 电子发烧友App
电子发烧友App


正文
最有价值的写在最前面
内存屏障与 volatile 是高并发编程中比较常用的两个技术,无锁队列的时候就会用到这两项技术。然而这两项技术涉及比较广的基础知识,所以比较难以理解,也比较不容易解释清楚。关于内存屏障和 volatile 网上有相当多的资料,但是总感觉还是不够系统和深入。当然由于我自身水平有限,所以也不敢保证就能把这两个概念说清楚。所以在文章的开始,先列举一些我在学习过程中比较好的资料。
1.基本概念
https://blog.csdn.net/legend050709/article/details/109149321
这篇博客深入浅出的介绍了内存屏障和volatile的概念,并且列举了一些非常好的用例,可以直观感受内存屏障与volatile的作用。并且列举了 linux 内核中著名的无锁队列 kfifo 是如何使用内存屏障的。
https://blog.csdn.net/liuhhaiffeng/article/details/106493224
这篇博客讲解了 LOCK 前缀与内存屏障的关系,LOCK 是实现 CAS 操作的关键,所以弄清楚 LOCK 的作用也是非常有必要的。
《深入理解计算机系统》第三章、第四章、第六章
《深入理解计算机系统》是一本神书(本文后面都简称CSAPP),有多神相信就不用我介绍了。第三章介绍了while循环的机器指令,第四章有关于分支预测的相关知识,第六章有关于缓存的知识。
2.深入理解
《Memory Barriers: a Hardware View for Software Hackers》该文章深入浅出地讲解了MESI的基本概念,MESI 引起的缓存可见性问题,从而引出了内存屏障的作用,以及为什么要使用内存屏障。该文章非常值得一读。
这篇文章来自于《Is Parallel Programming Hard, And, If So, What Can You Do About It?》的附录C。作者:Paul E.Mckenney
该书是一本开源的书,在https://mirrors.edge.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html可以下载PDF。
该书的中文译版为《深入理解并行编程》。译者:谢宝友、鲁阳
《Memory Ordering in Modern Microprocessors》该文章和上一篇是同一个作者。该文章对上一篇中第6部分的内容进行了更加详细的说明。
3.Java volatile
在刚开始学习volatile和内存屏障的时候,在网上搜到很多的资料都是讲java实现的。volatile这个关键字在java和 CC++ 里面有非常大的区别,容易引起误会。主要区别在于,java volatile 具有缓存同步的功能,而 CC++ 没有这个功能,具体原因本文会简单讲下。详细内容参见B站马士兵老师的课程。
https://www.bilibili.com/video/BV1R7411C7rf
4.无锁队列实践
理论结合实践,关于无锁队列的实现有几篇文章值得一读:
单生产者——单消费者模型
https://blog.csdn.net/linyt/article/details/53355355
讲解kfifo的实现,kfifo是linux内核实现的无锁队列,非常具有参考价值。
多对多模型
https://coolshell.cn/articles/8239.html
多个生产者和消费者,需要用到CAS操作。
个人认为,如果把这些资料里的内容都看懂了,后面的内容其实也就可以不用看了,哈哈。好了,下面开始我个人对于内存屏障和 volatile 的一些粗浅的见解。
volatile
关于 volatile 关键字 https://www.runoob.com/w3cnote/c-volatile-keyword.html 这里有详细描述。主要是为了防止优化编译带来的一些问题。注意:volatile 只作用于编译阶段,对运行阶段没有任何影响。
1.防止直接从寄存器中获取全局变量的值
//disorder_test.c #include#include #include #define QUEUE_LEN 1 //为了测试方便 typedef struct { int m_flag; long long m_data; }QUEUENODE, LPQUEUENODE; long long goods; QUEUENODE m_queue[QUEUE_LEN]; void* Push(void* param) { long long data = *(long long*)param; int pos = data % QUEUE_LEN; while (m_queue[pos].m_flag); m_queue[pos].m_data = data; m_queue[pos].m_flag = 1; return NULL; } void* Pop(void* param) { int pos = *(long long*)param % QUEUE_LEN; while (!m_queue[pos].m_flag); goods = m_queue[pos].m_data; m_queue[pos].m_flag = 0; return NULL; } int main() { long long i = 1; memset(m_queue, 0, sizeof(m_queue)); pthread_t pit1, pit2; while (1) { pthread_create(&pit1, NULL, &Push, &i); pthread_create(&pit2, NULL, &Pop, &i); // wait for pthread stop pthread_join(pit1, NULL); pthread_join(pit2, NULL); printf("goods:%lld ", goods); i++; } }
如上面代码所示,该代码使用一个定长循环队列,实现了一个生产者-消费者模型。该代码中,只有一个生产者和一个消费者。QUEUENODE 定义了一个具体的商品。其中有两个变量,m_flag 用于标识队列中对应位置是否存在商品,m_flag 为 1 表示生产者已经生产了商品,m_flag 为 0 表示商品还未被生产。m_data 表示商品具体的值。m_queue 为一个全局的循环队列。
Push 函数向队列中放入商品,在 push 前首先判断指定位置是否存在商品,如果存在则等待(通过 while 自旋来实现),否则首先放入商品(为 m_data 赋值),再设置 m_flag 为 1。
Pop 函数用于从队列中获取商品,pop 之前先判断指定位置是否存在商品,如果不存在则等待(通过while自旋来实现),否则首先取出商品(将 m_data 赋值给 goods),再设置 m_flag 为 0。
main 函数是一个死循环,每次开启两个线程,一个线程向队列中 push 商品,一个线程从队列中 pop 线程,然后等待两个线程结束,最后打印出通过 pop 获取到的商品的值,即 goods。
OK,现在用非优化编译编译该代码,并运行:
gcc disorder_test.c -o disorder_test -lpthread ./disorder_test
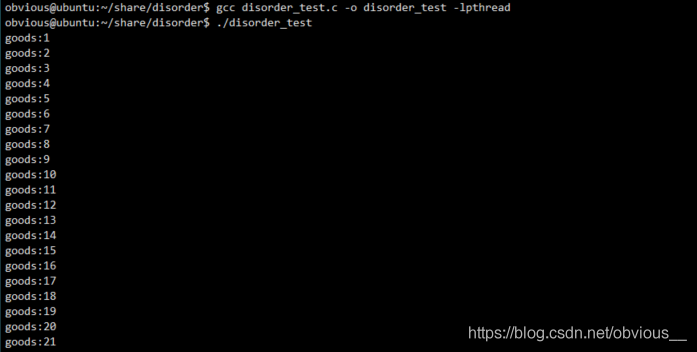
OK,看起来一切正常。
现在我们换成优化编译试试:
gcc disorder_test.c -O2 -o disorder_test -lpthread ./disorder_test

img
程序陷入了死循环…发生了什么?
