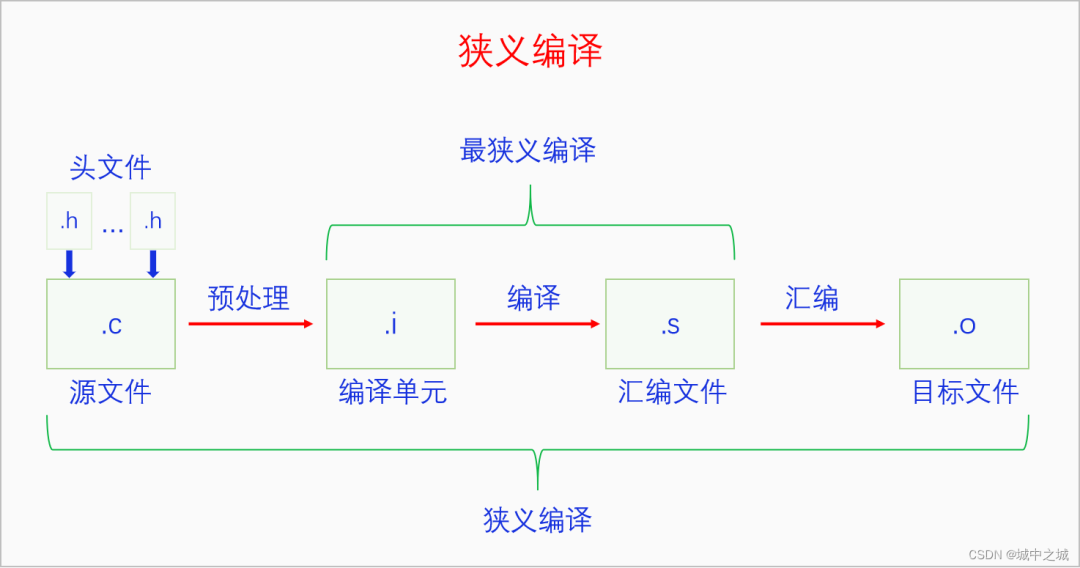
狭义编译是对一个源文件和n个头文件进行的编译,它包含预处理、最狭义编译和汇编三个过程。预处理是对源文件中的预处理指令进行处理的过程,预处理指令包括头文件包含指令(#include)、宏定义指令(#define)、取消宏定义指令(#undef)、条件编译指令(#if #ifdef #ifndef #else #elif #endif)和其他一些编译指令。预处理过程会把所有被包含的头文件插入到源文件中,并对其它预处理指令进行处理,最终生成一个编译单元 .i文件。然后对编译单元进行最狭义的编译,也就是编译原理里面所说的编译。编译原理里面说最狭义编译最后可以生成汇编文件也可以直接生成目标文件没有汇编过程,但是书里一般都是按照直接生成目标文件来讲的,而现实中的编译器一般都是生成汇编文件,最后再经历一个汇编过程。汇编是把汇编文件生成目标文件的过程,目标文件里面包含可直接执行的机器指令,但是整个文件还不是可执行格式。
2.2 最狭义编译
最狭义编译是编译原理中的编译。编译原理是一门非常艰深课程,是计算机科学中最有技术含量的领域之一,是理论和实现都极其难以理解的一门科学。我们这里不准备详细讲解编译原理的知识,只是对其框架进行大概的介绍。我们先看一张图:
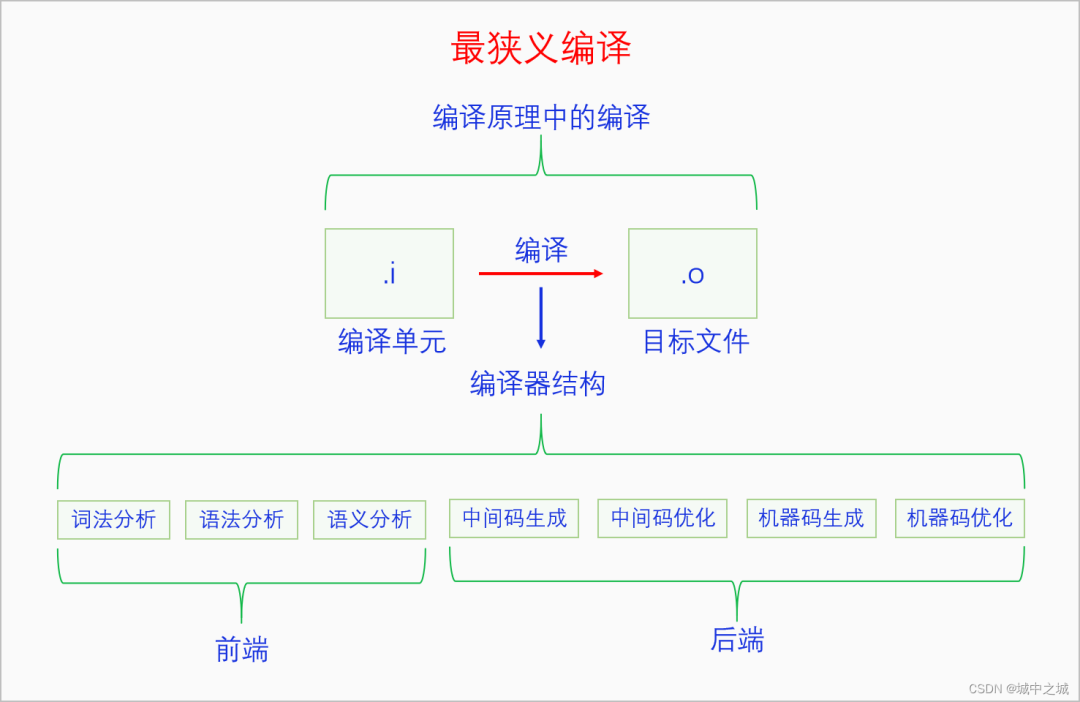
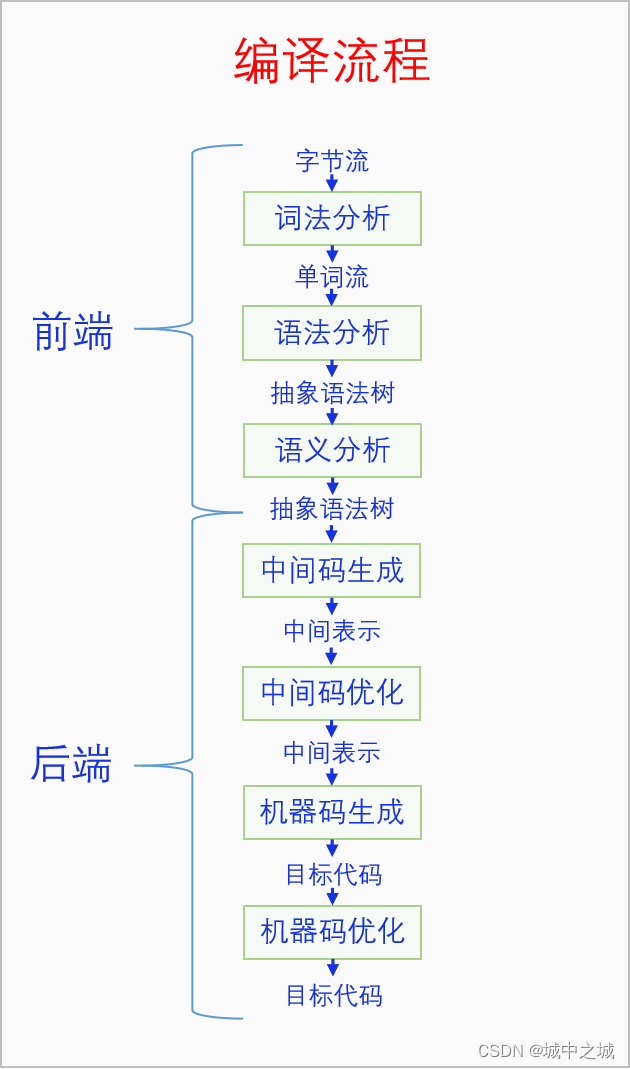
我们按照直接生成目标文件的方式来讲,因为这样整个编译器结构比较完整,如果是生成汇编文件的话,那么机器码生成这块就不存在了。编译器一般都分成前端和后端两个部分,前端负责对语言本身进行解析,后端负责机器码生成。为什么要分成前端和后端两个部分呢,因为前端和后端并不是必然关联的,分开之后可以有更大的灵活性。灵活性主要有两个方面,对于同一种语言来说,语法解析我们只需要实现一次就行了,当语言需要移植到另一个CPU架构时,只需要实现后端就可以了。对于不同的语言来说,对于同一个CPU架构我们没必要实现多个后端,所有的语言都可以共用同一个后端,当编译器需要支持新的语言的时候,只需要实现前端就行了。前端包括词法分析、语法分析(句法分析)、语义分析,后端包括中间码生成、中间码优化、机器码生成、机器码优化,下一章将会对其进行稍微详细的介绍。
2.3 链接过程
