 电子发烧友App
电子发烧友App


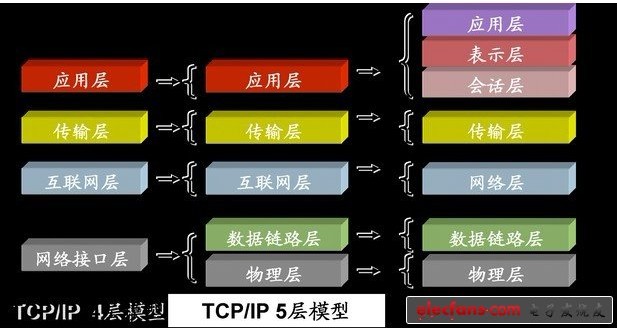
1、tcp/ip协议栈分为四层
或者七层,但是便于大家理解,基本上都是用四层模型,如:数据链路层,网络层,传输层和应用层。
其中封包的流程是:
应用层数据 --- >
tcp/udp头部(20字节) + 应用层数据 --- >
ip头部(20字节) + tcp/udp头部(20字节) + 应用层数据 --- >
以太网头部(18字节) + ip头部(20字节) + tcp/udp头部(20字节) + 应用层数据
这些数据每一个头部都有自己的协议,并发送到对端模块进行解析,其中对于发送数据大小的要求是有相应的限制,在以太网这一层数据必须46字节-1500字节之间,不足的情况下填充数据,超过的情况下拆分ip包数据;
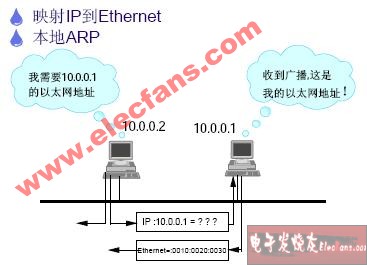
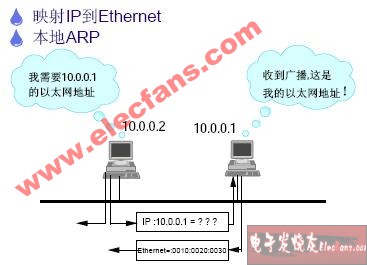
2、arp协议工作原理
主机向自己所在的网络广播一个arp请求,请求获取目标ip地址的物理地址,请求发出后所在的网络(局域网)都会收到这个请求,当匹配该ip请求的机器就主动回包含自己物理地址;
3、dns解析原理
tcpdump抓包(tcpdump -i eth0 -nt -s 500 port domain):
08:41:28.266682 IP 192.168.1.100.51468 > 202.96.134.33.53: 42940+ A? www.google.com.hk. (35)
08:41:28.271805 IP 202.96.134.33.53 > 192.168.1.100.51468: 42940 1/0/0 A 93.46.8.89 (51)
08:41:29.827625 IP 192.168.1.100.13671 > 202.96.134.33.53: 14422+ A? sp0.baidu.com. (31)
08:41:29.827843 IP 192.168.1.100.29083 > 202.96.134.33.53: 4498+ A? ss1.baidu.com. (31)
08:41:29.828060 IP 192.168.1.100.38240 > 202.96.134.33.53: 35663+ A? ss2.baidu.com. (31)
08:41:29.828341 IP 192.168.1.100.11330 > 202.96.134.33.53: 42502+ A? www.baidu.com. (31)
08:41:29.828513 IP 192.168.1.100.21489 > 202.96.134.33.53: 20283+ A? ss0.baidu.com. (31)
08:41:29.828710 IP 192.168.1.100.37763 > 202.96.134.33.53: 6612+ A? ss1.bdstatic.com. (34)
08:41:29.838009 IP 202.96.134.33.53 > 192.168.1.100.11330: 42502 2/0/0 A 14.215.177.38, A 14.215.177.37 (63)
08:41:29.839022 IP 202.96.134.33.53 > 192.168.1.100.13671: 14422 2/0/0 A 14.215.177.37, A 14.215.177.38 (63)
dns是udp协议,192.168.1.100发送dns解析,42940是dns查询标示,+是采用递归查询,A?是使用A类查询(A方式是查找ip,CNAME方式是查询主机别名,PTR是反向查询)。
202.96.134.33.53回包解析42940是发送dns解析的标示,1/0/0是1个应答资源,0个授权资源记录和0个额外信息记录,A是A类查询返回,93.46.8.89是返回www.google.com.hk域名的ip地址;
4、ip协议
ip是无连接,无状态,不可靠的协议,是tcp/udp的动力,决定了路由和转发的功能,ipv4的头部结构如下:
