 电子发烧友App
电子发烧友App


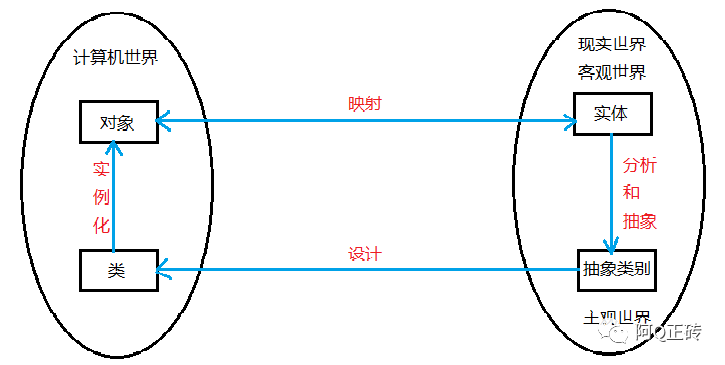
面向对象编程(OOP),是一种设计思想或者架构风格。OO语言之父Alan Kay,Smalltalk的发明人,在谈到OOP时是这样说的:
OOP应该体现一种网状结构,这个结构上的每个节点“Object”只能通过“消息”和其他节点通讯。每个节点会有内部隐藏的状态,状态不可以被直接修改,而应该通过消息传递的方式来间接的修改。
以本段话作为开场,展开本文的探讨。
1. 面向对象的实质
1.1 面向对象编程是为了解决什么问题?
大部分程序员都学过c语言,尤其是嵌入式工程师,可能只会c语言。
c语言是一项典型的面向过程的语言,一切都是流程。简单的单片机程序可能只有几行,多的也不过几百行。这时一个人的能力是完全可以走通整个代码,但引入操作系统后,事情就变得复杂了。
进程调度、内存管理等各种功能使得代码量剧增,一个简单的RTOS实时操作系统都达到了上万行代码,这个时候,走通也不是不行,就是比较吃力。
但Linux代码量就完全不是正常人能读完的,一秒钟读一行代码,每天读12小时,也需要几年才能读完Linux的源码,这还仅仅是读完,而不是理解。
再举一个简单的例子
小公司往往只有几个人,大家在一起干活,你完完全全可以看到每个人在干什么。
在大公司中呢?几千、上万人的公司中,你要去弄清楚,每个人在干嘛,这是完全不可能的。于是就有了部门,各部门区分职责,各司其职,你可能不知道单个人的工作细节,但你只需要知道,销售部负责卖,研发部负责研发,生产部负责生产......
面向对象编程要解决的根本问题就是将程序系统化组织起来,从而方便构建庞大、复杂的程序。
1.2 编程语言和面向对象编程的关系
很多人往往把编程语言和面向对象联系起来,比如c语言是面向过程的语言,c++是面向对象的语言,其实不完全准确。
面向对象是一种设计思想,用c语言也可以完全实现面向对象,用c++等语言写出的程序可能是也面向过程而非对象。
c语言实现面向对象一个最明显的例子就是Linux内核,可以说是完完全全采用了面向对象的设计思想,它充分体现了多个相对独立的组件(进程调度、内存管理、文件系统……)之间相互协作的思想。尽管Linux内核是用C语言写的,但是他比很多用所谓OOP语言写的程序更加OOP。
这里用c++说明一下,为什么面向对象语言也会写出面向过程的程序:
本段适合有一些c++基础的朋友,不会c++可跳过不看。
比如一个计算总价的程序,无非是数目*单价
#include< iostream >
using namespace std;
class calculate{
public:
double price;
double num;
double result(void){
return price*num;
}
};
int main ()
{
calculate a;
a.price=1;
a.num=2;
cout<
增加一个功能,双11,打八折,你会怎么写?
#include< iostream >
using namespace std;
class calculate{
public:
double price;
double num;
int date;
double result(void){
if(date==11)
return price*num*0.8;
else
return price*num;
}
};
int main ()
{
calculate a;
a.price=1;
a.num=2;
cout< < "please input the date:"<
如果这样写,就是典型的面向过程思想,为什么?如果再加一个双12打七折,按照这个思路怎么写?再在calculate类里面加一个if else 判断一下,如果来个过年打5折呢?再再在calculate类里面加一个if else 判断一下。我们再来看一下面向对象的思想该怎么写:
#include< iostream >
using namespace std;
class calculate{
public:
double price;
double num;
virtual double result(void){
}
};
class normal:public calculate{
public:
double result(void){
return price*num;
}
};
class discount:public calculate{
public:
double result(void){
return price*num*0.8;
}
};
int main ()
{
calculate *a;
int date;
cout< < "please input the date:"<
利用了继承和多态,把双11抽象出一个单独的类,继承自calculate类,把平时normal也抽象出一个单独的类,继承自calculate类。在子类中提供result的实现。
如果来个双12,该怎么写?再写一个双12的类,继承自calculate类并实现自己的result计算。
有朋友可能疑惑了,你这在主函数main中不还是要进行if else判断吗,和第一种有什么区别?