经过狭义编译之后我们得到了目标文件,但是目标文件并不是最终的可执行程序,我们需要把目标文件链接起来才能生成可执行程序。程序执行时生成进程,进程是由一个exe主程序和n个so库程序组成,主程序和库程序都是由目标文件和静态库文件通过静态链接生成的。静态链接分为隐式静态链接和显式静态链接,隐式静态链接是目标文件和目标文件直接合并在一起,显式静态链接是目标文件和静态库进行链接,本质上还是和静态库里面的目标文件进行链接。隐式静态链接和显式静态链接区别不大,本质上是没有区别的,只是在编译命令上有形式上的区别。Exe对so,so对so,是动态链接的,动态链接分为半动态链接和完全动态链接,两者的本质是相同的,都是动态链接的,也就是说没有复制文件的过程,但是两者的实现形式还是有很大差异的。半动态链接就是我们平常所说的动态链接,它在编程时需要include so的头文件,在编译时需要指定so所在的路径,链接后生产的文件中会记录这个so的相关信息,在进程启动时加载器会加载这个so,在程序运行时调用了这个so的函数的时候会去动态解析符号。完全动态链接是指在代码中通过函数dlopen加载相应的so,通过函数dlsym查找要调用的函数的符号,然后去调用这个函数,使用完了之后可以通过dlclose卸载这个so。完全动态链接不需要include相应的头文件,编译时也不需要指定so的路径,运行时如果找不到so,dlopen会返回NULL,程序不会崩溃,用完了之后还可以把so卸载了。相反,对于半动态链接,如果编译时找不到so就会编译不过,运行时找不到so程序就会启动失败,程序运行的过程中也不可能把so给卸载移出进程的内存空间。
下面看一下编译时链接的过程:
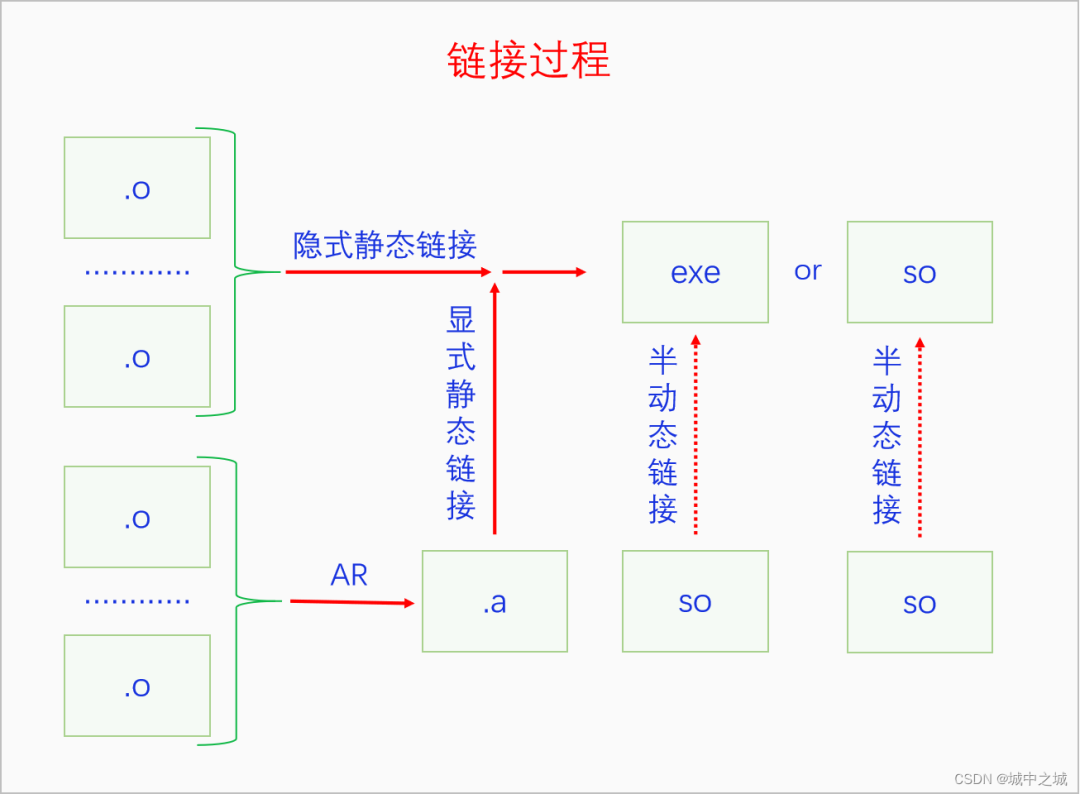
编译时链接,不仅会进行静态链接,也会进行半动态链接的第一步。下面再看一下半动态链接的启动加载和完全动态链接:
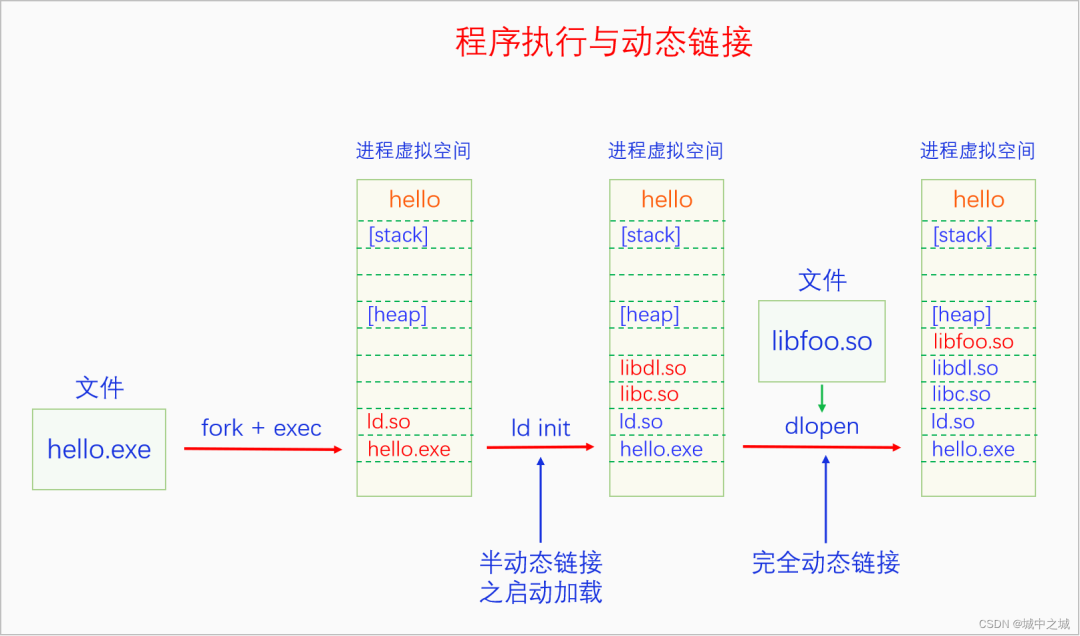
进程启动时首先是fork创建进程的壳,然后exec加载进程的主程序hello.exe和加载器ld.so。然后进程返回用户空间,执行权交给ld,ld会根据主程序文件中的动态段的信息去加载所有的so文件,并完成重定位工作,最后把执行权交给主程序。主程序首先执行的并不是main函数,而是_start函数,_start函数会调用 __libc_start_main函数,此函数会完成进程环境的初始化,最后调用main函数。进入了main函数就是程序执行的主体了,程序如果执行到了dlopen函数,就会去加载相应的so文件。
2.4 组建系统
组建系统英语是build system,也有翻译成构建系统的。什么是组建系统呢,如果你每次编译程序都要执行一大堆gcc ld 命令,那是多么的麻烦,有了组建系统你每次只需要执行一个简单的命令,就能编译整个程序了。下面我们以使用最普遍的组建系统make为例简单地讲一讲。make命令会在同目录下寻找文件Makefile,然后解析并执行它。Makefile的内容包含5个部分,1.变量定义,2.显示规则,3.隐式规则,4.文件指示,5注释。变量定义相当于C语言中的宏,使用时会被替换到相应的位置。显示规则说明了如何生成一个文件,显示规则包含3部分,目标、依赖和命令。由于很多规则模式是很常用的,所以make内置了一些规则,我们没必要把规则写全,make会自动推导。文件指示类似于C语言中的预处理命令,如#include可以包含下层makefile。注释是以#开头的行。