现在我们来看看这段代码的汇编,首先是非优化编译版本:
gcc -S disorder_test.c cat disorder_test.s
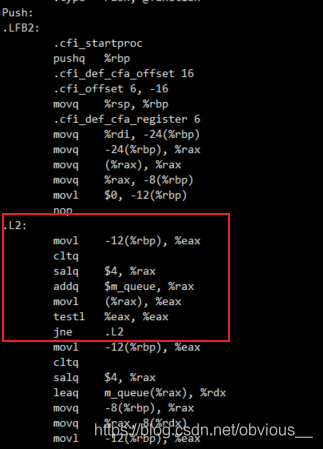
img
这里我们只标注出最关键的部分,即 push 中的 while 循环。我们注意到,while 中每次循环都会执行取值和运算操作,然后才执行 testl 判断。我们再来看看优化版本。
gcc -S -O2 disorder_test.c cat disorder_test.s
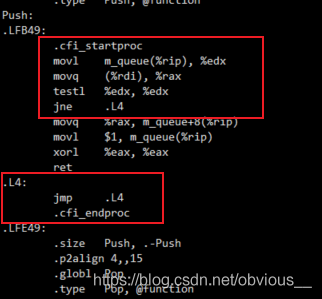
img
这里就非常可怕了,可以看到 .L4 本身就是一个死循环,前面 testl 之后如果发现不满足条件,则直接跳进死循环。这是为什么?我们来看看 push 的代码:
void* Push(void* param)
{
long long data = *(long long*)param;
int pos = data % QUEUE_LEN;
while (m_queue[pos].m_flag)
;
m_queue[pos].m_data = data;
m_queue[pos].m_flag = 1;
return NULL;
}
while循环会检测m_queue[pos].m_flag,而在这个函数中,只有当m_queue[pos].m_flag为0时,循环才会跳出,执行line7及之后的代码,而在line8才会对m_flag进行修改。所以编译器认为在循环的过程中,没人会修改m_flag。既然没有修改m_flag,只要m_flag一开始的值不为0,那么m_flag就是一个不会改变的值,当然就是死循环!显然编译器并不知道另一个线程会执行pop函数,而pop会修改m_flag的值。如果观察pop的汇编代码也会发现完全相同的优化逻辑。
所以,在这种情况下,就需要程序员显式的告诉编译器,m_flag是一个会发生改变的值,所以不要尝试做这样的优化。这就是volatile关键字。现在我们给m_flag加上volatile关键字:
typedef struct
{
volatile int m_flag;
long long m_data;
}QUEUENODE, LPQUEUENODE;
再次优化编译并运行程序:
gcc disorder_test.c -O2 -o disorder_test -lpthread ./disorder_test
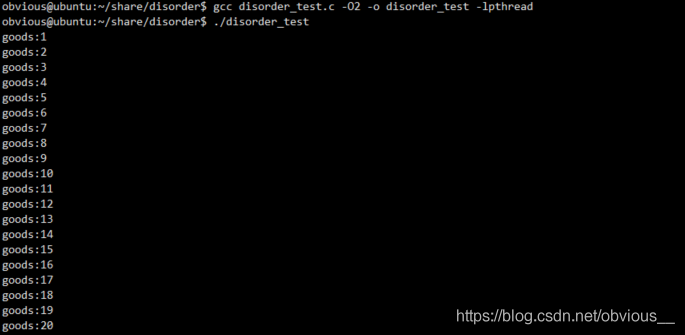
OK,一切正常!
