 电子发烧友App
电子发烧友App


嵌入式软件开发如果具有更好的阅读性、扩展性以及维护性,就需要考虑很多因素。今天给大家分享几个嵌入式软件设计的原则。
1 设计原则
SRP 单一职责原则 Single Responsibility Principle 每个函数或者功能块只有一个职责,只有一个原因会使其改变。
OCP 开放一封闭原则 The Open-Closed Principle 对于扩展是开放的,对于修改是封闭的。
DIP 依赖倒置原则 Dependency Inversion Principle 高层模块和低层模块应该依赖中间抽象层(即接口),细节应该依赖于抽象。
ISP 接口隔离原则 Interface Segregation Principle 接口尽量细化,同时方法尽量少,不要试图去建立功能强大接口供所有依赖它的接口去调用。
LKP 最少知道原则 Least Knowledge Principle 一个子模块应该与其它模块保持最少的了解。
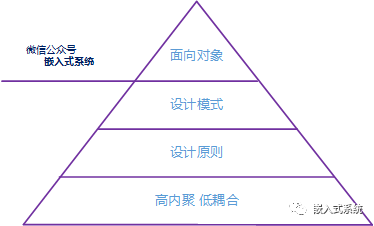
2 单一职责原则 (SRP)
函数或功能应该仅有一个引起它变化的原因。单一职责原则是最简单但又最难运用的原则,需要按职责分割大模块,如果一个子模块承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或抑制这个模块完成其他职责的能力。划分依据是影响它改变的只有一个原因,并不是单纯理解的一个模块只实现一个功能,对函数层面也是如此。
2.1 什么是职责
在 SRP 中把职责定义为“变化的原因”(a reason for change),如果有可能存在多于一个的动机去改变一个子模块,表明这个模块就具有多个职责。有时很难注意到这点,习惯以组的形式去考虑职责。例如Modem 程序接口,大多数人会认为这个接口看起来非常合理。
//interface Modem 违反 SRP void connect(); void disconnect(); void send(); void recv();
然而,该接口中却显示出两个职责。第一个职责是连接管理,第二个职责是数据通信,connect和 disconnect函数进行调制解调器的连接处理,send 和 recv函数进行数据通信。
这两个职贵应该被分开吗?这依赖于应用程序变化的方式。如果应用程序的变化会影响连接函数,如外设与主机热插拔,连接后是数据收发,则需要分开。如果是socket,其本身连接状态与数据交互是绑定的关系,应用程序的变化总是导致这两个职责同时变化,那没必分离它们,强行分割反而会引入复杂性。
2.2 分离耦合
多个职责耦合不是所希望的,但有时无法避免,有些和硬件或操作系统有关的原因,迫使把不愿耦合在起的东西耦合在一起。然而,对于应用部分来说应当尽量分离解耦。软件前期模块设计真正要做的许多内容,就是发现职责并把那些职责相互分离。
3 开放-封闭原则 (OCP)
如果期望开发的软件不会在第一版后就被抛弃,就必须牢牢地记住这点。那怎样的设计才能面对需求改变却可以保持相对稳定,从而使得系统可以在第一个版本以后不断推出新的版本呢?开放-封闭原则为我们提供了指引。
软件实体(模块、函数等)应该是可以扩展的,但是不可修改的。如果程序中的一处改动会产生连锁反应,导致相关模块的改动,那么设计就具有僵化性的臭味。OCP 建议应该对系统进行重构,这样以后对系统再进行那样的改动时,就只需要添加新的代码,而不必改动已经正常运行的代码。
3.1 特性
开放-封闭原则设计出的模块具有两个主要的特征。
对于护展是开放的 (Open for extension)
模块的行为是可以扩展的,当应用需求改变时,可以对模块进行扩展,使其满足新需求。
对于更改是封闭的(Closed for modificaiton)
模块的源代码是不能被侵犯的,不允许修改已有源代码。
两个特征看似互相矛盾,扩展模块行为的通常方式就是修改该模块的源代码,不允许修改的模块常常都被认为是具有固定的行为。怎样可能在不改动模块源代码的情况下去更改它的行为呢?关键是抽象。
3.2 抽象隔离
在 C++等面向对象设计技术时,可以创建出固定却能够描述一组任意个可能行为的抽象体,这个抽象体就是抽象基类,而这一组任意个可能的行为则表现为可能的派生类。模块可以操作抽象体,由于模块依赖于一个固定的抽象体,所以它对于更改可以是关闭的。同时通过从这个抽象体派生,也可以扩展此模块的行为。