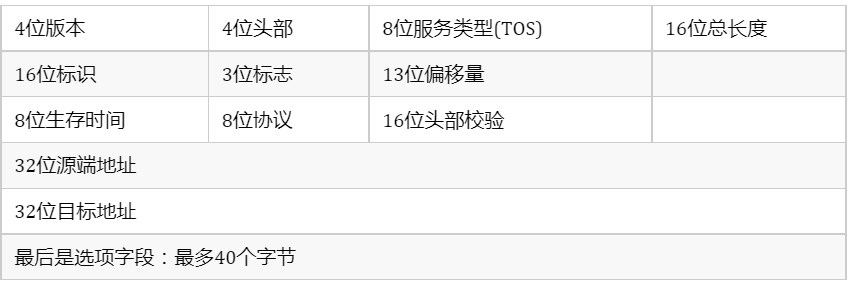
重点介绍字段:
TOS字段分别表示最小延时,最大吞吐量,最高可靠性和最小费用;
16位总长度指整个ip数据的长度;
8位的TTL生存时间指数据包到目的地之前允许经过的路由跳数,数据报在转发的过程中每次经过一个路由都会-1,当TTL为0时,路由器将其丢弃,并向源端发送icmp的差错报文;
5、ip分片和转发
当ip数据报的长度超过帧的MTU时,将会被分片,其中分片可能会发生在发送端,也可能是路由转发阶段;
一个ip数据报每个分片具有自己的ip头部,相同的标识值,但是具有不同偏移量,并且除了最后一个分片不带有MF标志,其他的分片都带有MF标志。
下面看一个抓包的例子,ping的数据包,协议是icmp,命令ping www.baidu.com -s 1473[发送1473个数据信息]:
IP (tos 0x0, ttl 64, id 4454, offset 0, flags [+], proto ICMP (1), length 1500)
192.168.1.100 > 14.215.177.37: ICMP echo request, id 51842, seq 2, length 1480
IP (tos 0x0, ttl 64, id 4454, offset 1480, flags [none], proto ICMP (1), length 21)
192.168.1.100 > 14.215.177.37: ip-proto-1
从以上包可以分析:tos:最小延时;
ttl:64跳;
id:4454标识相同;
offset:偏移量分别是0和1480,将icmp分片1500(20个ip报头,8个icmp报头,1472数据)和21(20个ip报头,1个icmp数据,由于下一个数据报不需要携带icmp的数据报头);
本小节还有一个知识点是ip数据报在主机上的转发,主机一般都不转发,不过可以设置echo 1 > /proc/sys/net/ipv4/ip_forward,那么转发逻辑如下:
- 1、检查数据报头部的ttl,如果为0则丢弃该数据包;
- 2、查看数据报头部的严格路由选择项,如果该项被设置,则检测数据报的目标地址是否为本机的ip,如果不是,则发送icmp源站选路失败报文给发送端;
- 3、如果有必要,则给源端发送icmp的重定向报文,告诉下一跳ip路由器;
- 4、将ttl值减1,同时处理其他ip头部选项;
- 5、如果包超过当前路由器的MTU,则进行ip分片操作;
6、ipv6头部结构
ipv6协议是为了解决ipv4不够用的情况,同时增加很多功能,如多播和流功能等,ipv6的头部结构如下(40字节+可变头部):

重点介绍字段:
20位流标签是ipv6新增字段,用于对于某些对连接服务质量有特殊要求的通信;
ipv6提供了多种扩展数据,如认证头部和加密头部等;
第二部分:tcp/ip协议栈之tcp协议栈详解
tcp协议在我们的应用中非常重要,本小节主要从四方面讨论tcp协议:
- 1)tcp的头部协议,每个tcp报文都包含20字节的头部字节,指定四元组(目的ip,目的端口,源ip,源端口);
- 2)tcp的状态转移,tcp从三次握手到四次挥手过程中状态跳变,如深入理解有助于排查网络问题;
- 3)tcp的数据流,包括交互数据流,成块数据和紧急数据;
- 4)tcp数据流的控制,为了保障可靠传输和网络质量,内核对tcp数据进行控制,包括超时重传和拥塞控制;
1、tcp数据特点
tcp传输是可靠的,首先协议采用应答机制,即对发送端的每个数据报都必须得到对端的应答确认,才认为本次报文传输成功;
其次tcp采用超时重传,发送端在发送数据后就启动定时器,如果在定时时间内未收到应答,将重发该数据报;
最后tcp报文最终以ip数据报发送,而ip数据报是无序或重复的,那么tcp协议需要对ip层来的数据进行重排和丢弃等操作;
2、tcp的头部结构

32位的序号:一次tcp通讯过程中某个传输方向上字节流的每个字节的编号,初始化阶段为一个随机值,后续的tcp报中的序号设置为初始值+该报文在所携带的数据的第一个字节在整个字节流的偏移量;
32位的确认号:是对端的32位的序号+1;
4位头部长度:标识tcp头部32个字节的大小,由于只有4位,所以tcp头部最长位60字节;