现在我们再来看看汇编代码:
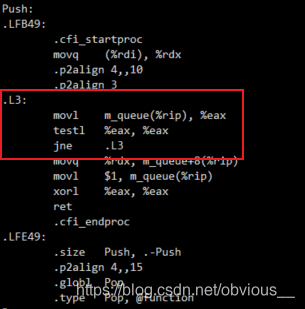
现在每次循环都会执行movl指令去获取m_flag的值!一切都变得美好了。
2.防止指令乱序
volatile 的第二个作用就是防止编译时产生的指令乱序。这个很简单,有如下代码:
//test.c
int x,y,r;
void f()
{
x = r;
y = 1;
}
void main()
{
f();
}
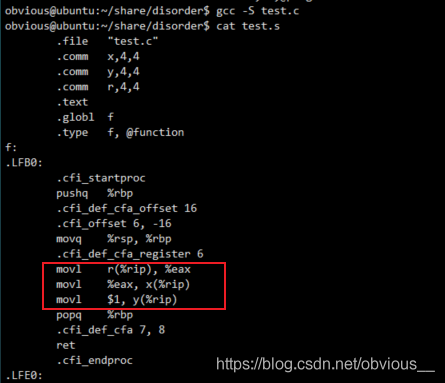
这次,我们直接对比非优化编译与优化编译的汇编代码。
非优化编译
优化编译
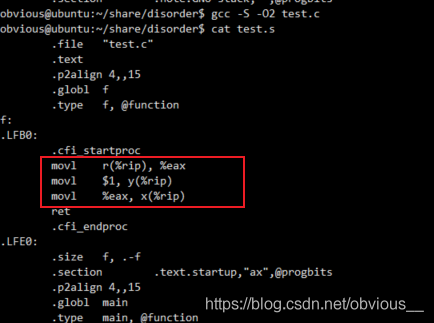
不难发现,优化编译的版本,交换了 x=r 和 y=1 的顺序,先将 y 的值赋值为 1,再将 x 值赋值为 r。现在我们将 x,y, r 加上 volatile 关键字。
volatile int x,y,r;
再次查看汇编代码:
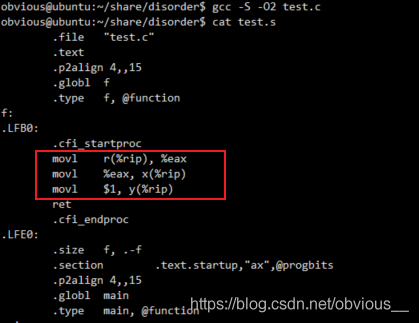
指令顺序和代码顺序一致。
在 https://www.runoob.com/w3cnote/c-volatile-keyword.html 介绍 volatile 时有这样一段描述 “当使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据”。然而,实际情况真的是每次都从内存中读取数据么?其实这只是一个笼统的说法,更为准确的说法应该是,系统不会直接从寄存器中读取 volatile 修饰的变量。因为,寄存器的读写性能远高于内存,所以在CPU寄存器和内存之前,通常有多级高速缓存。
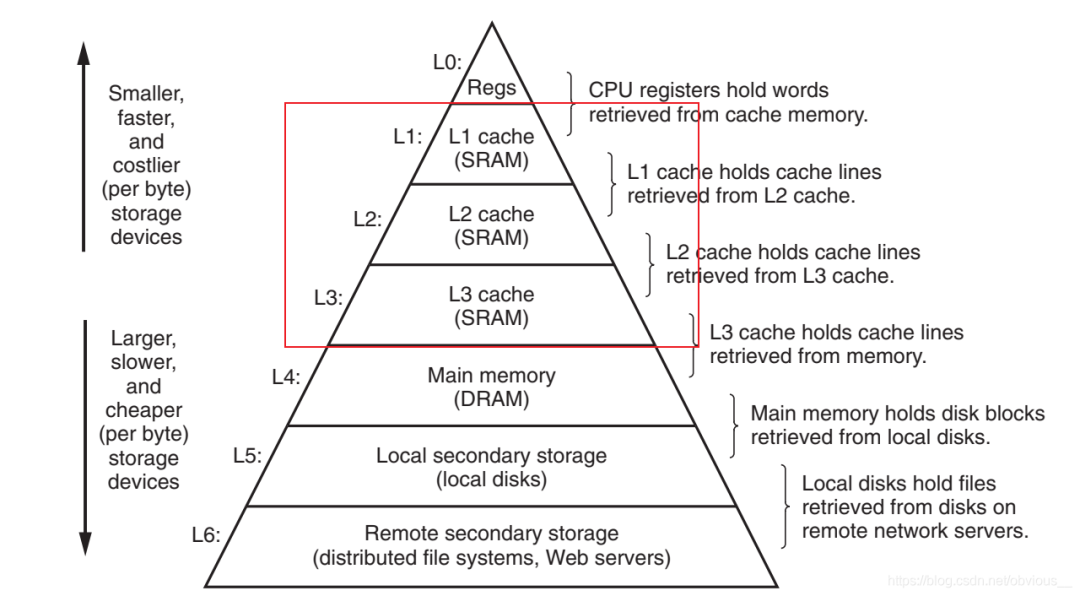
相信大家都见过这样一张著名的图,不难发现,图中,在内存与寄存器之间,存在 L1、L2、L3 这样三级缓存。所以指令在进行访存操作的时候,会首先逐级查看缓存中是否有对应的数据,如果3级缓存有没有期望的数据,才会访问内存。而通常在多核CPU中缓存是如下图所示的这样一种结构:
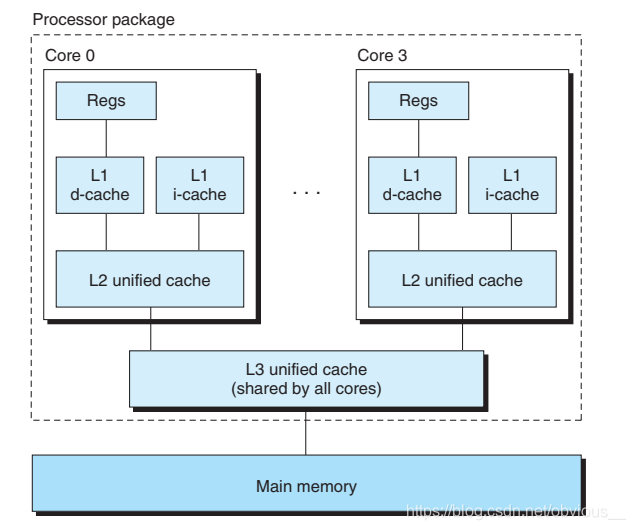
每个 CPU core 都有自己独立的 L1 和 L2 缓存,多个 core 共享一个L3缓存,多个 CPU 有各自的 L3 缓存,多个CPU 共享内存。每个 core 都有自己独立的 L1 和 L2 缓存,缓存可以独立读写!这个就可怕了,因为这就存在不同 core 读写同一份数据的可能,如果不加任何限制,岂不天下大乱了?所以对于多核 CPU,需要一种机制来对缓存中的数据进行同步。这也就是我们接下来要讲的 MESI。
MESI
MESI 在《Memory Barriers: a Hardware View for Software Hackers》一文中有非常详细的描述,这里只对一些关键问题进行阐述。在描述 MESI 之前,我们先说明两个重要的操作:
Load
Load是指CPU从Cache中加载数据。
Store
Store是指CPU将数据写回Cache。
在《Memory Barriers: a Hardware View for Software Hackers》还有一个操作叫 write back(写回),是指将Cache数据写回内存。
在 CSAPP 中,第4章讲到指令的6个阶段其中也有一个阶段叫write back,这里是指将执行阶段的结果写回到寄存器,这两个概念不要混淆了。
MESI 是指缓存行的四种状态:
I:invalid,最简单的一种状态,表示该缓存行没有数据,显然这也是缓存行的初始状态。
S:shared,该缓存行中的数据被其他CPU共享。在shared状态下,缓存行为只读,不可以修改。
E:exclusive,该缓存行中的数据没有被其他CPU共享,且缓存中的数据与内存中保持一致。在exclusive状态下,缓存行可以修改。
M:modified,该缓存行保存了唯一一份 up-to-date 的数据。即该缓存行中的数据没有被其他CPU共享,且缓存行的数据与内存不一致。
这四种状态之间是可以互相转换的,具体的转换方式在《Memory Barriers: a Hardware View for Software Hackers》一文中也有非常详细的描述(重要的是事情说三遍,这篇文章很重要!!!)。这里我们只对部分状态转换加以说明。
I to S