显示规则的格式如下,隐式规则没有命令部分。
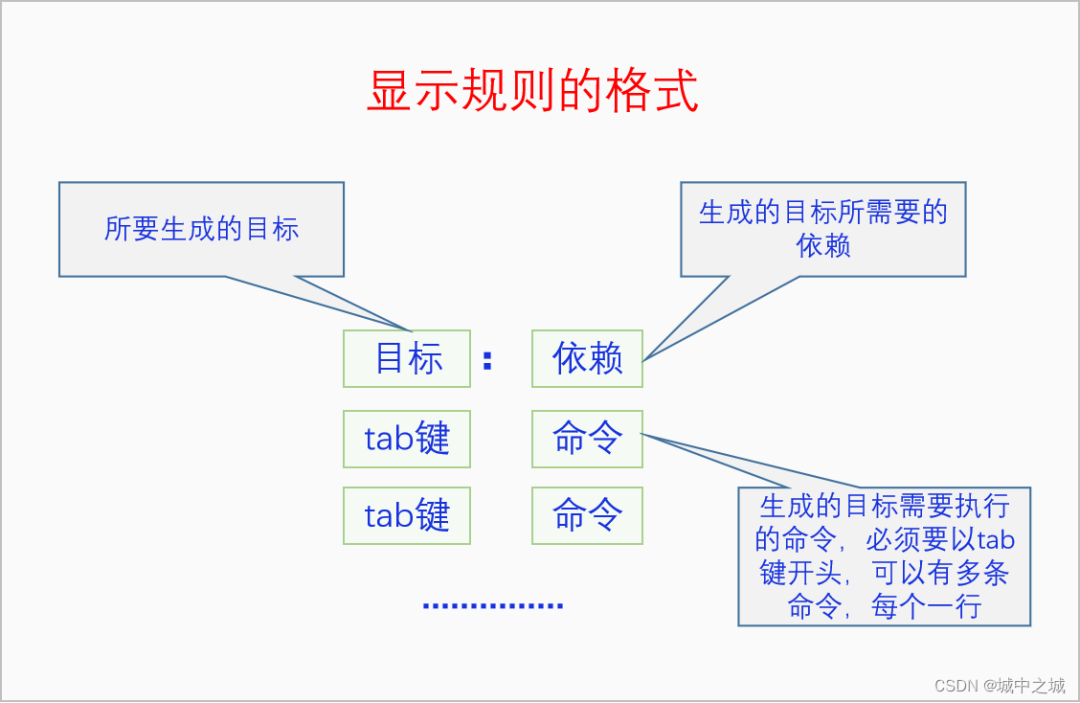
三、编译原理简介
前面我们讲了一下最狭义编译,也就是编译原理中的编译。这里我们把编译原理给大家简单介绍一下,就不展开详细讨论了,因为编译原理实在是太深了,想要深入研究的同学可以去看参考文献里推荐的书籍。我们先来看一下编译的总体过程:
3.1 词法分析
什么是词法分析,为什么要进行词法分析呢?词法分析是把一个一个的字符变成一个一个的单词(Token)。单词,英文是Token,汉语有翻译成记号的,也有翻译成符号的,它是源代码的最小逻辑单位。词法分析的作用就相当于我们小时候的学的如何断句,把一句话分成一个一个的词,词有名词代词动词形容词副词介词连词等,它们再组成了一句话的主谓宾定状补。类似的,词法分析中从源代码字符流中分出一个一个的单词,并对单词进行属性分类,方便后面进一步地分析:句法分析(语法分析),把单词组成句子。词法分析的基本原则也比较简单,主要就是按照空格划分,按照换行划分,但是又不完全如此,又有一些特殊情况。比如 a=b+c,虽然没有一个空格,但是并不能整体上看成一个单词,而是要把它看成是 a、=、b、+、c,五个单词。又比如 s = “hello world”,虽然“hello world”中间有一个空格,但是并不能把它看成是两个单词,而是把它看成是一个单词。
词法分析器分析出来的单词都有哪些类别呢,一共有5种类别,分别是关键字、标识符、常量、操作符、分界符。关键字其实也算是标识符,只不过是特殊的标识符,它是计算机语言标准规定的具有特殊含义的标识符,主要有两类,一类是表示数据类型的,比如int、long、float等,另一类是表达流程的,比如if、while、for。标识符是普通的标识符,是程序员为程序中的实体起的名字,主要分为两类,分别是变量名和函数名。常量就是程序中的字面常量,包括整数型常量、浮点型常量、字符常量、字符串常量、布尔常量等。操作符是用来进行一些运算的符号,如进行算术运算的 + - x / % 等运算符,进行比较操作的 > >= < <= == != 等,进行逻辑运算的 && || !等运算符,还有进行移位运算、赋值操作、条件操作等操作符。分界符是没有啥具体含义用来分割一些逻辑单元的边界的符号,如分号;表达一个语句的结束,大括号{}表达一个代码块或者函数的开始和结束,小括号用来表示表达式、函数参数等的分界。
