缓存又叫高速缓存,是计算机存储器中的一种,本质上和硬盘是一样的,都是用来存储数据和指令的 。
2022-07-23 09:05:37 3846
3846 CPU的核心功能包括数据运算和指令控制。CPU运算的数据和执行的指令全部存储在CPU的寄存器中,这些数据和指令又都来自于CPU高速缓存。
2024-01-02 16:01:48663 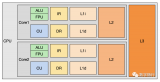
在网上无意中看到了一篇博文,还是今年的,就简单了解下,挺有意思,给大家分享下。模拟计算机是根据相似原理,用一种连续变化的模拟量作为被运算对象的计算机。模拟计算机以电子线路构成基本运算部件。由运算部件、控制部件、排题板、输入输出设备等组成。各种片段: 系统分析: ...
2021-08-18 07:44:00
其实我感觉计算机编程有两个坎(我就经历这么多):一个是入门,另一个是应用。 对于新手,那些语句仿佛是一大堆无意义的字母,看上去乱七八糟的。其实计算机编程语言学习刚开始就像是学英语(我这么感觉),先
2021-07-15 06:09:39
怎样去学习计算机编程?计算机编程有哪些应用?
2021-09-24 07:50:41
、计算机可分为数字计算机、模拟计算机和混合计算机,这种分类是依据______。A:功能和用途B:性能和规律C:处理数据的方式D:使用范围答案: C3、计算机具有逻辑判断能力,主要取决于____。A:硬件B:...
2021-09-13 06:23:03
计算机一级考试模拟题一、单选题1、第一台电子数字计算机的运算速度为每秒______。A:500000次B:50000次C:5000次D:500次答案:C2、计算机可分为数字计算机、模拟计算机和混合计算机
2021-09-13 07:41:04
单片机复习选择题组成原理中计算机分为哪些功能部件A、运算器B、控制器C、存储器D、输入设备E、输出设备答案: ABCDE计算机的存储器分为:A、U盘B、内存C、外存D、高速缓存E、寄存器答案
2021-07-26 07:46:34
XX计算机应用基础模拟题「附答案」 (14页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦!14.9 积分XX计算机应用基础模拟题「附答案」 一
2021-09-10 06:58:01
本文分别介绍了存储器的分类、组成、层次结构、常见存储器及存储器的选择,最后描述了计算机存储器的一些新技术。存储器是计算机系统中的记忆设备,用来存放程序和数据。计算机中全部信息,包括输入的原始数据
2021-09-09 07:47:39
组成的比例器控制,通过继电器带动减速电机运转。这里使用的是一片八路反相驱动芯片74HC240作为模拟计算机的核心。读者也可以使用通用运算放大器接成反相器来替代,控制效果是一样的。以下是小车运行状态的分析...
2021-09-01 07:03:34
、模拟计算机和混合计算机,这种分类是依据______。A:功能和用途B:性能和规律C:处理数据的方式D:使用范围答案: C3、计算机具有逻辑判断能力,主要取决于____。A:硬件B:体积C:编制的软件D:基...
2021-09-13 06:11:56
计算机组成与嵌入式系统笔记第1章计算机的基本结构1.计算机组成(1)程序是执行任务的指令序列。程序存储在存储器中。处理器从存储器中一条接一条地取出程序指令,然后完成所需要的操作。(2)存储器的功能
2021-12-22 06:02:58
一•计算机概述计算机(computer)俗称电脑,是现代一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能。是能够按照程序运行,自动、高速处理海量数据的现代化
2021-09-16 07:38:58
在第二代计算机期间内提出一个重要的系统软件的概念是文件管理系统网络管理系统数据库系统操作系统既可以接入处理和输出模拟量也可以接收处理和输出数字量的计算机是电子数字计算机电子模拟计算机数模混合计算机
2021-09-13 07:22:33
输入输出设备第九章 操作系统支持第一章 计算机系统概述电子计算机分两类:电子模拟计算机、电子数字计算机五代变化:电子管计算机、...