6位标识:URG(紧急指针),ACK(确认包),PSH(数据包),SYN(建立连接包),FIN(关闭连接包);
16位窗口大小:指接受通告窗口大小,告诉对端tcp本端接受缓冲区的数据大小,让对端控制发送速度;
16位校验和:tcp的报文crc校验;
16位紧急指针:序号字段的值+该值的下一个字节表示紧急数据的偏移量;
选项数据:在后续的博客中再详细介绍;
具体的数据报样例:
19:23:14.767712 IP 192.168.1.100.61976 > 139.129.212.166.http: Flags [S], seq 2580028945, win 65535, options [mss 1460,nop,wscale 5,nop,nop,TS val 1032935471 ecr 0,sackOK,eol], length 0
19:23:14.823856 IP 139.129.212.166.http > 192.168.1.100.61976: Flags [S.], seq 3491427708, ack 2580028946, win 14480, options [mss 1360,sackOK,TS val 3615337495 ecr 1032935471,nop,wscale 7], length 0
19:23:14.823905 IP 192.168.1.100.61976 > 139.129.212.166.http: Flags [.], ack 1, win 4128, options [nop,nop,TS val 1032935521 ecr 3615337495], length 0
19:23:20.376906 IP 192.168.1.100.61976 > 139.129.212.166.http: Flags [P.], seq 1:14, ack 1, win 4128, options [nop,nop,TS val 1032940499 ecr 3615337495], length 13: HTTP
说明:
上面的报文的第一条请求中看出Flags [S]表示syn包,seq序号2580028945,窗口大小655352^5(需要计算options中的wscale 5扩大因子选项),options是选项字段;
第二条请求是回包数据,Flags [S.]表示syn,ack包,seq序号3491427708,ack确认序号2580028945+1,窗口大小144802^7(需要计算options中的wscale 7扩大因子选项),options是选项字段;
3、tcp的状态转移
tcp在建立连接和断开连接分别要经过三次握手和四次挥手,那么都会有相应的服务器端口状态,只描述三次握手和四次挥手双端的状态,如图:

server状态转移语意:
a.服务器在listen调用进入LISTEN状态,等待客户端连接;
b.服务器监听到客户端连接,就将该连接放入内核的等待队列,并向客户端发送SYN,ACK报文,进入SYN_RECVD状态,此时客户端处于SYN_SENT阶段;
c.服务器收到客户端的ACK报文,进入ESTABLISHED状态;
d.客户端主动关闭连接(通过close和shutdown发送FIN包),服务器返回ACK报文后进入CLOSE_WAIT状态;
e.在服务端发送完所有数据给客户端以后(客户端此时只读不写,处于半关闭状态),发送FIN,ACK到客户端,进入LAST_ACK状态;
f.最后服务端收到客户端发送ACK包后,进入CLOSED状态,关闭连接句柄;
client状态转移语意:
a.客户端通过connect连接服务器,connect失败后直接进入CLOSED状态,连接成功进入ESTABLISHED状态;
b.客户端向服务端发送FIN包,进入FIN_WAIT_1状态,收到服务端的确认包进入FIN_WAIT_2状态;
c.客户端处于FIN_WAIT_2状态,服务端处于CLOSE_WAIT状态,此时可能处于半关闭,此时服务端可以发送和接收数据,但是客户端只能接受数据;
d.客户端收到服务端的FIN,ACK包后,进入TIME_WAIT,此时客户端要等待2MSL(报文最大生存时间的2倍,一般是2min) ,可能大家比较疑惑,为什么需要TIME_WAIT状态,而且需要等2MSL呢?