那么我们该用什么方法进行词法分析呢,比如我们可以使用正则表达式,使用有限状态机,包括不确定性有限状态机(NFA)和确定性有限状态机(DFA),这方面的具体细节可以参看参考文献里的书籍。
我们该怎么得到一个词法分析器呢?有两种方法,一种是手工编写代码,一种是用工具帮你生成。手工编写的好处是自由灵活高效,缺点是麻烦费脑子,工具生成的优点是简单快捷,缺点是不够灵活,没法自定义。目前大部分主流编译器采取的都是手工编写词法分析器。由于词法分析的过程像是扫描,所以词法分析又叫做扫描,词法分析器又叫做扫描器。一个比较著名的词法分析器生成工具是flex。
词法分析把源代码的字节流变成了单词流,并标记了单词的类别,并把标识符的相关信息等放入了符号表,这些都会作为下一步句法分析的输入。
3.2 语法分析
我们有了单词,单词可以组成句子,句子可以构成段落,段落可以组成文章,一篇美妙的文章就这么诞生了。对于简单的文学作品是这样的,对于复杂的文学作品如《红楼梦》《三国演义》,有更高一层的结构,一篇文章只是其中的一回。同样的,一个程序也是类似的结构,简单的程序只有一个c文件,复杂的程序有很多的c文件,一个c文件就是一篇文章,是编译的基本单元。具体来说,预处理之后的c文件才是一个编译单元。从前面的描述我们可以看出来,一个编译单元,它的结构是树状的,它的叶子节点的底层节点是单词。语法分析就是把这些底层节点(单词)一步一步地生成一棵树的过程,这棵树就是抽象语法树(AST)。这颗树的根节点就是编译单元,编译单元的子节点有两类,分别是声明和定义,声明包括变量声明和函数声明,定义包括变量定义和函数定义。变量声明、函数声明和变量定义,都比较简单,都是一句,它们的子节点很快就到了叶子节点(单词)。函数定义比较复杂,首先包括函数签名和函数体,函数体又是由很多语句组成的,语句又有很多的类型。下面我们来画一下编译单元的抽象语法树。
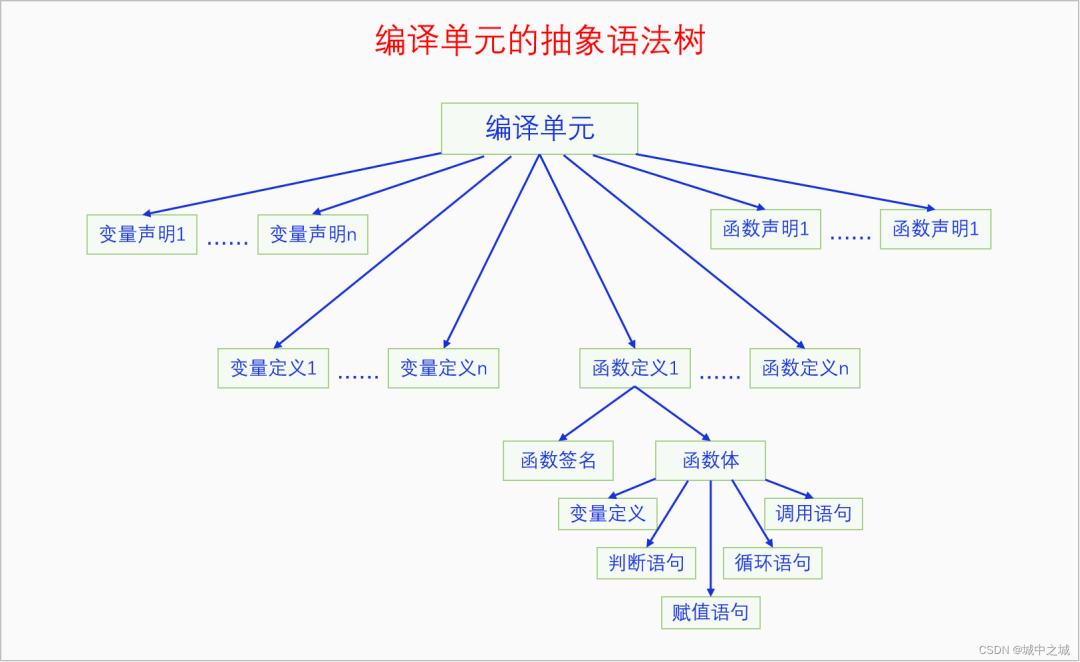
下面我们再来看一个具体的赋值语句 a=b+c; 的抽象语法树。
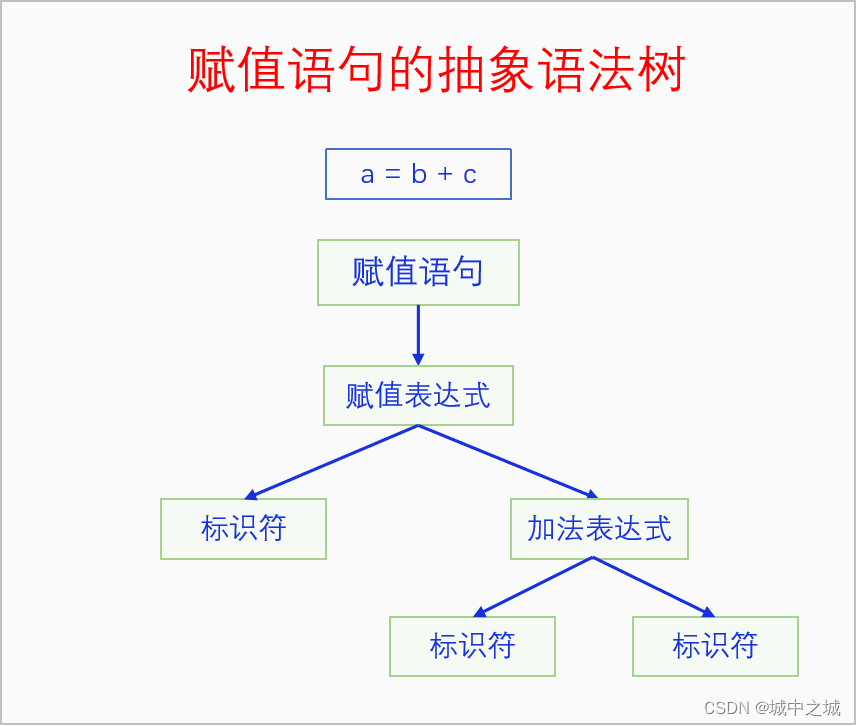
生成一个编译单元的抽象语法树是一个非常复杂的事情,那么该如何生成这个抽象语法树呢?有两类方法,一类是自顶向下方法,包括递归下降算法和LL算法,一个是自底向上方法,包括SR算法和LR算法。具体细节请参看参考文献中的书籍。
3.3 语义分析
经过词法分析和语法分析,我们得到了抽象语法树,但是此时得到的结果只能保证程序是形式上合法的,并不能保证程序在语义上是合理的有意义的。比如给指针赋值浮点数,形式上是个赋值操作,实际上是没有意义的。因此此时要进行语义分析,保证程序在逻辑上是有意义的,没法发现语义不合法的就报错,停止编译。