2021-07-21 07:25:16
计算机组成原理简答题及答案,一.简答题1.什么是计算机系统、计算机硬件和计算机软件?硬件和软件哪个更重要?计算机系统:由计算机硬件系统和软件系统组成的中和体;计算机硬件:指计算机中的电子线路和物理
2021-07-22 06:53:19
计算机题库1(152).下列关于字节的四条叙述中,正确的一条是(C).A) 字节通常用英文单词"bit"来表示,有时也可以写作"b"B) 目前广泛
2021-07-28 08:40:33
计算机中丢失OpenNI2.dll在使用PCL点云库时,直接用pcl_mesh_sampling.exe或是pcl_mesh_samplingd.exe文件生成点云.pcd文件时会报错“:无法启动此
2021-07-01 11:39:15
分享一下计算机中丢失dll文件修复方法。第一种方法:1、在命令提示符下输入第一个命令:cd/d %systemroot%system322、在命令提示符下继续输入第二个命令:For %i
2018-11-28 17:06:50
计算机中的存储器有何用途呢?半导体存储器可分为哪几类呢?
2022-01-21 06:12:54
电磁兼容的英文名称为Electromagnetic Compatibility ,简称EMC。电磁兼容技术涉及的频率范围宽达0-400GHz,研究对象除传统设施外,涉及芯片级,直到各型舰船、航天飞机、洲际导弹,甚至整个地球的电磁环境。本文章主要介绍计算机中的电磁兼容情况。
2019-05-31 08:22:48
存储器系统的层次架构是如何构成的?高速缓存(cache)的工作原理是什么?高速缓存可分为哪几类?
2021-12-23 06:18:10
子系统的性能要求和设计方案的基础上,提出了高速缓存和海量缓存方案,并将该方案成功地应用于DSP多通道超声信号采集与处理系统中。 对高速多通道采样数据存储的性能要求:一是高速性,现在高速数据采集
2020-12-04 15:59:14
什么是高速缓存?• 高速存储器块,包含地址信息(通常称作TAG)和相关联的数据。• 目的是提高对存储器的平均访问速度• 高速缓存的应用基于下面两个程序的局部性 :• 空间局部性:如果一个存储器的位置
2023-09-07 08:22:51
提示。对于G.5.9.1中的单处理器系统,只有一个示例,没有数据高速缓存刷新操作。因此,在单处理器系统中,用于编写转换表条目的示例指令序列包括以下内容:STR rx,[翻译表条目];将新条目写入转换表
2022-08-16 15:20:22
在打开VI时提示“LabVIEW 无法启动此程序,因为计算机中丢失FTD2XX.dll。尝试重新安装该程序以解决”该怎么解决,跪求高人指点
2014-11-24 22:24:37
磁阻式随机存储器(MRAM)是一种新型存储器,其优点有读取速度快和集成度高及非挥发性等。目前许多研究主要是致力于将MRAM存储器运用于计算机存储系统中。MRAM因具有许多优点,有取代SRAM
2020-11-06 14:17:54
与传统操作系统不同,djyos不是以线程而是以事件为调度核心,这种调度算法使程序员摆脱模拟计算机执行过程编写程序的思维方式,而是按人类认知世界的方式编写应用程序,就如同在嵌入式编程中引入了VC似的。
2019-09-17 17:00:40
linux 高速缓存DNS
2019-08-12 12:06:20
)。通过逻辑门来执行操作二进制数据,逻辑门是一种基本电路,它可以将一个或多个输入转换为输出。逻辑门包括与门、或门、非门等等,将许许多多逻辑门组合起来就可以构建复杂的电路来执行各种操作,电子计算机中
2024-03-13 17:19:18
我们知道DSP芯片处理数字信号速度快,精度高,那为什么计算机不用DSP而是用CPU/GPU呢?或者说计算机有哪个模块是使用了DSP的吗?那么计算机中有硬件乘法器吗?