缓存的初始状态为I,即没有数据。当缓存行通过Read消息将数据加载进来后,其状态就变成了S。这个Read消息可以发送给其他缓存行,因为需要的数据可能在其他缓存行中,显然当前缓存行加载完数据后,该数据就被至少两个缓存行共享,状态就应该为S。还有一种可能,就是没有缓存行有这个数据,此时就需要从内存中加载该数据,加载完成后,只有当前缓存行有这个数据。这个状态看起来更像是状态E,但实际上这种情况状态依然是S。我个人猜想,这或许是为了提升Read操作的性能,因为Read并没有要修改数据的意思,所以没必要去区分Read之后数据是否真的被共享了。
S to E
我们前面说到,S状态的缓存行是只读的,如果想要修改怎么办?直接改可以么?当然不行,如果直接改那么就会出现同一份数据在不同的缓存行中值不同!这显然是不可接受的。所以如果一个CPU希望修改处于S状态的缓存行里面的数据,就需要向其他CPU发invalidate消息,收到invalidate消息的CPU需要将对应缓存行的状态改为invalid,即相应缓存行就不再持有这份数据了,改完之后需要回一个invalidate acknowledge消息。当发出invalidate消息的CPU收到所有的invalidate acknowledge后就现在这份数据有他独占了,于是将相应缓存行的状态改了为E。
不难看出由S状态转变为E状态是比较耗时的,因为需要等待所有CPU都回送invalidate acknowledge消息。
E to M
状态E到状态M的转变就非常简单了,因为缓存已经处于E也就是独占状态了,此时当前CPU就可以修改这个缓存行的值,也就是前面提到过的Store操作。Store操作之后缓存行的状态就由之前的E变为了M。
其实从MESI的规定,不难看出,MESI确保了缓存的一致性,即不会存在共享同一个数据的两个缓存行中数据值不一致。数据在修改之前总是需要等待所有共享了该数据的其他缓存行失效。然而对于CPU来讲,这样的等待是漫长且低效的。于是工程师们为了提高效率进行了一些优化,而正是这样的优化引入了缓存可见性的问题。
Store Buffer
a = 1; b = a + 1; assert(b == 2);
如上面代码所示。首先 line2 的加法运算要使用到 line1 中的变量a,所以两行代码是存在数据相关性的,那么编译器不会尝试交换指令顺序。我们假设现在变量 a 在 CPU1 中,变量 b 在 CPU0 中,且初始值均为0。假设现在 CPU0 要执行上述代码,根据前面 MESI 的规定,上述代码的执行顺序如下:
CPU0 执行 a= 1
在执行过程中,发现 a 并不在 CPU0 中,所以需要发送 read 消息读取 a 的值。而读取之后又需要修改 a 的值,就需要发送 invalidate 消息。这两个消息可以用 read invalidate 消息来代替。CUP1 在收到 read invalidate 消息后会发送相应缓存行中 a 的值,并且 invalidate 该缓存行,然后发送 invalidate acknowledge 消息。
CPU0需要等待CPU1传回的a值以及invalidate acknowledge,然后才能修改a的值,最后将对应缓存行的状态改为M。
CPU0执行b=a+1
此时a,b均在CPU0的中,所以直接执行就好。
CPU0执行assert(b == 2)
显然此时b的值一定为2。
这个流程的关键在于 CPU0 需要等待 CPU1 回传的消息,而前面说过这样的等待很耗时。
从 a = 1; 这行代码不难发现,不论 CPU1 回传给 CPU0 的值是什么,我们会将 a 的值最终修改为1,那么我们真正需要等待的只是 invalidate acknowledge。那么我们是不是可以先将 a = 1; 这条指令缓存起来,继续执行后面的操作,等收到 invalidate acknowledge 之后再来真正修改 a 的值呢?答案是肯定的,如下图所示:
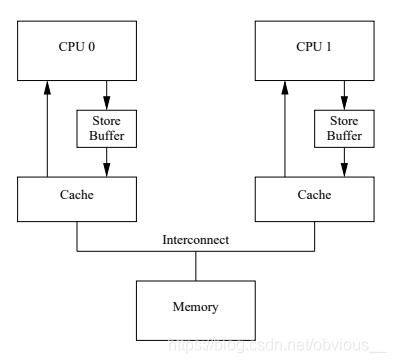
Store Buffer的问题
在 CPU 和 cache 之前,引入了一个称为 store buffer 的缓存。现在,我们在执行 a=1 时,如果需要等待 invalidate acknowledge,那么就先将 a=1 写入这个 store buffer ,然后继续执行后面的代码,等到收到 invalidate acknowledge 再将 store buffer 中的值写入缓存。好了,那么现在问题来了。有了store buffer之后,前面代码就可以是这样的一种执行顺序。
CPU0 执行a= 1