TIME_WAIT状态存在原因有两点:
其一是可靠的中止tcp连接;
其二是保证让延迟的tcp报文有足够的时间被识别;
客户端在关闭连接阶段需要处理收到重复的结束报文,然后回复最后的ACK给服务端,否则客户端在收到服务端的FIN就直接回复ACK,这样后续服务端重传的FIN包都会被回复RESET报文,这时服务端认为是错误报文,这就是第一点存在的原因;
那么第二点是为了不让同一个tcp端口被多次打开或者是断开以后马上被一个新的连接接管,这样存在数据安全和处理异常等问题,让tcp最大时间坚持2MSL也是为了确保重发和延时的tcp包在这段时间内被丢弃(使用端口复用采用socket选项SO_REUSEADDR);
3、tcp的数据流
往往按照正常的tcp模型,一个数据包回复一个确认包可能不适应某些生产环境,为了更好的优化tcp模型,下面讨论两种数据交互模型:
- 1、交互数据流:对于实时性比较高的应用(如telnet,ssh),每次发送一个都需要进行数据确认,但是在网络不好的情况下,很多微小的数据包会导致拥塞发送,因此采用Nagle算法(在后续章节介绍)和延时确认(即收到对端的数据包的时候,先不立即发送数据包,等到需要发送数据时候同时发出ACK包,当然这个控制在一定时间范围内);
- 2、成块数据流:对于类似ftp协议,多次发送大量的数据,接受端为了加快ACK确认包的顺序,针对多个数据包进行一次确认或者开启SACK(针对需要重传的数据,回复对应的偏移指针),其中对端发送数据多次发送数据是根据接受端的窗口大小限制的,如果接受端参数win 30084,scale 6,表示还能接收3008464个字节,其中一次发送16384字节,那么接受端还能同时处理(3008464)/16384=106个数据包(一般不会发送这么多);
4、tcp超时重传和拥塞控制
tcp服务必须能够重传超时时间内未收到的tcp报文段。
为此,tcp模块为每一个tcp报文都维护一个重传定时器,linux两个重传相关的内核参数:/proc/sys/net/ipv4/tcp_retries1和/proc/sys/net/ipv4/tcp_retries2
前者表示tcp最少执行重传次数,默认为3;
后者表示tcp最多执行重传次数,默认为15;
tcp服务有重传必然就会导致拥塞,那么接下来介绍网络底层如何进行拥塞控制?
拥塞控制包括四个部分:慢启动,拥塞避免,快速重传和快速恢复;
在此之前还需要介绍窗口概念:RNWD(接收窗口,指前面tcp报文中的对端发送的win窗口),CWND(拥塞窗口,是系统定义的一个状态变量大小),SWND(发送窗口,是RNWD和CWND之间的较小值);
在tcp模块刚开始发送数据阶段并不知道网络的实际情况,需要试探性地增加CWND,这一过程称为慢启动,CWND初始值设置为2-4个MSS;然后发送端每次收到接受端的一个确认,就按照公式:
CWND += min(N, MSS)
其中N是此次确认中包含的之前未确认的字节数;
如果随着CWND不断累加,不加控制会造成网络拥塞,那么需要进行拥塞避免算法,界定慢启动和拥塞避免过程通过慢启动门限(ssthresh)控制,当CWND超过ssthresh则进入拥塞避免阶段;
拥塞避免阶段控制CWND是每个RTT时间都计算(如果RTT时间内收到多少确认包),公式:
CWND += SMSS*SMSS/CWND
这样就保障了CWND缓慢增长,直到传输超时或者tcp重传定时器溢出,就需要重新调整ssthresh,再次进入慢启动阶段,那么ssthresh计算公式:
ssthresh = max(FlightSize/2, 2MSS)
其中FlightSize已经发送但是还未收到确认的字节数;
另外一种情况:在接受端接收到重复的确认报文段的时候,tcp模块如何处理?
如果发送端收到3个重复的确认报文,认为拥塞发生,启动快速重传和快速恢复,先计算ssthresh;
然后通过CWND = ssthresh + 3 * SMSS计算出CWND,再次每收到1个重复确认时,设置CWND += SMSS,最后当收到新数据的确认时,直接设置CWND = ssthresh,这样快速重传和快速恢复完成,又再次进入拥塞避免阶段。
5、补充知识
复位报文产生条件:
- 1、访问不存在的端口;
- 2、异常中止连接,当发送端回复一个RST报文给接受端,接受端所有的排队等待发送的数据都将被丢弃;
- 3、处于半连接状态写入数据时候,也会回复一个RST报文;












 工商网监
工商网监
评论