 电子发烧友App
电子发烧友App


1. 垫话
本文乃《Illustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiving Data》一文的翻译,是系列文章的第二篇。
2. 前言
本文为《[译 1] linux 网络栈监控及调优:数据接收》一文添加图解,旨在帮助读者更清晰地了解 linux 网络栈。 在 linux 网络栈的监控及调优上没有捷径可言,如果你想做有效的调优,就必须搞清楚各个系统之间是怎么交互的。上一篇文章因为篇幅的缘故,可能会让读者难以从大图上了解各系统之间是怎么拉通的,希望本文可以。
3. 开始
本文的图解旨在描绘 linux 网络栈工作原理的大图,会忽略大量细节。如果想要全面了解,还是推荐阅读上一篇文章,其中包含了网络栈的各方面细节。本文的图解,旨在帮助读者建立起 high level 的内核子系统交互的思维模型。 咱们从初始化工作开始,这是理解 packet 处理的必要前提。
4. 初始化
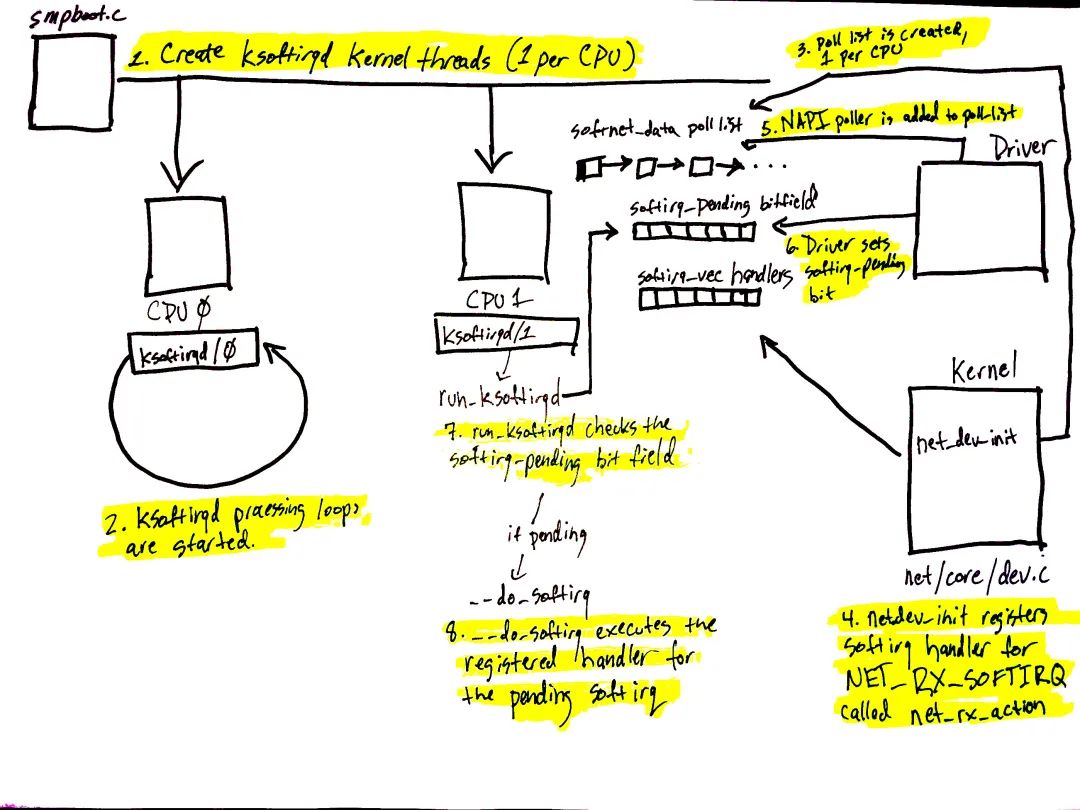
图 1 网络设备在 packet 到达并需要处理时,通常会触发一个 IRQ。IRQ 处理函数是在很高的优先级下执行的,一般会阻塞其他 IRQs 的触发(译者注:often blocks additional IRQs from being generated。个人觉得原文这里并不准确,中断上下文中关中往往只是让 CPU 不响应中断,而不是让其他设备直接不发出中断)。故而,设备驱动中的 IRQ 处理函数必须越快越好,并将比较耗时的工作挪到中断上下文之外去执行,这就是为啥会有软中断系统。 linux 内核软中断系统支持在设备驱动的中断上下文之外处理工作。网络设备场景下,软中断系统用作处理 incoming packets。内核在 boot 阶段做软中断系统的初始化。 图 1 对应前文“软中断”一节,展示的是软中断系统及其 per-CPU 内核线程的初始化。 软中断系统的初始化流程如下:
spawn_ksoftirqd(kernel/softirq.c)调用 smpboot_register_percpu_thread(kernel/smpboot.c)创建软中断内核线程(每个 CPU 一个)。如代码所示,run_ksoftirqd 作为 smp_hotplug_thread 的 thread_fn,会在一个 loop 中被执行。