在执行过程中,发现a并不在CPU0中,所以CPU0向CPU1发送read invalidate消息。然后将a = 1写入store buffer。继续执行后面的代码。
CPU0执行b=a+1
在执行过程中,CPU0 收到了 CPU1 传回的 a 值0。CPU0 将 a 的值加载到缓存中,然后执行 a+1,于是得到了 b 的值1。此时CPU0 到了invalidate acknowledged,于是使用 store buffer 中的条目,将 cache 中 a 的值修改为1。然而已经没有什么卵用了。
CPU0执行assert(b == 2)
显然此时 b 的值一定为 1。
上述问题违反了 CPU 的 self-consistency,即每个CPU需要保证自身的操作看起来与代码顺序一致。于是对于CPU进行了改进,同一个 CPU 的 store 操作可以直接作用于后面的 load 操作。所以 CPU0 在 load a 时发现 store buffer 中 a 的正确值应该是1,于是使用这个值进行后面的运算。
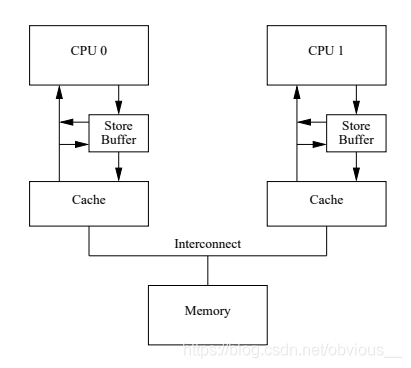
这个改进可以解决 CPU 的 self-consistency 问题,但是却解决不了 global memory ordering 问题。有如下代码:
void foo(void)
{
a = 1;
b = 1;
}
void bar(void)
{
while (b == 0)
continue;
assert(a == 1);
}
假设,a,b初始值为0。a 在CPU1中且为 exclusive 状态,b 在 CPU0 中且为 exclusive 状态,CPU0 执行 foo(),CPU1 执行 bar()。情况如下:
CPU0执行 a=1
在执行过程中发现a不在CPU0的缓存中,于是发送 read invalidate给 CPU1,然后将 a=1 写入 store buffer。继续执行。
CPU1 执行 whie(b == 0)
在执行过程中发现 b 不在 CPU1 的缓存行中,于是发送 read 给CPU0。
CPU0执行b=1
由于 b 在 CPU0 中且为独占,于是这句话直接就执行成功了。
CPU0 收到 CPU1 的 read 消息
于是将b的值1送回给CPU1,并且将缓存行状态修改为shared。
CPU1 收到 CPU0 的 read ack
于是得知 b 的值为1,从而跳出循环,继续向后执行。
CPU1执行 assert(a == 1);
注意,此时 CPU1 还未收到 read invalidate 消息。由于 a 在CPU1中依然是独占,所以 CPU1 直接从缓存中获取到 a 的值0。于是 assert 失败。(注意,a = 1 是存在于 CPU0 的 store buffer 中,而不是 CPU1。)
CPU1 收到 CPU0 的read invalidate
CPU1向CPU0传回a的值0,以及invalid ack。
CPU0收到CPU1的值以及invalid ack
CPU0 使用 store buffer 中的条目,将 cache 中 a 的值修改为1。
内存屏障
造成上述问题的核心是 a=1; 还没有被所有CPU的可见的时候,b=1; 已经被所有CPU都可见了。而 a=1 不可见的原因是 store buffer 中的数据还没有应用到缓存行中。解决这个问题可以有两种思路:
store buffer 中还有数据时暂停执行。
store buffer中还有数据时把后续的 store 操作也写入 store buffer。
这里就要用到内存屏障了。修改上述代码如下:
void foo(void)
{
a = 1;
smp_mb(); //内存屏障
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
按照思路1,CPU0 执行到 line4 时,发现 store buffer 中有 a=1,于是暂停执行,直到 store buffer 中的数据应用到cache中,再继续执行 b=1。这样便没问题了。
按照思路2,CPU0 执行到 line4 时,发现 store buffer中有 a=1,于是将该条目做一个标记(标记store buffer中的所有当前条目)。在执行b=1时,发现store buffer中有一个带标记的条目,于是将b=1也写入store buffer,这样b=1对于CPU1也就不可见了。只有当代标记的条目应用于缓存之后,后续条目才可以应用于缓存。
这相当于只有当标记条目都应用于缓存后,后续的store操作才能进行。