3.4 中间码生成
现在的编译器都不是直接生成机器代码,而是先生成一种中间语言的代码。这么做是为了,1.使得所有的语言都可以用同一个后端,同一个语言可以轻松添加对新CPU架构的支持,2.所有语言都可以使用同样的机器无关的代码优化方法,避免重复实现优化算法。中间语言一般采取三地址码的形式,每个三地址码都是一个四元组(运算符,操作数1,操作数2,结果),由于每个四元组都包含了三个变量,即每条指令最多有三个操作数,所以被称为三地址码。中间码生成是把抽象语法树转化为中间语言的过程。
3.5 中间码优化
对中间码进行优化,优化的原则是不改成程序本身的执行结果的情况下,减少程序执行的代码量,能提高程序执行的效率。优化的方法有,常量表达式优化,直接把常量表达式的结果计算出来,避免其在运行时再去计算。公共子表达式消除,若两个表达式有相同的子表达式,则只对它们计算一遍,复用计算的结果。复制传播,某些变量的值并未被改变过便赋给其他变量,则可直接引用原值本身。死代码消除,有些代码不会被执行到,把它们删除。无用代码消除,有些代码的执行没有意义,对程序没有作用,把它们删除。代码外提,有些在循环中的代码,在每次循环中的计算结果都是一样的,把它放在循环外只计算一遍就行了。还有很多其他优化方法就不一一列举了,具体情况请参看参考文献中的书籍。
3.6 机器码生成
编译程序的目的是为了把源码翻译成最终能在机器上执行运行的程序,所以编译器最后要把中间码转换为机器码。
3.7 机器码优化
生成目标代码时要考虑优化,生成最高效的代码,有三个因素需要考虑,1.同一个效果可能有多个不同的指令都能实现,选择最优的指令,2.充分利用寄存器,减少访问内存的次数,3.在不影响程序正确性的情况下对指令进行重排序,提高代码的运行效率。
3.8 小型编译器推荐
当我们学习了编译原理之后,非常想通过研究实际的编译器代码来深入理解编译原理。但是目前最流行的两个编译器GCC、LLVM代码都非常庞大,不适合拿来入手。为此我推荐几个市面上比较流行的小型编译器,代码都比较短小简单,大家可以用来研究编译原理。
- c4
一个非常简单的解释型C编译器,整个代码只有一个文件500多行,包含4个函数。可以解释执行一些简单的C程序,更神奇的是可以解释执行自己。源码地址:https://github.com/rswier/c4
- ucc
ucc是曾任小米公司MIUI首席架构师的汪文俊同学在研究生期间花了一年多的时间写的。Ucc 代码简洁易懂,结构清晰,易于学习和掌握。邹昌伟编写的书籍《C编译器剖析》就是以ucc为源代码来解析编译器实现的。源码地址:https://github.com/sheisc/ucc162.3
- chibicc