面向对象的语言多态特性很容易实现,而嵌入式的C该如何呢?一个函数接口或功能,不要直接固化相关逻辑,而是把具体实现细节对外开放可扩展的,便于后期添加功能,且不影响其它的功能。
3.3 违反 OCP
一个应用程序需要在窗口上绘制圆形(Circle)和方形(Square),圆形和方形会被创建在同一个列表中,并保持适当的顺序,程序按顺序遍历列表并绘制所有的圆形和方形。
如果使用C语言,并采用不遵循OCP的过程化方法,一组数据结构,它的第一个成员都相同,但是其余的成员都不同。每个结构中的第一个成员都是一个用来标识该结构是代表圆或方形的类型码。DrawAllShapes 函数遍历数组,该数组的元素是指向这些数据结构的指针,根据类型码调用对应的函数 (DrawCircle 或 DrawSquare)。
typedef enum
{
CIRCLE,
SQUARE,
} ShapeType;
typedef struct
{
ShapeType itsType;
} Shape;
typedef struct
{
double x;
double y;
} Point;
typedef struct
{
ShapeType itsType;
double itsSide;
Point itsTopLeft;
} Square;
typedef struct
{
ShapeType itsType;
double itsRadius;
Point itsCenter;
} Circle;
void DrawSquare(struct Square*);
void DrawCircle(struct Circle*);
void DrawAllShapes(Shape **list, int n)
{
int i;
Shape* s;
for(i = 0; i < n; i++)
{
s = (Shape*)list[i];
switch(s->itsType)
{
case SQUARE:
DrawSquare((struct Square*)s);
break;
case CIRCLE:
DrawCircle((struct Circle*)s);
break;
}
}
}
DrawAllShapes 函数不符合 OCP,如果希望函数能够绘制包含有三角形的列表,就必须得更改这个函数,扩展switch增加三角形。事实上,每增加一种新的形状类型,都必须要更改这个函数。在这样的应用程序中增加一种新的形状类型,就意味着要找出所有包含上述 switch(或 if else 语句)的函数,在每一处都添加对新增的形状类型的判断。
在嵌入式数据流中,数据解析是常见情景,如果新手开发,可能是一个万能长函数完成全部解析功能。比如不同类型的数据解析错误样例:
typedef int int32_t;
typedef short int16_t;
typedef char int8_t;
typedef unsigned int uint32_t;
typedef unsigned short uint16_t;
typedef unsigned char uint8_t;
#define NULL ((void *)(0))
//违反OCP的样例
不同类型的数据集中在一起,使用switch-case处理,与前面DrawAllShapes一样,后续扩展会影响既有函数。
int16_t cmd_handle_body_v1(uint8_t type, uint8_t *data, uint16_t len)
{
switch(type)
{
case 0:
//handle0
break;
case 1:
//handle1
break;
default:
break;
}
return -1;
}
3.4 遵循 OCP
上面的数据解析样例调整后:
//遵守OCP原则
typedef int16_t (*cmd_handle_body)(uint8_t *data, uint16_t len);
typedef struct
{
uint8_t type;
cmd_handle_body hdlr;
} cmd_handle_table;
static int16_t cmd_handle_body_0(uint8_t *data, uint16_t len)
{
//handle0
return 0;
}
static int16_t cmd_handle_body_1(uint8_t *data, uint16_t len)