通过这两种方式就很好的解决了缓存可见性问题。仔细观察这个流程,其实感觉有点数据库事务的意思,哈哈,技术果然都是互通的。
不难发现,内存屏障限制了CPU的执行流程,所以同样会有一定的性能损失,但是显然不满足正确性任何性能都是扯淡。
Invalidate Queue
在使用了内存屏障之后,store buffer中就可能堆积很多条目,因为必须等到带有标记的条目应用到缓存行。store buffer的大小也是有限的,当store buffer满了之后便又会出现前面提到的性能问题。所以还有什么优化的方式么?
MESI 性能问题的核心是 Invalidate ack 耗时太长。而这个耗时长的原因是,CPU必须确保cache真的被invalidate了才会发送 Invalidate ack。而在CPU忙时显然会增加 Invalidate ack 的延迟。那么我们是不是也可以像store buffer那样把invalidate 消息缓存起来呢?这个显然也是可以的。于是,工程师们又增加了 invalidate queue 来缓存 invalidate 消息。
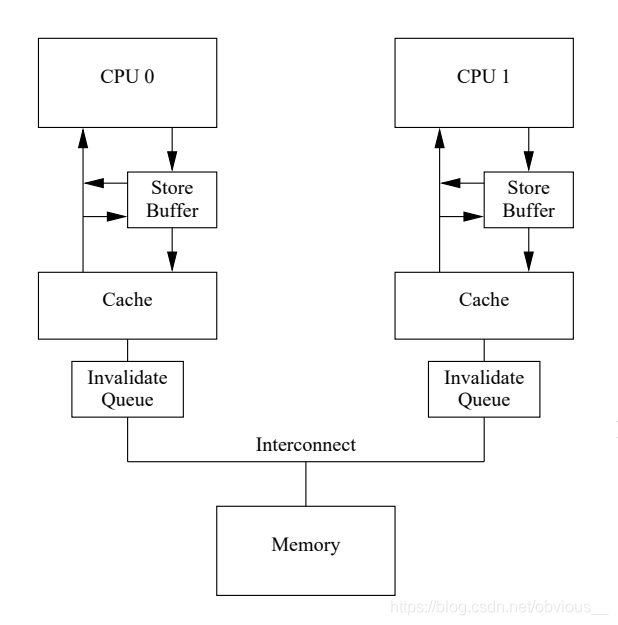
CPU收到invalidate消息后,不用真正等到 cache invalidate,只需要将 invalidate 消息存放到 Invalidatae Queue 中就可以发送 invalidate ack了。而收到 invalidate ack 的 CPU 就可以将 store buffer 中相应的条目应用到 cache。
Invalidate Queue的问题
前面store buffer的经验告诉我们,天下没有免费的午餐。Invalid Buffer的引入同样也会带来问题。我们再来看看前面的代码:
void foo(void)
{
a = 1;
smp_mb(); //内存屏障
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
假设,a,b初始值为0。a在CPU0和CPU1之前共享,状态为shared,b在CPU0中且为exclusive状态,CPU0执行foo(),CPU1执行bar()。情况如下:
CPU0执行a=1
在执行过程中发现a的状态为shared,于是发送invalidate给CPU1,然后将a=1写入store buffer。继续执行。
CPU1执行whie(b == 0)
在执行过程中发现b不在CPU1的缓存行中,于是发送read给CPU0。
CPU1收到invalidate消息
CPU1将invalidate存入invalidate queue,然后立即返回invalidate ack。
CPU0收到invalidate ack
CPU0将store buffer中的条目应用到cache上,此时a的值为1。
CPU0执行b=1;
由于b在CPU0上独占,且store buffer为空,所以直接就执行成功了。
CPU0收到CPU1的read消息
于是将b的值1送回给CPU1,并且将缓存行状态修改为shared。
CPU1收到CPU0的read ack
于是得知b的值为1,从而跳出循环,继续向后执行。
CPU1执行assert(a == 1);
注意,此时invalidate消息在invalidate queue中,所以CPU1并未对相应缓存执行ivalidate操作,所以此时原始的缓存行对于CPU1是可见的,于是获取到了a的原始值0,导致assert失败。
这个问题的核心很简单,就是在获取缓存行的时候没有检查invalidate queue。解决方法也很简单,使用内存屏障。
void foo(void)
{
a = 1;
smp_mb(); //内存屏障
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_mb(); //内存屏障
assert(a == 1);
}
使用内存屏障后,会标记store buffer中的所有当前条目,只有当所有标记的条目都应用于缓存后,后续的load操作才能进行。
When a given CPU executes a memory barrier, it marks all the entries currently in its invalidate queue, and forces any subsequent load to wait until all marked entries have been applied to the CPU’s cache.