一个简单而又优雅的小型编译器,实现了大多数 C11 特性,而且能成功编译git、sqlite等源码。源码地址:https://github.com/rui314/chibicc
- tcc
一个小型但是又非常完整的编译器,不仅实现了编译器前端,还实现了汇编器和链接器。源码地址:https://github.com/TinyCC/tinycc
四、静态链接与动态链接
当程序变得越来越庞大之后,我们就会对程序进行模块划分。最先使用的模块方式是文件,把程序放到不同的源代码中,最后编译链接成一个可执行文件。当程序变得更庞大了之后,我们会把程序划分为好几个执行体,每个执行体实现一个单独的功能逻辑。执行体分为主执行体,也就是exe可执行程序,和库执行体,也就是so动态共享库。主执行体有且只有一个,库执行体有n个,n 大于等于 0。执行体一般对应一个源码文件夹,源码文件夹还可以有多个层级。我们对每个源码文件进行编译,得到一个目标文件,执行体都是由若干个目标文件静态链接而生成的。目标文件、主执行体、库执行体,它们都要有一定的格式。不同的操作系统可以采用不同的格式,Windows用的是PE格式,UNIX(包括Linux)用的是ELF格式。ELF是一个总体格式,对上,目标文件、主执行体、库执行体又有不同的子类型格式,对下,在不同的硬件平台上它们又有具体的格式。大家经常把静态库和动态库放在一起来对比,导致人们习惯性认为它俩是非常对称的。实际上它俩只是稍微有一些对称性,它们的不对称性还是很大的。静态库和动态库最大的区别就是,静态库会被复制进被链接的程序中,而动态库不会。也就是这一点区别导致了它们本质性的区别,动态库是执行体,而静态库不是,静态库是组成执行体的原料。
头文件的目的和意义:当整个程序只有一个源文件的时候,是没有头文件的。当程序被放到多个源文件的时候,由于每个源文件都是单独编译的,编译的时候并不知道其他源文件的信息,所以需要头文件来提供其他源文件的信息。头文件里面主要放的是变量声明、函数声明、数据类型声明。头文件里面尽量只放声明性的东西,不要放定义性东西。声明和定义的区别是,声明性的东西不分配内存空间,定义性的东西分配内存空间。如果在头文件里面放定义性的东西的话,由于头文件会被包含到很多源文件中,所以会导致这个定义会有很多份,这在大多数情况下都不是想要的情况。有一种情况可以在头文件中放定义,那就是有些比较短小的又想要内联的函数可以放在头文件中。
4.1 静态链接