2018-05-20 16:51:52
第一章 计算机系统概论1. 什么是计算机系统、计算机硬件和计算机软件?硬件和软件哪个更重要?解:P3计算机系统:由计算机硬件系统和软件系统组成的综合体。计算机硬件:指计算机中的电子线路和物理装置
2021-07-22 09:06:57
第一章计算机系统概论1 .什么是计算机系统、计算机硬件和计算机软件?硬件和软件哪个更重要?解: P3计算机系统:由计算机硬件系统和软件系统组成的综合体。计算机硬件:指计算机中的电子线路和物理装置。计算机软件:计算机运行所需的程序及相关资料。...
2021-07-26 07:18:43
、第一台电子数字计算机的运算速度为每秒______。A:次B:50000次C:5000次D:500次答案: C2、计算机可分为数字计算机、模拟计算机和混合计算机,这种分类是依据______。A:功能和用途B:...
2021-09-13 06:07:37
一、单选题1、第一台电子数字计算机的运算速度为每秒______。A:500000次B:50000次C:5000次D:500次答案: C2、计算机可分为数字计算机、模拟计算机和混合计算机,这种分类
2021-09-13 08:00:03
` 口袋编程计算机(PocketProgrammingComputer)致力于降低青少年学习编程门槛,提高青少年硬件动手能力。 01前言 从计算机出现以来,伴随着发展最快的是编程,程序员也变成
2017-08-04 17:52:58
应用基础1一、单选题1、 第一台电子数字计算机的运算速度为每秒 。A:500000 次B:50000 次C:5000 次D:500 次答案:C,这种分类是依据2、计算机可分为数字计算机、模拟计算机和混合计算机...
2021-09-13 07:57:01
Hz(赫兹)通常的定义是波形每秒钟变化或振动的次数,在计算机中不同硬件对Hz的定义各不相同。CPU:Hz用来表示时钟频率。目前的CPU通常以MHz和GHz作为计量单位。显示器:在显示器中有三个频率
2021-09-08 06:10:00
以及应用前景四方面探究了它在计算机中的有效应用,针对应用内容进行了详细探讨。关键词:嵌入式实时软件计算机引言新时代,计算机普及应用于各个领域,同时成为了人们日常生活不可或缺的重要工具。鉴于社会对计算机较高...
2021-11-09 07:05:34
网时,尽量减少可执行代码交换,能脱网工作时尽量脱网工作。 病毒的检测与消除1.病毒的检测病毒潜伏在计算机中,不被激发,是很难得被发现的,因此要仔细观察系统的异常现象。一般计算机出现异常,首先判断是否
2009-03-10 12:08:30
Analog-Digital Converter)来讲模拟信号转换为数字信号,这样才能存储到计算机中。那么ADC是如何转换的呢?l首先对选定一个瞬间对模拟信号进行采样;l然后将值转换为数字量;l最后按照一定编码格式转换。—>一个模拟信号肯定是不能采样一个点的,而是许多点集合而成。当长
2021-07-13 06:19:17
第四章微型计算机的存储设备4.1 内存内存是计算机中数据存储和交换的设备。在整个计算机中内存起着调节CPU和外部存储器之间速度差异过大的作用。内存包括Cache(高速缓冲存储器)、ROM(只读存储器
2021-09-10 09:02:31
第7部分 计算机硬件 单选(1) .[B]计算机向使用者传送计算、处理结果的设备称为______。(A) 输入设备(B) 输出设备(C) 存储设备(D) 微处理器(2) .[C]目前微型计算机中采用
2021-09-15 07:43:10
结合高速嵌入式数据采集系统,提出一种基于CvcloneⅢ FPGA实现的异步FIFO和锁相环(PLL)结构来实现高速缓存,该结构可成倍提高数据流通速率,增加数据采集系统的实时性。采用FPGA设计高速缓存,能针对外部硬件系统的改变,通过修改片内程序以应用于不同的硬件环境。
2021-04-30 06:19:52
构成高速缓存的方案有哪几种?如何去实现一种海量缓存的设计?怎样去实现一种基于DSP和ADC技术高速缓存和海量缓存?