ksoftirqd 线程会在 run_ksoftirqd 中运行其 processing loop。
随后,创建 softnet_data 数据结构(前文“struct softnet_data 数据结构初始化”一节),每个 CPU 一个。此数据结构包含在网络数据处理时所需要的重要信息。另外还有一个 poll_list,下文会说。设备驱动调用 napi_schedule 或其他 NAPI APIs,将 NAPI poll 数据结构添加至 poll_list 上。
net_dev_init 调用 open_softirq 向软中断系统注册 NET_RX_SOFTIRQ 软中断,被注册的软中断处理函数是 net_rx_action(前文“软中断处理函数初始化”一节)。软中断内核线程会调用此函数来处理 packets。
图 1 中的第 5 - 8 步与数据的到达有关,下一节会说。
5. 数据到达
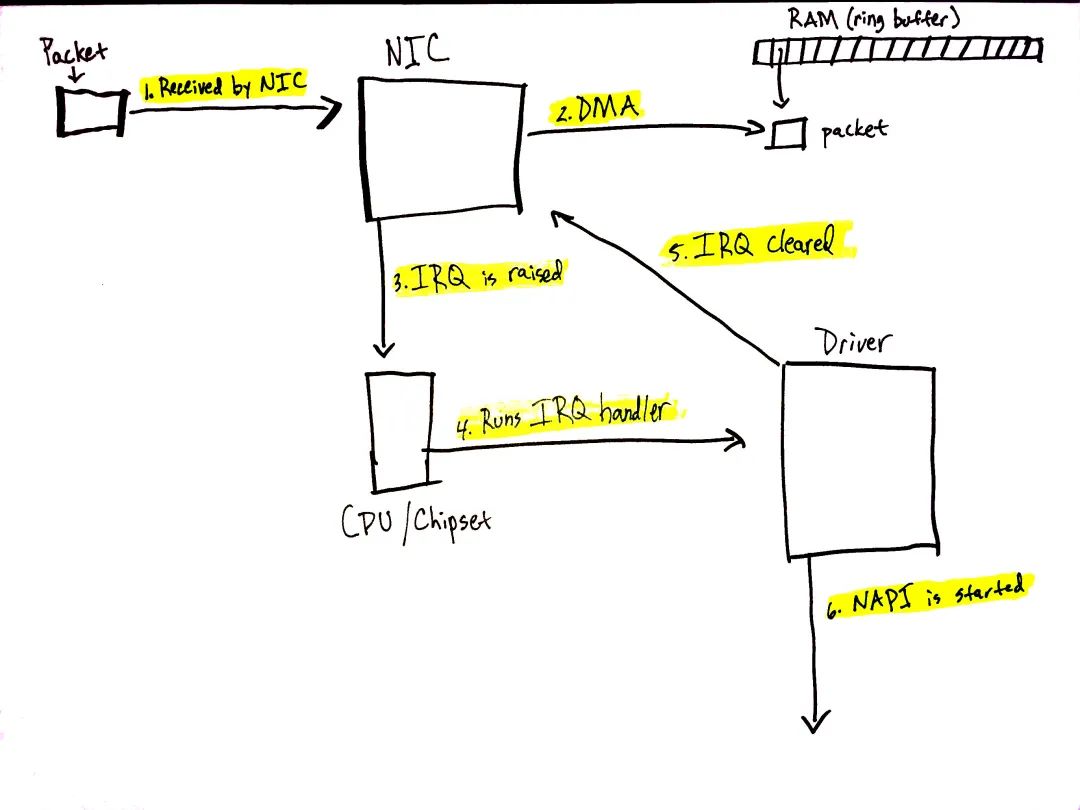
图 2 数据从网络上来了(前文“数据到达”一节)! 网络数据到达 NIC 时,NIC 会通过 DMA 将 packet 数据写入 RAM。igb 网络驱动会在 RAM 中构建一个 ring buffer,其指向接收到的 packets。值得注意的是,有些 NIC 支持 "multiqueue",这些 NIC 可以使用多个处理器来处理 incoming 网络数据(前文“准备从网络接收数据”一节)。简化起见,图 2 只画了一个 ring buffer,但取决于 NIC 以及硬件配置,你的系统可能使用的是多个队列。 下面流程的细节参阅前文“数据到达”一节。 我们来过一遍数据接收流程:
数据从网络到达 NIC。
NIC 通过 DMA 将网络数据写入 RAM。
NIC 触发一个 IRQ。
执行设备驱动注册的 IRQ 处理函数(前文“中断处理”一节)。
NIC 清除 IRQ,这样新 packet 到来时可以继续触发 IRQs。
调用 napi_schedule 拉起 NAPI 软中断 poll loop(前文“NAPI 与 napi_schedule”一节)。
