 电子发烧友App
电子发烧友App


大家好,这里是浩道linux,主要给大家分享linux、python、网络通信相关的IT知识平台。
今天给大家分享日常工作中常用到的shell文本处理工具,可以说是史上最全了,大家掌握住这些工具,可以在日常运维工作中起到事半功倍的作用!
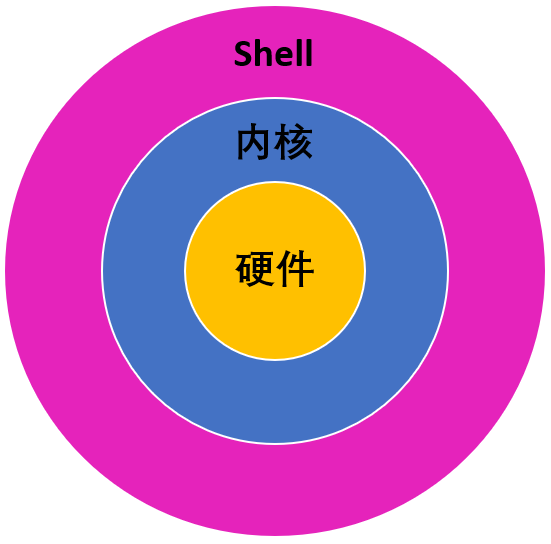
本文将介绍Linux下使用Shell处理文本时最常用的工具:
01 find 文件查找
1 查找txt和pdf文件
-
find . ( -name "*.txt"-o -name "*.pdf") -print
-
find . -regex ".*(.txt|.pdf)$"
-
find . ! -name "*.txt"-print
-
find . -maxdepth 1-type f
-
find . -type d -print //只列出所有目录 -
-type f 文件 / l 符号链接
-
-atime 访问时间 (单位是天,分钟单位则是-amin,以下类似) -
-
-mtime 修改时间 (内容被修改) -
-
-ctime 变化时间 (元数据或权限变化)
-
find . -atime 7-type f -print
-
find . -type f -size +2k
-
find . -type f -perm 644-print //找具有可执行权限的所有文件
-
find . -type f -user weber -print// 找用户weber所拥有的文件
-
find . -type f -name "*.swp"-delete
-
find . -type f -user root -exec chown weber {} ; //将当前目录下的所有权变更为weber
-
find . -type f -mtime +10-name "*.txt"-exec cp {} OLD ;
-
-exec ./commands.sh {} ;
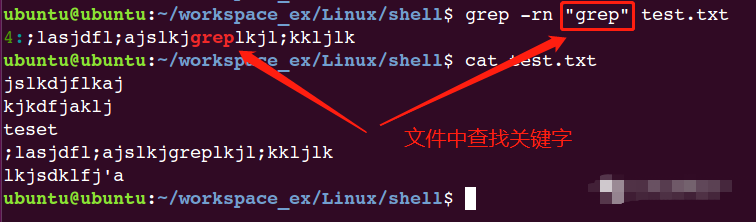
02 grep 文本搜索
-
grep match_patten file // 默认访问匹配行
-
-o 只输出匹配的文本行 VS -v 只输出没有匹配的文本行
-
-c 统计文件中包含文本的次数
-
grep -c "text" filename
-
-n 打印匹配的行号
-
-i 搜索时忽略大小写
-
-l 只打印文件名
-
grep "class". -R -n
-
grep -e "class"-e "vitural" file
-
grep "test" file* -lZ| xargs -0 rm
-
cat file.txt| xargs
-
cat single.txt | xargs -n 3
-
-d 定义定界符 (默认为空格 多行的定界符为 )
-
-n 指定输出为多行
-
-I {} 指定替换字符串,这个字符串在xargs扩展时会被替换掉,用于待执行的命令需要多个参数时
-
cat file.txt | xargs -I {} ./command.sh -p {} -1
-
find source_dir/ -type f -name "*.cpp"-print0 |xargs -0 wc -l
03 sort 排序
字段说明:-
-n 按数字进行排序 VS -d 按字典序进行排序
-
-r 逆序排序
-
-k N 指定按第N列排序
-
sort -nrk 1 data.txt -
sort -bd data // 忽略像空格之类的前导空白字符
04 uniq 消除重复行
消除重复行-
sort unsort.txt | uniq
-
sort unsort.txt | uniq -c
-
sort unsort.txt | uniq -d
05 用 tr 进行转换
通用用法-
echo 12345| tr '0-9''9876543210'//加解密转换,替换对应字符 -
cat text| tr ' '' '//制表符转空格
-
cat file | tr -d '0-9'// 删除所有数字
-
cat file | tr -c '0-9'//获取文件中所有数字 -
cat file | tr -d -c '0-9 '//删除非数字数据
-
cat file | tr -s ' '
-
alnum:字母和数字
-
alpha:字母
-
digit:数字
-
space:空白字符
-
lower:小写
-
upper:大写
-
cntrl:控制(非可打印)字符
-
eg: tr '[]''[]'
06 cut 按列切分文本
截取文件的第2列和第4列:-
cut -f2,4 filename
-
cut -f3 --complement filename
-
cat -f2 -d";" filename
-
N- 第N个字段到结尾
-
-M 第1个字段为M
-
N-M N到M个字段
-
-b 以字节为单位
-
-c 以字符为单位
-
-f 以字段为单位(使用定界符)
-
cut -c1-5 file //打印第一到5个字符 -
cut -c-2 file //打印前2个字符
07 paste 按列拼接文本
将两个文本按列拼接到一起;-
cat file1 -
-
1 -
2 -
-
cat file2 -
-
colin -
book -
-
paste file1 file2 -
-
1 colin -
2 book
-
paste file1 file2 -d "," -
-
1,colin -
2,book
08 wc 统计行和字符的工具
-
wc -l file // 统计行数 -
wc -w file // 统计单词数 -
wc -c file // 统计字符数
09 sed 文本替换利器
首处替换-
seg 's/text/replace_text/' file //替换每一行的第一处匹配的text