2021-06-26 07:50:30
1、功能描述设计一个简易计算器,模拟常见计算器的加减乘除运算功能,通过1602液晶屏来显示数字、4*4的矩阵按键来模拟计算机的按键,2、PROTEUS中设计的电路图3、源代码#include #include #include #define u8unsigned...
2021-11-09 07:37:30
我的系统是win7 64位的,装了cadence 16.3前几天都能正常使用,今早一开机打开capture CIS时说无法启动此程序,因为计算机中丢失cdsCommon.dll。各位大虾们有没有遇到这种情况,如何解决?感激不尽,我已经重装过好多次了,真悲剧
2011-05-23 10:01:36
指令和数据是什么?在计算机中有什么作用?以及它们怎样存储?如何区分指令和数据?
2021-10-25 07:03:29
摘要:《数据结构》课程是计算机专业中的一门专业基础必修课,该课程主要介绍和研究数据在计算机中的存储和处理方法,旨在培养学生分析数据、组织数据的能力,告诉学生如何编写效率高、结构好的程序。它是介于数学
2021-07-19 06:49:24
文章目录前言微控制器系统(MSS)高性能FPGA可编程模拟前端(AFE)模拟计算引擎(ACE)特点简介设计流程器件选型前言Actel SmartFusion®系列智能型混合信号 FPGA 采用
2021-07-22 09:50:25
Compacc 是基于PICMG 标准的工业用嵌入式计算机总线标准。苏州惠普联电子有限公司的CompactPCI 产品群是基于CPCI标准的嵌入式计算机的产品系列,它的商业化应用及发展取决于国际插件式计算机,设备及其他硬件软件的广泛应用。
2022-04-22 09:47:55
高速缓存是提高计算机性能的一种关键技术。文章主要分析了高速缓存所在的计算机存储系统结构、磁盘高速缓存工作原理,深入讨论高速缓存管理器与其它的内核组件相互配合
2009-06-03 09:31:00 10
10 摘要:主要介绍了计算机联锁培训系统平台的研制开发。系统依靠计算机技术、控制技术、网络技术,完全模拟计算机联锁设备的显示界面与操作方法,做到与现实设备操作一致,
2010-05-28 09:57:0615 摘要:介绍在星载计算机中应用实时操作系统的两种方式:使用一种源码开放的RTOS——RTEMS和自主开发RTOS,并对两种方法进行比较。随着我
2006-03-11 12:20:581231 
GPRS及其在可穿戴计算机中的应用
介绍将GPRS技术应用于可穿戴计算机中,使其具有 更强操作性、灵活性的设计情况。文章重点介绍了GPRS技术,GPRS模
2009-10-15 21:40:53590 
C64x+ DSP高速缓存一致性分析与维护
高速缓存(CACHE)作为内核和低速存储器之间的桥梁,基于代码和数据的时间和空间相关性,以块为单位由硬件控制器自动加载内核所需
2010-01-04 12:00:281267 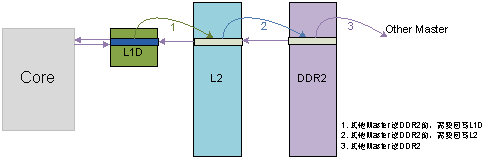
磁盘阵列的高速缓存
2010-01-09 09:59:192571 外置及共享硬盘的高速缓存 缓存(Cache memory)是硬盘控制器上的一块内存芯片,具有极快的存取速度
2010-01-09 14:10:161772 高速缓存(Cache),高速缓存(Cache)原理是什么?