napi_schedule 的调用触发了 图 1 中的 5 - 8 步。如后面所见,NAPI 软中断 poll loop 拉起的原理,就是翻转一个 bit 域,并向 poll_list 上添加一个数据结构。napi_schedule 没干什么其他事,这就是驱动将处理工作转交给软中断系统的原理。 继续分析 图 1,对照图中相应的数字:
驱动调用 napi_schedule 将驱动的 NAPI poll 数据结构添加至当前 CPU 的 poll_list 上。
软中断 pending bit 会被置上,如此该 CPU 上的 ksoftirqd 线程知晓有 packets 需要处理。
执行 run_ksoftirqd 函数(在 ksoftirqd 内核线程的 loop 中执行)。
调用 __do_softirq 检查是否有 pending 的 bit 域,以此确认是否有 pending 的软中断,进而调用 pending 软中断的处理函数:net_rx_action,该函数干了所有的 incoming 网络数据处理的脏活。
需要注意的是,软中断内核线程执行的是 net_rx_action,而不是设备驱动的 IRQ 处理函数。
6. 网络数据处理的开始
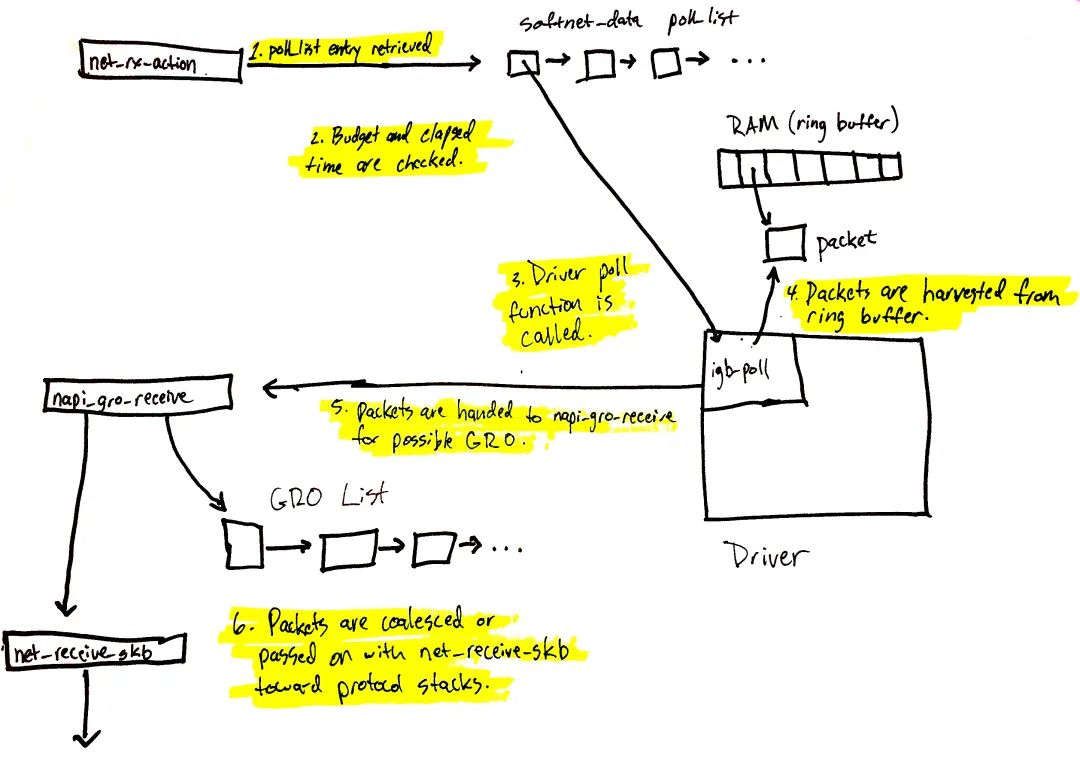
图 3 至此开始数据的处理。net_rx_action 函数(在 ksoftirqd 内核线程中调用)会执行当前 CPU poll_list 上注册的 NAPI poll 数据结构。poll 数据结构的注册一般有两种情况:
设备驱动调用 napi_schedule。
Receive Packet Steering 场景(前文“Receive Packet Steering(RPS)”一节)下使用 Inter-processor Interrupt。
我们将从 poll_list 获取驱动 NAPI 数据结构的流程串起来(下一节会讲 RPS 是怎么通过 IPIs 注册 NAPI 数据结构的)。 图 3 流程在前文有详细拆解过,总结一下就是:
net_rx_action poll 检查 NAPI poll list 中的 NAPI 数据结构。
校验 budget 及消耗的时间,以确保软中断不会霸占 CPU。
调用注册的 poll 函数(前文“NAPI poll 函数及权重”一节)。本文场景下,igb 驱动注册的是 igb_poll 函数。