所以在加上内存屏障之后,在执行 assert(a == 1)之前需要先将invalidate queue中的条目应用于缓存行。所以在执行 a== 1 时,CPU1 会发现 a 不在 CPU1 的缓存,从而给 CPU0 发送read消息,获得 a 的值1,最终assert(a == 1); 成功。
其实在这里内存屏障还有一个非常重要的作用,因为a==1并不一定要等 b != 0时才会执行。这又是为什么?
while (b == 0) continue;是一个条件循环,条件循环的本质是条件分支+无条件循环(IF+LOOP)。在执行条件分支时,为了更好的利用指令流水,有一种被称作分支预测的机制。所以实际执行的时候可能会假定条件分支的值为FALSE,从而提前执行 assert(a == 1);
关于while循环和指令流水可以参见CSAPP的第三、第四章。
三种内存屏障
smp_mb(); 会同时作用于store buffer和invalidate queue,所以被称为全屏障。在上述代码中,我们不难发现一个问题,foo()函数只会用到store buffer,而bar()函数只会用到invalidate queue。根据这个特点,除了全屏障之外通常还有读屏障(smp rmb())和写屏障(smp rmb())。读屏障只作用于invalidate queue,而写屏障只作用于store buffer。所以上述代码还可以修改为下面的方式:
void foo(void)
{
a = 1;
smp_wmb(); //写屏障
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_rmb(); //读屏障
assert(a == 1);
}
内存屏障的使用
什么时候需要使用内存屏障
其实,在我们日常的开发中,尤其是应用研发。我们根本就用不上内存屏障?这是为什么?
虽然内存屏障用不上,但是在并发编程里面锁的概念却无处不在!信号量、临界区等等。然而这些技术的背后都是内存屏障。道理其实很简单,种种的线程进程同步的手段,实际上都相当于锁。对于临界资源的访问,我们总是希望先上锁,再访问。所以显然,我们肯定不希望加锁后的操作由于CPU的种种优化跑到了加锁前去执行。那么这种时候自然就需要使用内存屏障。
所以,对于使用了 线程进程 同步的手段进行加锁的代码,不用担心内存屏障的问题。只有为了提高并发性采用的很多无锁设计,才需要考虑内存屏障的问题。
当然,对于单线程开发和单核CPU也不用担心内存屏障的问题。
补充:锁是如何实现的
通常情况下,锁都是基于一种叫做CAS(compare-and-swap)的操作实现的。CAS的代码如下:
static __inline__ int tas(volatile slock_t *lock) { register slock_t _res = 1; __asm__ __volatile__( " lock " " xchgb %0,%1 " : "+q"(_res), "+m"(*lock) : /* no inputs */ : "memory", "cc"); return (int) _res; }
其中:xchgb 就是实现 CAS 的指令,而在 xchgb 之前有一个 lock 前缀,这个前缀的作用是锁总线,达到的效果就是内存屏障的效果。这也就是为什么使用了锁就不用担心内存屏障的问题了。而 JAVA 对于内存屏障的底层实现其实就是用的这个lock。
参考资料:
postgresql源代码中自旋锁的实现,函数调用顺序:SpinLockAcquire > S_LOCK > s_lock > TAS_SPIN > TAS > tas
https://blog.csdn.net/liuhhaiffeng/article/details/106493224
https://www.bilibili.com/video/BV1R7411C7rf
实际案例
linux 内核的无锁队列 kfifo 就使用了内存屏障。这里主要说明 __kfifo_put() 函数和 __kfifo_get()。__kfifo_put() 用于向队列中写入数据,__kfifo_get() 用于从队列中获取数据
/**
* __kfifo_put - puts some data into the FIFO, no locking version
* @fifo: the fifo to be used.
* @buffer: the data to be added.
* @len: the length of the data to be added.
*
* This function copies at most @len bytes from the @buffer into
* the FIFO depending on the free space, and returns the number of
* bytes copied.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
* line19是读操作,line30之后是写操作(向队列中写数据),所以需要使用全屏障(隔离读和写)。
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
* line34是写操作,line44也是写操作,所以使用写屏障(隔离写和写)。
*/
smp_wmb();
fifo->in += len;
return len;
}
EXPORT_SYMBOL(__kfifo_put);
/**
* __kfifo_get - gets some data from the FIFO, no locking version
* @fifo: the fifo to be used.
* @buffer: where the data must be copied.
* @len: the size of the destination buffer.