高速缓存Cache是位于CPU和主存储器之间规模较小、存取速度快捷的静态存储器。Cache一般由
2010-03-26 10:49:276717 数据格式,计算机中数据格式详细介绍 计算机中常用的数据表示格式有两种,一是定点格式,二是浮点格式。一般来说,定点格式容许的数值范围
2010-04-13 11:36:003196 【LabVIEW从入门到精通】4.1.5 个人计算机中的串行端口
2016-01-08 15:43:210 基于BCH算法的高速缓存纠检错方案研究
2017-01-07 20:32:200 量子计算机是一类遵循量子力学规律进行高速数学和逻辑运算、存储及处理量子信息的物理装置。当某个装置处理和计算的是量子信息,运行的是量子算法时,它就是量子计算机。量子计算机的概念源于对可逆计算机的研究。研究可逆计算机的目的是为了解决计算机中的能耗问题。
2017-11-28 18:10:3311423 字符编码是计算机编程中不可回避的问题,不管你用 Python2 还是 Python3,亦或是 C++, Java 等,我都觉得非常有必要厘清计算机中的字符编码概念。
2018-01-16 09:08:406966 
本文档提供了PIC32MZ器件系列中一级(Level 1,L1) CPU高速缓存实现的相关信息,并介绍了高速缓存系统的相关风险。此外还提供了解决这些风险的方法。对于高级用户,还针对MPLAB@
2018-03-26 10:39:212 本节介绍 PIC32MX 器件系列中的预取高速缓存模块的功能和工作方式。预取高速缓存功能可以 提高大多数应用程序的系统性能。
2018-06-22 05:20:002 STM32F7技术培训2-高速缓存
2018-07-02 01:29:583207 电子计算机从总体上来说可分为两大类。一类是电子模拟计算机。“模拟”就是相似的意思,例如计算尺是用长度来标示数值;时钟是用指针在表盘上转动来表示时间;电表是用角度来反映电量大小,这些都是模拟计算装置, 模拟计算机的特点是数值由连续量来表示,运算过程也是连续的。
2018-09-27 17:32:17126 工作原理不同。模拟电子计算机中使用的电信号本质上模拟实际信号。所有的处理过程都需要模拟电路来实现。
2019-12-23 14:49:418523 模拟电子计算机中使用的电信号本质上模拟实际信号。所有的处理过程都需要模拟电路来实现。
2020-02-07 20:14:232981 在当今电子技术行业发展过程中,对高速电路数字设计十分关注,高速数字电路是利用多个电子元件组成的,可以让计算机高速数字电路技术进一步提高,因此在计算机中使用高速数字电路设计技术也就更加普遍。
2020-08-21 17:41:102924 磁阻式随机存储器MRAM是一种新型存储器,其优点有读取速度快和集成度高及非挥发性等。目前许多研究主要是致力于将MRAM运用于计算机存储系统中。同时非易失性MRAM存储器也应用于各级高速缓存
2020-11-09 16:46:48628 1. 什么是缓存 缓存又叫高速缓存,是计算机存储器中的一种,本质上和硬盘是一样的,都是用来存储数据和指令的 。它们最大的区别在于读取速度的不同。程序一般是放在内存中的,当CPU执行程序的时候,执行
2021-03-22 10:22:2110507 