驱动的 poll 函数收取 RAM ring buffer 中的 packets(前文“NAPI poll”一节)。
packets 进一步给到 napi_gro_receive,其可能会进一步被 Generic Receive Offloading 处理(前文“Generic Receive Offloading(GRO)”一节)。
packets 要么被 GRO 处理,这样整个调用链也就结束了;要么 packets 通过 net_receive_skb 进一步给到上层协议栈。
下面会讲 net_receive_skb 是怎么实现 Receive Packet Steering,也就是在多个 CPUs 之间分发 packet 的。
7. 网络数据的进一步处理
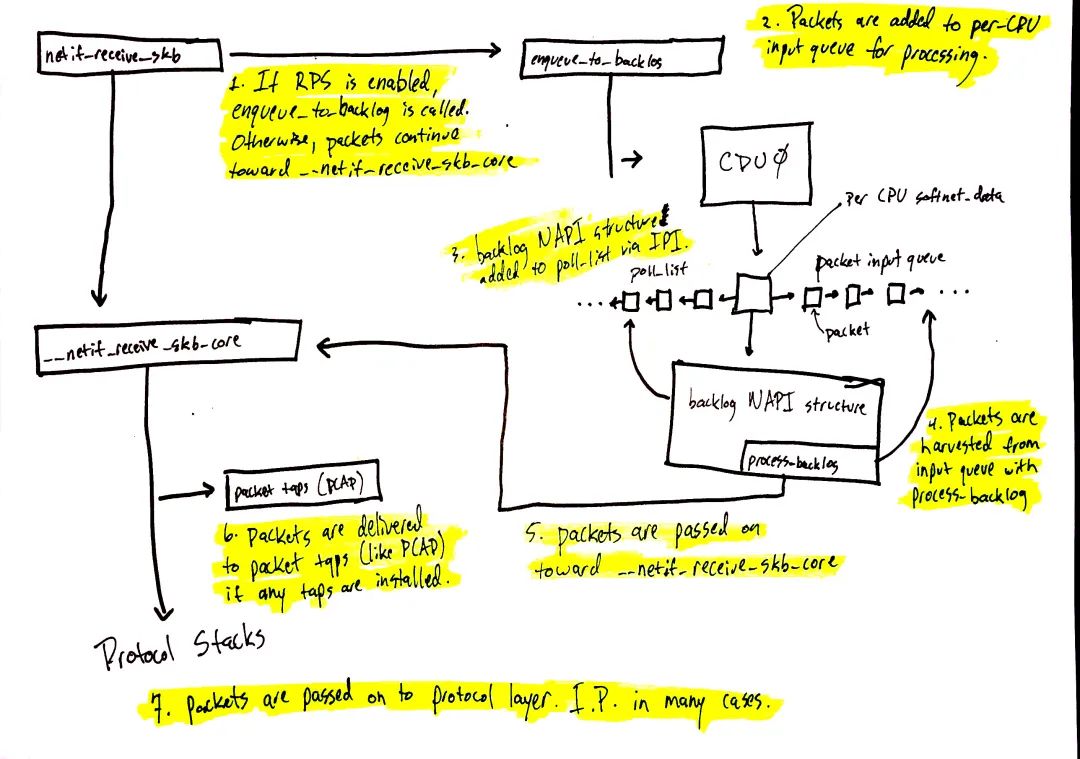
图 4 从 netif_receive_skb 开始继续网络数据的处理,数据的具体路径取决于是否使能了 Receive Packet Steering(RPS)。一个“开箱即用”的 linux 内核(译者注:意思就是通用的发行版)默认是不使能 RPS 的,如果你想用 RPS,就必须显式地配置及使能之。 RPS 禁能的情况下(前文“禁能 RPS 场景(默认配置)”一节),对应 图 4 中的如下数字:
1. netif_receive_skb 将数据给到 __netif_receive_core。
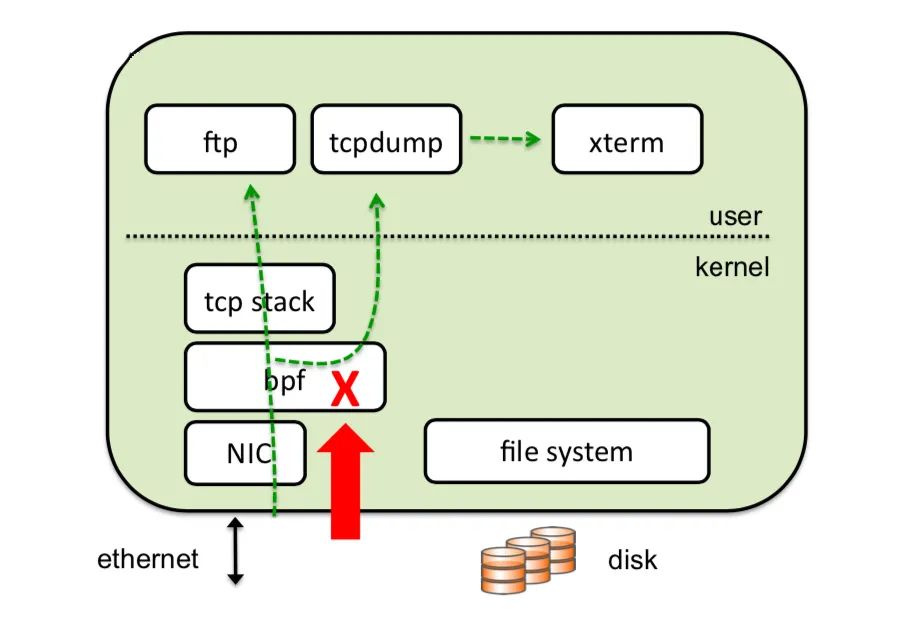
6. __netif_receive_core 将数据给到系统中可能存在的 taps(前文“packet tap 投递”一节)(比如 PCAP,https://www.tcpdump.org/manpages/pcap.3pcap.html)。
7. __netif_receive_core 将数据给到协议层注册的 handlers(前文“协议层投递”一节)。大多数情况下,此 handler 是 IPv4 协议栈所注册的 ip_rcv 函数。
RPS 使能的情况下(前文“使能 RPS 场景”一节):
netif_receive_skb 将数据给到 enqueue_to_backlog。
packets 会被送到 per-CPU 的输入队列上以待后续处理。