我们经常把链接到静态库叫静态链接,其实目标文件的合并也是静态链接。它俩形式上虽然不太相同,但是本质上是一样的。静态库仅仅是对目标文件的打包而已,链接到静态库实际上还是目标文件的合并。为了区分两者,我们把前者叫做显式静态链接,后者叫做隐式静态链接。如果我们的程序有两个源文件组成,那么最终生成程序的时候就是两个目标文件的合并,也就是隐式静态链接。而我们链接到静态库的显示静态链接,和这个隐式静态链接没有区别。明白了这件事,我们就容易想明白一个问题,那就是我们的程序如果依赖于一个静态库,那么这个静态库的依赖,我们需要在本程序里要再声明一次。因为静态库在这个意义上和你自己的某个C文件没有区别,相当于是你自己对外部的依赖。这点和动态库就有很大的不同,你依赖于动态库,并不需要知道动态库依赖于谁。
显式静态链接的编译命令和动态链接的命令是一样的,和隐式静态链接不一样,但是在处理逻辑上正好反了过来。
4.2 动态链接
动态链接也分为两种,我们经常说的动态链接叫半动态链接,通过dlopen进行的链接叫做完全动态链接。因为dlopen确实是完全动态的,只有dlopen代码执行到了才会进行链接,执行不到根本就不会链接。而半动态链接,你在编译时就要在命令参数中指明要链接的动态库,链接后动态库的信息会被放到被链接的执行体的动态段里面。程序启动的时候加载器还会把一个程序所依赖的所有动态库都加载到进程的地址空间,并做好重定位。你对动态库中的函数的调用,直到你第一次调用时才会进行函数地址解析。完全动态链接,dlopen的时候加载动态库,dlsym的时候进行函数地址解析,dlclose还能把动态库给移出进程的地址空间。
半动态链接和完全动态链接所使用的动态库格式是一样的,没有啥区别,不同的是使用它们的方式。
4.3 实例解析
下面我们写一个hello程序来演示一下隐式静态链接、显示静态链接、半动态链接、完全动态链接,它们的区别和用法。所有的文件截图如下:
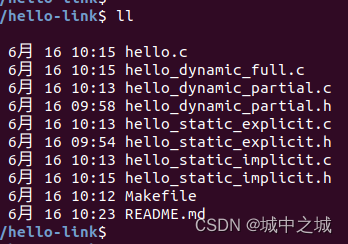
hello.c
#include
hello_static_implicit.c
#include
其他几个文件是类似的,就不再贴出代码了。
Makefile
# This is hello link program
CFLAGS += -std=c99 -g -Wall
all : hello libhello_dynamic_full.so
hello : hello.o hello_static_implicit.o libhello_static_explicit.a libhello_dynamic_partial.so
gcc -o hello hello.o hello_static_implicit.o -Wl,-rpath=. -L. -lhello_static_explicit -lhello_dynamic_partial
hello.o : hello.c hello_static_implicit.h hello_static_explicit.h hello_dynamic_partial.h