本文档概述了不同场景下的高速缓存一致性问题,并就如何管理或避免高速缓存一致性问题提供了一些方法建议。
2021-04-01 10:12:415 本文档提供了PIC32MZ 器件系列中一级(Level 1, L1)CPU高速缓存实现的相关信息,并介绍了高速缓存系统的相关风险。此外还提供了解决这些风险的方法。
2021-04-02 09:14:236 1.计算机存储体系简介 存储器是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,其次是高速缓存(缓存也是分级
2021-06-19 09:15:063389 模拟计算机顾名思义,使用模拟量进行计算。但由于容易受到外界环境干扰,难以得到精确解,并且随着数字电路不断地发扬壮大,模拟计算机被抛弃在了历史的长河中。那模拟计算机相比数字计算机真的就一无是处了吗?如果你也同意这样的观点,那你就看低了你自己。因为人的大脑就是一台天然的模拟计算机。
2022-08-01 18:17:502002 
程序的写入是指将程序由编程计算机送入PLC,读出则是将PLC内的程序传送到计算机中。程序的读出操作过程与写入基本类似,可参照学习,这里不做介绍。在对PLC进行程序写入或者读出时,除了要保证PLC与计算机通信连接成功外,PLC还需要接上工作电源。
2022-10-04 10:54:001677 缓存又叫高速缓存,是计算机存储器中的一种,本质上和硬盘是一样的,都是用来存储数据和指令的 。它们最大的区别在于读取速度的不同。
2022-10-10 14:41:29784 使用STM32高速缓存优化性能和能效
2022-11-21 17:07:400 在量子计算机中,同轴连接器和线缆是一种常见的传输和控制微波信号的技术。这些组件可以帮助将信号从外部控制器传输到量子比特,从而实现量子计算的操作和运行。
2023-05-11 16:30:48753 
电子发烧友网站提供《STM32F7技术--高速缓存.pdf》资料免费下载
2023-08-01 15:18:550 cmos技术在计算机中的应用 CMOS技术(互补金属氧化物半导体技术)是现代电子设备制造过程中使用最广泛的技术之一。CMOS技术结合了MOSFET晶体管的特性,利用正负电荷的互补作用,使得芯片的功耗
2023-09-05 17:39:23953 电子发烧友网站提供《使用MPLAB Harmony v3基于PIC32MZ MCU在运行时使用高速缓存维护操作处理高速缓存一致性问题.pdf》资料免费下载
2023-09-19 16:28:100 电子发烧友网站提供《利用MPLAB Harmony v3在Cortex-M7 MCU上在运行时使用高速缓存维护操作处理高速缓存一致性问题.pdf》资料免费下载
2023-09-20 11:40:240 电子发烧友网站提供《管理基于Cortex-M7的MCU的高速缓存一致性.pdf》资料免费下载
2023-09-25 10:11:480
 电子发烧友App
电子发烧友App


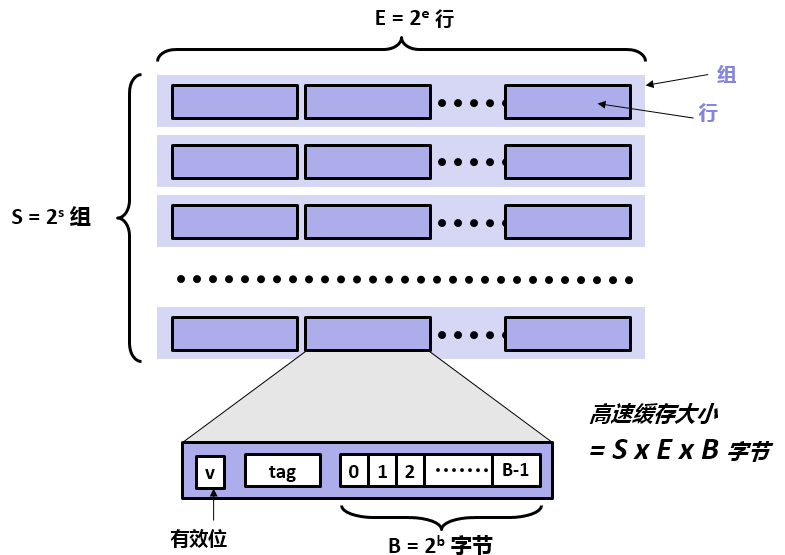 计算机中的高速缓存模型
计算机中的高速缓存模型 image-20201231160527635
image-20201231160527635








 工商网监
工商网监
评论