-
seg 's/text/replace_text/g' file
-
seg -i 's/text/repalce_text/g' file
-
sed '/^$/d' file
-
echo this is en example | seg 's/w+/[&]/g' -
-
$>[this] [is] [en] [example]
-
sed 's/hello([0-9])//'
-
sed 's/$var/HLLOE/'
-
eg: -
p=patten -
r=replaced -
echo "line con a patten"| sed "s/$p/$r/g" -
$>line con a replaced
-
sed 's/^.{3}/&//g' file
10 awk 数据流处理工具
awk脚本结构-
awk ' BEGIN{ statements } statements2 END{ statements } '
-
echo -e "line1 line2"| awk 'BEGIN{print "start"} {print } END{ print "End" }'
-
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; -
print var1, var2 , var3; }' -
$>v1 V2 v3
-
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; -
print var1"-"var2"-"var3; }' -
$>v1-V2-v3
NR NF $0 $1 $2
-
NR:表示记录数量,在执行过程中对应当前行号;
-
NF:表示字段数量,在执行过程总对应当前行的字段数;
-
$0:这个变量包含执行过程中当前行的文本内容;
-
$1:第一个字段的文本内容;
-
$2:第二个字段的文本内容;
-
-
echo -e "line1 f2 f3 line2 line 3"| awk '{print NR":"$0"-"$1"-"$2}'
-
awk '{print $2, $3}' file
-
awk ' END {print NR}' file
-
echo -e "1 2 3 4 "| awk 'BEGIN{num = 0 ; -
print "begin";} {sum += $1;} END {print "=="; print sum }'
-
var=1000 -
echo | awk '{print vara}' vara=$var # 输入来自stdin -
awk '{print vara}' vara=$var file # 输入来自文件
-
awk 'NR < 5'#行号小于5 -
awk 'NR==1,NR==4 {print}' file #行号等于1和4的打印出来 -
awk '/linux/'#包含linux文本的行(可以用正则表达式来指定,超级强大) -
awk '!/linux/'#不包含linux文本的行
-
awk -F: '{print $NF}'/etc/passwd
-
echo | awk '{"grep root /etc/passwd" | getline cmdout; print cmdout }'
-
for(i=0;i<10;i++){print $i;} -
for(i in array){print array[i];}
-
seq 9| -
-
awk '{lifo[NR] = $0; lno=NR} -
-
END{ for(;lno>-1;lno--){print lifo[lno];} -
-
} '
-
head: -
awk 'NR<=10{print}' filename
-
tail: -
awk '{buffer[NR%10] = $0;} END{for(i=0;i<11;i++){ -
print buffer[i %10]} } ' filename
-
ls -lrt | awk '{print $6}'
-
ls -lrt | cut -f6
-
seq 100| awk 'NR==4,NR==6{print}'
-
awk '/start_pattern/, /end_pattern/' filename
-
eg: -
seq 100| awk '/13/,/15/' -
cat /etc/passwd| awk '/mai.*mail/,/news.*news/'
-
index(string,search_string):返回search_string在string中出现的位置 -
sub(regex,replacement_str,string):将正则匹配到的第一处内容替换为replacement_str; -
match(regex,string):检查正则表达式是否能够匹配字符串; -
length(string):返回字符串长度
-
echo | awk '{"grep root /etc/passwd" | getline cmdout; print length(cmdout) }'
-
seq 10| awk '{printf "->%4s ", $1}'
-
while read line; -
do -
echo $line; -
done< file.txt
-
cat file.txt | (while read line;do echo $line;done)
-
cat file.txt| awk '{print}'
-
for word in $line; -
do -
echo $word; -
done
-
for((i=0;i<${#word};i++)) -
do -
echo ${word1); -
done
















 工商网监
工商网监
评论