gcc -o hello.o -c hello.c
hello_static_implicit.o : hello_static_implicit.c hello_static_implicit.h
gcc -o hello_static_implicit.o -c hello_static_implicit.c
hello_static_explicit.o : hello_static_explicit.c hello_static_explicit.h
gcc -o hello_static_explicit.o -c hello_static_explicit.c
libhello_static_explicit.a : hello_static_explicit.o
ar rv libhello_static_explicit.a hello_static_explicit.o
libhello_dynamic_partial.so : hello_dynamic_partial.c hello_dynamic_partial.h
gcc -o libhello_dynamic_partial.so -shared hello_dynamic_partial.c
libhello_dynamic_full.so : hello_dynamic_full.c
gcc -o libhello_dynamic_full.so -shared hello_dynamic_full.c
.PHONY :
clean:
rm -f hello *.o *.a *.so
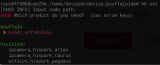
从Makefile中可以看出他们的链接关系。下面是程序运行的结果:
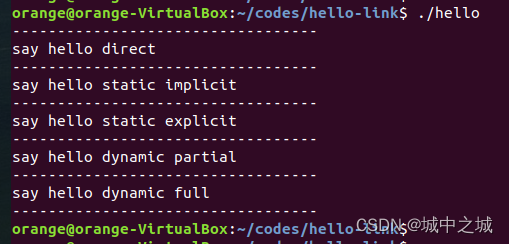
可以看出hello程序可以直接调用本文件内的函数,也可以调用隐式静态链接中的函数,也可以调用显示静态链接也就是链接到静态库的函数,也可以调用半动态链接中的so的函数,也可以通过dlopen、dlsym进行完全动态链接。前三者在调用方式上没有区别,都是先声明后调用,最后一个不需要声明函数,但是需要手动解析函数的地址,并赋值给函数指针才能调用。
我把演示代码放到GitHub上了,大家可以参考一下 https://github.com/orangeboyye/hello-link
五、总结回顾
本文中,我们先回顾了编译系统的发展历史,理解了编译系统各个组成部分的原理和相互之间的关系,然后又介绍了各个模块内部的知识。都是一些简单的概念性的介绍,想要深入学习的同学可以去研究参考文献中的书籍。
审核编辑:汤梓红











 工商网监
工商网监
评论