{
//handle1
return 0;
}
//扩展新指令只需要在这里加上就行,不会影响先前的
static cmd_handle_table cmd_handle_table_map[] =
{
{0, cmd_handle_body_0},
{1, cmd_handle_body_1}
};
int16_t handle_cmd_body_v2(uint8_t type, uint8_t *data, uint16_t len)
{
int16_t ret=-1;
uint16_t i = 0;
uint16_t size = sizeof(cmd_handle_table_map) / sizeof(cmd_handle_table_map[0]);
for(i = 0; i < size; i++)
{
if((type == cmd_handle_table_map[i].type) && (cmd_handle_table_map[i].hdlr != NULL))
{
ret=cmd_handle_table_map[i].hdlr(data, len);
}
}
return ret;
}
虽然不如C++抽象与多态,但整体实现了OCP的效果,在不修改handle_cmd_body_v2的情况下,扩展cmd_handle_table_map。这个模式其实是通用的表驱动法。
3.5 策略性的闭合
上面的例子其实并非是100%封闭。一般而言,无论模块是多么的“开放-封闭”,都会存在一些无法对之封闭的变化,没有对所有的情况都贴切的模型。既然不可能完全封闭,那么就必须有策略地对待这个问題。也就是说,设计人员必须对模块应该对哪种变化封闭做出选择。必须先预估最有可能发生的变化,然后构造隔离这些变化,这需要设计人员具备一些行业经验及预测能力。
遵循OCP 的代价也是昂贵的,肆无忌惮的从软件角度进行抽象隔离,创建抽象隔离要花费开发时间和代码空间,同时也增加了软件设计的复杂性。比如前面handle_cmd_body_v1比handle_cmd_body_v2,如果明确需求或者硬件资源紧缺,后者从设计原则角度更合理,但前者更直接且符合资源紧缺且需求固定的场景。对于嵌入式软件应该对程序中频繁变化的部分提取抽象。
4 依赖倒置原则 (DIP)
依赖倒置原则即高层模块(调用者)不依赖于低层模块(被调用者),二者都应该依赖于抽象。
结构化程序分析和设计,总是倾向于创建高层模块依赖低层模块,策略依赖于细节的结构,这是大部分嵌入式软件的结构,从业务层到组件层,再到驱动层,自顶向下的设计思维。良好的面向对象的程序,其依赖结构相对于传统的过程式方法设计的结构而言就是被“倒置”了。
高层模块依赖于低层模块,意味着低层模块的改动会直接影响到高层模块,从而迫使它们依次做出改动,在不同的上下文中重用高层模块就会变得困难。
4.1 倒置的接口所有权
“Don't call us,we'll call you.”(不要调用我们,我们会调用你),低层模块实现在高层模块中声明并被高层模块调用的接口,也就是低层模块按高层模块的需求来实现功能。通过这种倒置的接口所有权,满足高层在任何上下文的重用。事实上,即使是嵌入式软件,开发的重点是随时变化的高层模块,一般都是相似的上层应用软件在不同的硬件环境运行,所以高层的复用更能提高软件质量。
4.2 样例对比
假设控制熔炉调节器的软件,从外界通道中读取当前的温度,并通过向另一个通道发送命令来控制熔炉加热的开或关。按数据流的结构大概如下:
//温度调节器的调度算法 //检测到当前温度在设定范围外,开启或关闭熔炉的加热器 void temperature_regulate(int min_temp, int max_temp) { int tmp; while(1) { tmp = read_temperature();//读取温度 if(tmp < min_temp) { furnace_enable();//启动加热 } else if(tmp > max_temp) { furnace_disable();//停止加热 } wait(); } }
算法的高层意图是清楚的,但是实现代码中却夹杂着低层细节。导致这段代码(控制算法)根本不能重用于不同的硬件,只是代码很少,算法实现容易,看起来不会造成太大的损害。如果一个复杂的温度控制算法,需要移植到不同平台,或者需求改变,要求在温度异常时发出额外警示呢?
