 电子发烧友App
电子发烧友App


将序列分解为单独的变量
问题:现在有一个包含 N 个元素的元组或者是序列,怎样将它里面的值解压后同时赋值给 N 个变量?
解答:任何的序列(或者是可迭代对象)可以通过一个简单的赋值操作来分解为单独的变量。 唯一的要求就是变量的总数和结构必须与序列相吻合。
代码示例:(当前环境为python3.8版本)
1p = (1, 2)
2x, y = p
3
4x # 1
5y # 2
6
7data = [ 'ABC', 20, 51.1, (2023, 2, 5) ]
8name, age, price, date = data
9name # 'ABC'
10date # (2023, 2, 5)
解压可迭代对象赋值给多个变量
问:如果一个可迭代对象的元素个数超过变量个数时,会抛出一个 ValueError。 那么怎样才能从这个可迭代对象中解压出 N 个元素出来?
解答:Python 的星号表达式可以用来解决这个问题。比如,你在学习一门课程,在学期末的时候, 你想统计下家庭作业的平均成绩,但是排除掉第一个和最后一个分数。如果只有四个分数,你可能就直接去简单的手动赋值, 但如果有 24 个呢?这时候星号表达式就派上用场了。
1def drop_first_last(grades):
2 first, *middle, last = grades
3 return avg(middle)
另外一种情况,假设你现在有一些用户的记录列表,每条记录包含一个名字、邮件,接着就是不确定数量的电话号码。 你可以像下面这样分解这些记录:
1record = ('Dave', 'dave@example.com', '773-555-1212', '847-555-1212')
2name, email, *phone_numbers = record
3name # 'Dave'
4email # 'dave@example.com'
5phone_numbers # ['773-555-1212', '847-555-1212']
值得注意的是上面解压出的 phone_numbers 变量永远都是列表类型,不管解压的电话号码数量是多少(包括 0 个)。
查找最大或最小的 N 个元素
问题:怎样从一个集合中获得最大或者最小的 N 个元素列表?
解答:heapq 模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。
1import heapq
2nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
3print(heapq.nlargest(3, nums)) # Prints [42, 37, 23]
4print(heapq.nsmallest(3, nums)) # Prints [-4, 1, 2]
两个函数都能接受一个关键字参数,用于更复杂的数据结构中:
1portfolio = [
2 {'name': 'IBM', 'shares': 100, 'price': 91.1},
3 {'name': 'AAPL', 'shares': 50, 'price': 543.22},
4 {'name': 'FB', 'shares': 200, 'price': 21.09},
5 {'name': 'HPQ', 'shares': 35, 'price': 31.75},
6 {'name': 'YHOO', 'shares': 45, 'price': 16.35},
7 {'name': 'ACME', 'shares': 75, 'price': 115.65}
8]
9cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
10cheap
11# [{'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'FB', 'shares': 200, 'price': 21.09},{'name': 'HPQ', 'shares': 35, 'price': 31.75}]
12expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
13expensive
14# [{'name': 'AAPL', 'shares': 50, 'price': 543.22},{'name': 'ACME', 'shares': 75, 'price': 115.65}, {'name': 'IBM', 'shares': 100, 'price': 91.1}]
字典的运算
问题:怎样在数据字典中执行一些计算操作(比如求最小值、最大值、排序等等)?
解答:考虑下面的股票名和价格映射字典
1prices = {
2 'ACME': 45.23,
3 'AAPL': 612.78,
4 'IBM': 205.55,
5 'HPQ': 37.20,
6 'FB': 10.75
7}
为了对字典值执行计算操作,通常需要使用 zip() 函数先将键和值反转过来。 比如,下面是查找最小和最大股票价格和股票值的代码:
1min_price = min(zip(prices.values(), prices.keys()))
2# min_price is (10.75, 'FB')
3max_price = max(zip(prices.values(), prices.keys()))
4# max_price is (612.78, 'AAPL')
类似的,可以使用 zip() 和 sorted() 函数来排列字典数据:
1prices_sorted = sorted(zip(prices.values(), prices.keys()))
2# prices_sorted is [(10.75, 'FB'), (37.2, 'HPQ'),
3# (45.23, 'ACME'), (205.55, 'IBM'),
4# (612.78, 'AAPL')]
执行这些计算的时候,需要注意的是 zip() 函数创建的是一个只能访问一次的迭代器。 比如,下面的代码就会产生错误:
1prices_and_names = zip(prices.values(), prices.keys())
2print(min(prices_and_names)) # (10.75, 'FB')
3print(max(prices_and_names)) # ValueError: max() arg is an empty sequence
查找两字典的相同点
问题:怎样在两个字典中寻找相同点(比如相同的键、相同的值等等)?
