 电子发烧友App
电子发烧友App


1. 能用_all_gather_base的,不用all_gather
output = torch.empty(input.numel() * world_size, dtype=input.dtype, device=input.device)
torch.distributed._all_gather_base(output, input, group=xxx)
vs.
output_list = [
torch.empty(input.numel(), dtype=input.dtype, device=input.device)
for _ in range(world_size)
]
torch.distributed.all_gather(output_list, input, group=xxx)
output = torch.cat(output_list, dim=0)
内存碎片更少,操作更少,性能/内存均有收益!
2. 能用专有算子的,不用通用算子
如 F.embedding vs. Index-select
Megatron-LM master实现使用的Index-select算子,Index-select会涉及索引展开、内存复用等HostCPU逻辑,效率较低
3. 对于生命周期较长的Tensors,可以共用contiguous buffer
data = torch.zeros(global_size, dtype=xx, device=xx)
start_idx = 0
for i in range(len(item_list)):
item_list[i] = data[start_idx:start_idx+item_list[i].numel()].view(item_list[i].shape)
torch.cuda.empty_cache() # 清空原始已释放的item list数据
CUDA内存池是对齐分配的,使用分散的block会带来内存碎片,同时对于相同操作,可以直接对contiguous buffer进行操作,减少了更多的算子下发,大块计算效率也会更高。
4. 尽可能使用异步通信,提高计算/通信overlap
comm_handle = torch.distributed.all_reduce(data, group=xxx, async_op=True)
。.. # 省略若干计算代码
comm_handle.wait()
对应中间的计算就能够跟通信进行overlap,只要我们提前梳理好网络拓扑,完全是没问题的。
5. 对于输入数据size频繁变化的场景,使用Expandable Segments
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
跟cudaMalloc直接分配Kernel可访问的内存地址不同,该机制操作的是虚拟内存空间(对应的物理内存地址不具备访问权限),可以通过驱动map更多的物理内存在已分配的block的后面,从而使得segments可向上扩展,一定程度上提高了cache match的效率,减少内存碎片。
6. 在适当时机清空缓存可以大幅降低内存占用
torch.cuda.empty_cache()
在训练任务初始化时,经常会创建一些临时的设备Tensors,如果在训练任务开始时不及时清理,会造成内存池碎片化,最终导致内存占用增加。
训练过程中,禁止使用torch.cuda.empty_cache(),除非切换不同任务(如train/eval切换),因为cache blocks释放会触发Stream Synchronize,开销较大。
7. non-blocking H2D拷贝是安全的,可以无脑使用
data = data.cuda(non_blocking=True)
在后续对当前数据有依赖的地方会主动插入sync point,保证数据安全;在没有立即对数据产生依赖的场景,可以使得数据H2D拷贝和计算并行。
8. 在CPU负载比较空的时候,还是要充分利用的
如数据加载的时候可以尽量将部分操作放在CPU负载。当前Megatron master主干在这一块还是很有优化空间的。
https://zhuanlan.zhihu.com/p/670569490
但是尽量不要在网络中间插入to cpu操作,会触发同步,反而弄巧成拙。
9. 加速通信算子内存释放,可以无脑使用
10. 训练/推理过程中不要触及内存上限
如果内存观测是在持续上下跳动,那就是触及了内存上限,虽然整体程序能正常run起来,这时候已经频繁触发了内存池回收,每一次block回收都会触发一次Stream Synchronize,虽然平均利用率看起来可能超过90%,但是整体性能会降低的非常多。
11. 对于连续的ElementWise算子,可以使用NvFuser加速
@torch.jit.script
def bias_dropout_add(x_with_bias, residual, prob, training):
x, bias = x_with_bias # unpack
x = x + bias
out = torch.nn.functional.dropout(x, p=prob, training=training)
out = residual + out
return out
torch._C._jit_set_nvfuser_enabled(True)
前反向过程可以通过NvFuser实时生成高效的融合Kernel,但是注意torch.jit.script装饰器下的所有操作必须能被TorchScript语法解释,不然还是不能work的(具体可以去看PyTorch官方文档的TorchScript语法介绍)。
12. 模型运行过程中不要流同步阻塞算子下发
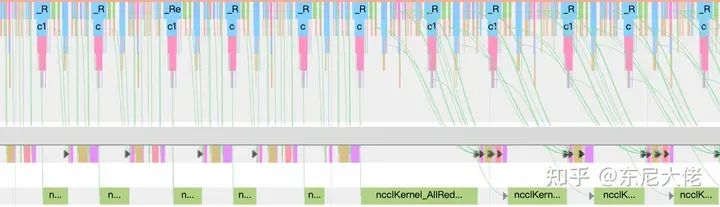
D2H操作、内存回收、以及主动调用流同步(torch.cuda.synchronize())等都会阻塞算子下发(保证对应Stream清空),那么后续算子如果执行过快(比下发快),那就会造成GPU间隙,所以说这个下发越快越好、越多越好,上图这个曲线是越缓越好,下发即执行那就是性能随时都可能坑。
13. 尽量使用TensorCore,避免使用CUDACore
# 直接使用cumsum
b = a.cumsum(dim=-1)
# 使用矩阵计算替代
a = torch.matmul(a.view(x, b, s), triu_matrix)
c = a[:, :-1, -1].cumsum(-1)
a[:, 1:, :].add_(c.unsqueeze(-1))
a = a.view(x, b*s)
上图的计算如果替换成矩阵计算,加速数十倍,在cumsum维度过高的情况下,开销是异常大的。所以在遇到类似场景,都尽量转换成矩阵计算,即使计算量增加很多,速度还是有巨大收益的。
14. 集群通信需要寻找合适的bucket size
对于分桶通信,最优bucket size往往跟集群规模相关,需要自适应修改,并不一定是越小越好,不然训练性能损失惨重。
审核编辑:黄飞









 工商网监
工商网监
评论