void temperature_regulate_v2(Thermometers *t,Heaterk *h,int min_temp, int max_temp)
{
int tmp;
while(1)
{
tmp = t->read();
if(tmp < min_temp)
{
h->enable();
}
else if(tmp > max_temp)
{
h->disable();
}
wait();
}
}
这就倒置了依赖关系,使得高层的调节策略不再依赖于任何温度计或者熔炉的特定细节。该算法具有较好的可重用性,算法不依赖细节。
依赖倒置尤其可以解决嵌入式软件中硬件频繁变更对软件复用带来的问题。比如运动手环的计步器,在面向过程的开发按从高到低的调用关系,如果后续因为物料等原因更换加速度传感器,则会导致上层必须修改,尤其是没有内部封装,应用层直接调用驱动接口的方式,需要逐个替换。如果后续不确定传感器可能用哪颗,软件需要根据传感器特性自动调整,则需要大量switch-case来替换。
app -> drv_pedometer_a //调用关系全部替换为 app -> drv_pedometer_b
如果采用依赖倒置,两者依赖于抽象:
app -> get_pedometer_interface //底层依赖抽象 drv_pedometer_a -> get_pedometer_interface drv_pedometer_b -> get_pedometer_interface
依赖倒置,即不同的硬件驱动均依赖抽象的接口,上层业务也依赖抽象层,所有的开发都围绕get_pedometer_interface来设计,这样硬件变化不会影响上层软件的复用。这个实现其实是通用的代理模式。
4.3 结论
使用传统的过程化程序设计所创建出来的依赖关系结构,策略是依赖于细节的,这样会使策略受到细节改变的影响。事实上,使用何种语言来编写程序是无关紧要的。即使是嵌入式C,如果程序的依赖关系是倒置的,它就是面向对象的设计思维。
依赖倒置原则是实现面向对象技术宣称的好处的基本机制,正确应用对于创建可重用的框架来说是必须的,同时它对于构建在变化面前富有弹性的代码也是非常重要的;由于抽象和细节被彼此隔离,所以代码也容易维护。
5 接口隔离原则 (ISP)
使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。面向对象开发时,继承的基类中包含本不需要的接口,原本特定需求扩展的接口成了通用,导致所有派生类都要去实现没有意义的接口,即为接口污染。
5.1 接口污染
接口隔离原则”的重点是“接口”二字,在嵌入式C层面有两种理解:
1、如果把“接口”理解为一组API接口集合,可以是某个子功能的一系列接口。如果部分接口只被部分调用者使用,就需要将这部分接口隔离出来,单独给这部分调用者使用,而不强迫其它调用者也依赖这部分本不会被用到的接口。类似购物,不需要捆绑销售,只买自己需要的。
2、如果把“接口”理解为单个API接口或函数,部分调用者只需要函数中的部分功能,可把函数拆分成粒度更细的多个函数,让调用者只依赖它需要的那个细粒度函数。即一个函数不要传入过多的参数配置,宁可拆分为多个同类接口简化调用,也不要提供一个万能的需要一些不相关参数的接口。模块对外接口不要过度封装,参数太多也不便于阅读和使用。
5.2 风险与解决
如果一个程序依赖于部分它不使用的方法,这程序就面临着由于这些未使用方法的改变所带来的变更,这无意中导致了所有相关程序之间的耦合。换种说法,如果一个客户程序依赖于它不使用的方法,但是其他客户程序却要使用这些方法,那当其他客户要求这个方法改变时,就会影响到这个客户程序。应该尽可能地避免这种耦合,分离接口。