解答:考虑下面两个字典
1a = {
2 'x' : 1,
3 'y' : 2,
4 'z' : 3
5}
6
7b = {
8 'w' : 10,
9 'x' : 11,
10 'y' : 2
11}
为了寻找两个字典的相同点,可以简单的在两字典的 keys() 或者 items() 方法返回结果上执行集合操作。比如:
1# Find keys in common
2a.keys() & b.keys() # { 'x', 'y' }
3# Find keys in a that are not in b
4a.keys() - b.keys() # { 'z' }
5# Find (key,value) pairs in common
6a.items() & b.items() # { ('y', 2) }
这些操作也可以用于修改或者过滤字典元素。 比如,假如你想以现有字典构造一个排除几个指定键的新字典。 下面利用字典推导来实现这样的需求:
1# Make a new dictionary with certain keys removed
2c = {key:a[key] for key in a.keys() - {'z', 'w'}}
3# c is {'x': 1, 'y': 2}
序列中出现次数最多的元素
问题:怎样找出一个序列中出现次数最多的元素呢?
解答:collections.Counter 类就是专门为这类问题而设计的, 它甚至有一个有用的 most_common() 方法直接给了你答案。
先假设你有一个单词列表并且想找出哪个单词出现频率最高。你可以这样做:
1words = [
2 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
3 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
4 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
5 'my', 'eyes', "you're", 'under'
6]
7from collections import Counter
8word_counts = Counter(words)
9# 出现频率最高的3个单词
10top_three = word_counts.most_common(3)
11print(top_three)
12# Outputs [('eyes', 8), ('the', 5), ('look', 4)]
通过某个字段将记录分组
问题:你有一个字典或者实例的序列,然后你想根据某个特定的字段比如 date 来分组迭代访问。
解答:itertools.groupby() 函数对于这样的数据分组操作非常实用。 假设你已经有了下列的字典列表:
1rows = [
2 {'address': '5412 N CLARK', 'date': '07/01/2012'},
3 {'address': '5148 N CLARK', 'date': '07/04/2012'},
4 {'address': '5800 E 58TH', 'date': '07/02/2012'},
5 {'address': '2122 N CLARK', 'date': '07/03/2012'},
6 {'address': '5645 N RAVENSWOOD', 'date': '07/02/2012'},
7 {'address': '1060 W ADDISON', 'date': '07/02/2012'},
8 {'address': '4801 N BROADWAY', 'date': '07/01/2012'},
9 {'address': '1039 W GRANVILLE', 'date': '07/04/2012'},
10]
现在假设你想在按 date 分组后的数据块上进行迭代。为了这样做,你首先需要按照指定的字段(这里就是date)排序, 然后调用 itertools.groupby() 函数:
1from operator import itemgetter
2from itertools import groupby
3
4# Sort by the desired field first
5rows.sort(key=itemgetter('date'))
6# Iterate in groups
7for date, items in groupby(rows, key=itemgetter('date')):
8 print(date)
9 for i in items:
10 print(' ', i)
运行结果:
107/01/2012
2 {'date': '07/01/2012', 'address': '5412 N CLARK'}
3 {'date': '07/01/2012', 'address': '4801 N BROADWAY'}
407/02/2012