将远端 CPU 的 NAPI 数据结构添加至该远端 CPU 的 poll_list 上,并向该 CPU 发一个 IPI,进而唤醒远端 CPU 上的软中断内核线程(如果其并未在运行的话)。
当远端 CPU 上的 ksoftirqd 内核线程运行起来后,其处理模式与上一节中的相同,不同之处是,注册进来的 poll 函数是 process_backlog,该函数会从当前(译者注:本 CPU) CPU 的输入队列收取 packets。
packets 进一步给到 __net_receive_skb_core。
__net_receive_skb_core 将数据给到系统中可能存在的 taps(前文“packet tap 投递”一节)(比如 PCAP)。
__net_receive_skb_core 将数据给到协议层注册的 handlers(前文“协议层投递”一节)。大多数情况下,此 handler 是 IPv4 协议栈所注册的 ip_rcv 函数。
8. 协议栈及用户 sockets
数据接下来要走的路径是:协议栈、netfilter、Berkeley Packet Filters,最终到达用户 socket。 虽然代码路径挺长的,但是逻辑是直白清晰的。 网络数据路径更详细地拆解见前文“协议层注册”一节。下面是 high level 的简要总结:
IPv4 协议层通过 ip_rcv 收取 packets。
会做 netfilter 以及路由优化。
目标是本机的数据,会进一步给到更 high level 的协议层,比如 UDP。
UDP 协议层通过 udp_rcv 收取 packets,并通过 udp_queue_rcv_skb 及 sock_queue_rcv 将数据入队到用户 socket 的接收 buffer 中。在入队到接收 buffer 之前,会做 Berkeley Packet Filters。
值得注意的是,netfilter 在这个过程中会被调用多次,具体位置参考前文的详细拆解(前文“协议层注册”一节)。
9. 总结
linux 网络栈极其复杂,涉及到的系统很多。如果要监控这个复杂的系统就必须得搞清楚这些系统之间是怎么交互的,以及对某一系统配置的调整,会如何影响到其他系统。本文作为前文的补充,试图把这些问题梳理的更清晰易懂一些。
审核编辑:黄飞













 工商网监
工商网监
评论