在嵌入式C中,随着迭代升级,也会扩展新功能,或者直接为函数增加传入参数,或者函数内部增加额外的处理,导致接口产生冗余,对不同版本的调用者并不友好(如果本身是功能迭代升级没问题,避免不同版本的差异是平级关系)。更改的代价和影响就变得不可预测,并且更改所附带的风险也会增加。更改一个和自己不相关的功能也可能产生影响,表面是修改A功能却导致B功能异常,“城门失火,殃及池鱼”,这种对单元测试覆盖也难以把握。
模块层面,不相关的接口可以使用预编译宏屏蔽,这样也节省代码空间;函数层面扩展新功能时可以新建接口,重新实现和原来接口功能平级的扩展版或者v2,尽量不要通过传参合并,除非明确两者是递进关系而不是并列关系。
微信公众号【嵌入式系统】建议,子模块分多个c文件,内部函数务必加static,仅模块内部的使用全局函数可以在c内使用extern,不要加到h头文件。功能类似但应用场景不同的函数可以放在一起,且注释里互相提到对方,说明差异。更多编码规范和编码技巧可以参考《嵌入式C编码规范》、《代码的保养》。
6 最少知道原则(LKP)
迪米特法则(Law of Demeter,缩写是 LOD),也叫最小知道(知识)原则,一个功能对其依赖的子功能知道的越少越好,对于被依赖的子功能无论逻辑多么复杂,都尽量将逻辑封装在内部。通俗的解释就是,使用某个子模块,不需要关注其内部实现,调用尽可能少的API接口。
比如执行A操作需要按顺序调用1-2-3-4四个接口,执行B操作需要按顺序调用1-2-4-3四个接口,对于调用者需要清楚知道模块内细节才能正确使用,这种完全可以合并接口,封装A和B两个动作,在其内部执行具体的细节,对外隐藏封闭,外界使用时无需关注。
最少知道原则(迪米特原则)的初衷在于降低模块间的耦合,模块更好的信息隐藏和更少的信息重载,将部分信息固化封闭。但过度的封闭也有缺点,一旦客制化需求变更,如果新增C操作是4-3-2-1就需要扩展新接口。
7 重构
重构是持续进行的,好比用餐后对厨房的清理工作。第一次没有清理用餐会快一点,但是由于没有对盘碟和用餐环境进行清洁,第二天做准备工作的时间就要更长一点。这会再一次促使放弃清洁工作。的确,跳过清洁工作能够很快用餐,但是脏乱在逐渐积累。最终,得花费大量的时间去寻找合适的烹饪器具,凿去盘碟上已经干硬的食物残余,并把它们洗擦干净。饭是天天要吃的,忽略掉清洁工作并不能真正加快做饭速度,片面追求速度早晚要翻车,欲速则不达。重构的目的就是为了每天清洁代码,保持代码的清洁。
软件开发大部分是基于这种理不清的混沌状态的迭代开发,所有的原则和模式对于脏乱的代码来说将没有任何价值。在应用各种设计原则、设计模式前(《嵌入式软件的设计模式(上)》、《嵌入式软件的设计模式(下)》),首先学习编写清洁的代码。
8 随想
面向对象的设计原则还有很多,基于类的继承、封装、多态有各种通用指导规则,而这些设计原则对于嵌入式C并不完全适用。嵌入式C是结构化程序设计,自顶向下的方式,在需求多变时或多或少存在弊端,其特点是快但乱。所以重构是必不可少的,在不改变外在行为的前提下,改进代码的内部结构;但修改成什么样式才是合适的,就可以参考前面的五种规则。
现在的嵌入式软件开发极少像以前把一个字节掰成八瓣使用,资源足够的情况下,嵌入式应用开发可适当参考面向对象的方式实现高质量的软件;具体方案思路两种,函数指针,抽象隔离。“没有什么问题是不能通过增加一个抽象层解决的,如果有,再增加一层”。
审核编辑:黄飞











 工商网监
工商网监
评论