5 {'date': '07/02/2012', 'address': '5800 E 58TH'}
6 {'date': '07/02/2012', 'address': '5645 N RAVENSWOOD'}
7 {'date': '07/02/2012', 'address': '1060 W ADDISON'}
807/03/2012
9 {'date': '07/03/2012', 'address': '2122 N CLARK'}
1007/04/2012
11 {'date': '07/04/2012', 'address': '5148 N CLARK'}
12 {'date': '07/04/2012', 'address': '1039 W GRANVILLE'}
过滤序列元素
问题:你有一个数据序列,想利用一些规则从中提取出需要的值或者是缩短序列。
解答:最简单的过滤序列元素的方法就是使用列表推导。比如:
1mylist = [1, 4, -5, 10, -7, 2, 3, -1]
2[n for n in mylist if n > 0]
3# [1, 4, 10, 2, 3]
4[n for n in mylist if n < 0]
5# [-5, -7, -1]
有时候,过滤规则比较复杂,不能简单的在列表推导或者生成器表达式中表达出来。 比如,假设过滤的时候需要处理一些异常或者其他复杂情况。这时候你可以将过滤代码放到一个函数中, 然后使用内建的 filter() 函数。示例如下:
1values = ['1', '2', '-3', '-', '4', 'N/A', '5']
2def is_int(val):
3 try:
4 x = int(val)
5 return True
6 except ValueError:
7 return False
8ivals = list(filter(is_int, values))
9print(ivals)
10# Outputs ['1', '2', '-3', '4', '5']
filter() 函数创建了一个迭代器,因此如果你想得到一个列表的话,就得像示例那样使用 list() 去转换。
转换并同时计算数据
问题:你需要在数据序列上执行聚集函数(比如 sum() , min() , max()), 但是首先你需要先转换或者过滤数据
解答:一个非常优雅的方式去结合数据计算与转换就是使用一个生成器表达式参数。 比如,如果你想计算平方和,可以像下面这样做:
1nums = [1, 2, 3, 4, 5]
2s = sum(x * x for x in nums)
下面是更多的例子:
1# Determine if any .py files exist in a directory
2import os
3files = os.listdir('dirname')
4if any(name.endswith('.py') for name in files):
5 print('There be python!')
6else:
7 print('Sorry, no python.')
8# Output a tuple as CSV
9s = ('ACME', 50, 123.45)
10print(','.join(str(x) for x in s))
11# Data reduction across fields of a data structure
12portfolio = [
13 {'name':'GOOG', 'shares': 50},
14 {'name':'YHOO', 'shares': 75},
15 {'name':'AOL', 'shares': 20},
16 {'name':'SCOX', 'shares': 65}
17]
18min_shares = min(s['shares'] for s in portfolio)
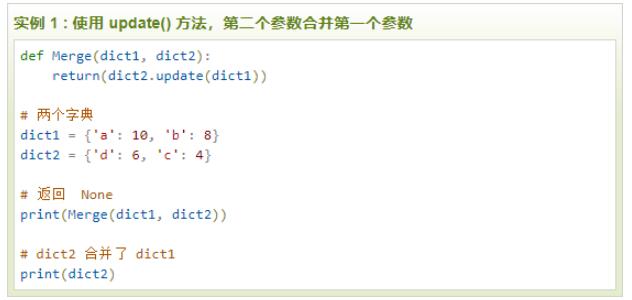
合并多个字典或映射
问题:现在有多个字典或者映射,你想将它们从逻辑上合并为一个单一的映射后执行某些操作, 比如查找值或者检查某些键是否存在。
解答:假如你有如下两个字典
1a = {'x': 1, 'z': 3 }
2b = {'y': 2, 'z': 4 }
现在假设你必须在两个字典中执行查找操作(比如先从 a 中找,如果找不到再在 b 中找)。 一个非常简单的解决方案就是使用 collections 模块中的 ChainMap 类。比如:
1from collections import ChainMap
2c = ChainMap(a,b)
3print(c['x']) # Outputs 1 (from a)
4print(c['y']) # Outputs 2 (from b)
5print(c['z']) # Outputs 3 (from a)











 工商网监
工商网监
评论