*
* This function copies at most @len bytes from the FIFO into the
* @buffer and returns the number of copied bytes.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
* line18读操作,line29是读操作(从队列中读数据),所以需要使用读屏障(隔离读和读)。
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
* line33是读操作,line43是写操作,所以需要使用全屏障(隔离读和写)。
*/
smp_mb();
fifo->out += len;
return len;
}
EXPORT_SYMBOL(__kfifo_get);
kfifo 的详细内容,请查阅相关资料,这里不再赘述。
深入理解
我们不难发现,不论是 __kfifo_put还是 __kfifo_get 都使用了两次内存屏障。我们以 __kfifo_put 为例子来观察下这两个内存屏障,在 __kfifo_put 中,第一次使用内存屏障是 line27 的 smp_mb 第二次是 line42 的 smp_wmb。现在思考一个问题,这两个内存屏障可以省略么?为了解决这个问题,我们需要思考,如果省略了内存屏障会有什么问题?
省略 smp_mb
省略 smp_mb 会出现优化编译导致的指令乱序么?
smp_mb 位于 line19 和 line30 之间,如果省略了 smp_mb,在优化编译的情况下 line19 的代码会和 lin30 的代码交换顺序么?不会!因为这两行代码有数据相关性,line30 会使用 line19 计算出的 len 值。
省略 smp_mb 会造成缓存可见性问题么?
会!fifo->out由 __kfifo_get函数修改。如果省略smp_mb在执行line30之前,__kfifo_get对于fifo->out的修改对于__kfifo_put可能不可见。不可见会造成什么后果?在__kfifo_get中会增加fifo->out的长度,如果这个增加不可见,那么line19的len值就会小一些(相对于可见情况),也就是说可以put的数据就少一些,除此之外并没有什么其他后果。kfifo队列依然可以正常工作。
综上所述,如果省略smp_mb,会造成一些性能问题,但不会有正确性问题。
省略smp_wmb
省略smp_wmb会出现优化编译导致的指令乱序么?
smp_wmb位于line34和line44之间,如果省略了smp_wmb,在优化编译的情况下line34的代码会和lin44的代码交换顺序么?有可能!因为这两行代码没有数据相关性,是相互独立的代码。
省略smp_wmb会造成缓存可见性问题么?
会!line43对于fifo->out的修改可能比line33的memcpy更早的被其他CPU感知!这就相当于,数据都还没有拷贝进去,就告诉别人数据已经准备好,你来取吧!所以如果这个时候另一个CPU运行的__kfifo_get函数,不幸的相信了这句鬼话,就会取出之前的老数据。这个是存在正确性问题的!
综上所述,如果省略smp_wmb,会引起正确性问题。
验证
好了,我们可以验证下上面的说法。上面阐述的代码是linux新版本的kfifo。我们可以看看老版本的kfifo是如何实现的。在linux-3.0.10内核代码中,可以找到老版本的kfifo。其中最重要的两个函数是__kfifo_in(对应__kfifo_put)和__kfifo_out(对应__kfifo_get)。为了方便阅读,我将__kfifo_in中的函数调用直接展开,如下图:
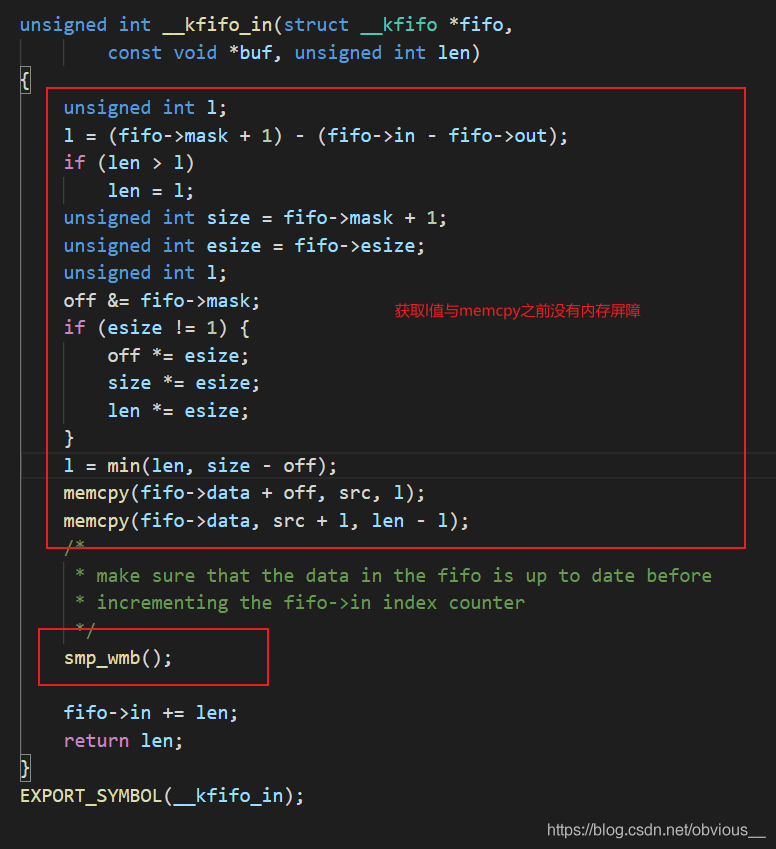
不难发现,老版的 __kfifo_in 就只使用了一个内存屏障,在 memcpy 和修改 fifo->in 之间,这也就是我们之前说的那个不可以省略的 smp_wmb。
审核编辑:黄飞










 工商网监
工商网监
评论