区别就在于,我添加新需求的时候不再需要修改原来的代码,(原来的代码指计算的核心部分)充分吸收了原代码的特性。
当我不需要某个功能时,我把对应的类删了就行,灵活、扩展性强。
这里看着没什么差别是因为这代码简单,当实现一个复杂的功能时,代码经过测试后,就不应该去动他了,第一种方法不断修改核心部分,带来很大的隐患,而且若原来的代码复杂度高,修改难度会很高。
这里要特别强调,简单用面向对象编程语言写代码,程序也不会自动变成面向对象,也不一定能得到面向对象的各种好处
所以面向对象重在思想,而非编程语言,在第二节中,我将谈谈,linux内核是如何用c语言体现面向对象思想的。
1.3 面向对象是指封装、继承、多态吗?
其实从1.1举例大公司的例子和1.2中举例两个c++程序不同的例子中,就可以看出来,封装、继承、多态只是面向对象编程中的特性,而非核心思想。
面向对象编程最根本的一点是屏蔽和隐藏
每个部门相对的独立,有自己的章程,办事方法和规则等。独立性就意味着“隐藏内部状态”。比如你只能说申请让某部门按照章程办一件事,却不能说命令部门里的谁谁谁,在什么时候之前一定要办成。这些内部的细节你看不见,也管不着。
应当始终记住一件事情,面向对象是为了方便构建复杂度高的大型程序。
2. Linux内核中面向对象思想的体现
2.1 封装
封装的定义是在程序上隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别;将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员。
面向对象中的封装,把数据,和方法(函数)放到了一起。
在c语言中,定义一个变量,int a,可以再定义很多函数fun1,fun2,fun3.
通过指针,这些函数都能对a修改,甚至这些函数都不一定与a在同一个.c文件中,这样就特别混乱。
但是我们也可以进行封装:
struct file {
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
略去一部分
}
例如Linux内核中的struct file,里面有file的各种属性,还包含了file_operrations结构体,这个结构体就是对file的一堆操作函数
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
int (*open) (struct inode *, struct file *);
略去一部分
}
file_operations结构体里是一堆的函数指针,并不是真正的操作函数,这是为了实现多态。
实际上这个例子也很像继承,struct file继承了struct file_operations的一切,但我会用其他例子来更好体现继承。
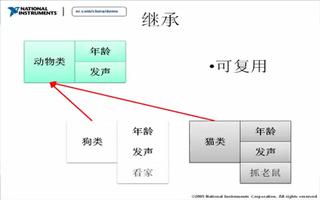
2.2 继承
特殊类(或子类、派生类)的对象拥有其一般类(或称父类、基类)的全部属性与服务,称作特殊类对一般类的继承。
从继承的思想和目的来看,就是让子类能够共享父类的数据和方法,同时又能在父类的基础上定义扩展新的数据成员和方法,从而消除类的重复定义,提高软件的可重用性。
c语言中一个链表结构如下:
struct A_LIST {
data_t data; // 不同的链表这里的data_t类型不同。
struct A_LIST *next;
};
Linux 内核中有一个通用链表结构:
struct list_head {
struct list_head *next, prev;
);
可以把这个结构体看作一个基类,对它的基本操作是链表节点的插入,删除,链表的初始化和移动等。其他数据结构(可看作子类)如果要组织成双向链表,可以在链表节点中包含这个通用链表对象(可看作是继承)。
同上面的例子,我们只需要声明
struct A_LIST {
data_t data;
struct list_head *list;
};
链表的本质就是一个线性序列,其基本操作为插入和删除等,不同链表间的差别在于各个节点中存放的数据类型,因此把链表的特征抽象成这个通用链表,作为父类存在,具体不同的链表则继承这个父类的基本方法,并扩充自己的属性。
通用链表其作为一个连接件,只对本身结构体负责,而不需要关注真正归属的结构体。正如继承的特性,父类的方法无法操作也不需要操作子类的成员。
关于链表结构的宿主指针获取方法,
获取结构类型TYPE里的成员MEMBER 在结构体内的偏移
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)- >MEMBER)
通过指向成员member的指针ptr获取该成员结构体type的指针
#define container_of(ptr, type, member) ({
const typeof(((type *)0)- >member)*__mptr = (ptr);
(type *)((char *)__mptr - offsetof(type, member)); })
**2.3 多态 **
Linux中多态最明显的例子就是字符设备应用程序和驱动程序之间的交互,应用程序调用open,read,write等函数打开设备即可操作,而并不关心open,read,write是如何实现,这些函数的实现在驱动程序之中,而不同设备的open、read、write函数各不相同,实现与多态中的运行时多态一样的功能。
过程简化其实就是不同的驱动程序实现
struct file_operations drv_opr1
struct file_operations drv_opr2
struct file_operations drv_opr3
而应用程序运行时根据设备号找到对应的struct file_operations,并将指针指向他,即可调用对应的struct file_operations里的open,read,write函数(实际过程比这复杂)。
一个带有面向对象雏形的c程序:
#include< stdio.h >
double normal_result(double price,double num)
{
return price * num;
}
double discount_result(double price,double num)
{
return price * num * 0.8;
}
struct calculate{
double price;
double num;
double (*result)(double price,double num);
};
int main ()
{
struct calculate a;
int date;
a.price=1;
a.num=2;
printf("please input the date:n");
scanf("%d",&date);
if(date==11)
a.result=discount_result;
else
a.result=normal_result;
printf("%lfn",a.result(a.price,a.num));
return 0;
}















 工商网监
工商网监
评论