 电子发烧友App
电子发烧友App


遇到网络故障的时候,你一般会最先使用哪条命令进行排障?
除了Ping,还有Traceroute、Show、Telnet又或是Clear、Debug等等。
今天安排的,是Traceroute排障命令详解,给你分享3个经典排障案例哈。
01
Traceroute原理和功能
Traceroute是为了探测源节点到目的节点之间数据报文所经过的路径。
利用IP报文的TTL域在每经过一个路由器的转发后减一,当TTL=0时则向源节点报告TTL超时这个的特性。
Traceroute首先发送一个TTL为1的Icmp request报文,因此第一跳发送回一个ICMP错误消息以指明此数据报不能被发送(因为TTL超时)。
之后Traceroute再发送一个TTL为2的报文,同样第二跳返回TTL超时,这个过程不断进行,直到到达目的地。
此时,由于数据报中使用了无效的端口号(缺省为33434),目的主机会返回一个ICMP的目的地不可达消息,表明该Traceroute操作结束。
Traceroute记录下每一个ICMP TTL超时消息的源地址,从而提供给用户报文到达目的地所经过的网关IP地址。
Traceroute 命令用于测试数据报文从发送主机到目的地所经过的网关。
主要用于检查网络连接是否可达,以及分析网络什么地方发生了故障。
02
不同平台的Traceroute命令
01 RGNOS平台的Traceroute命令
举个例子,在锐捷RG系列路由器上,Traceroute命令的格式如下:
Traceroute host 『destination』
例如:查看到目的主机10.15.50.1 中间所经过的网关。
RG# traceroute 10.15.50.1 Type esc/CTRL^c/CTRL^z/q to abort. traceroute 192.168.0.1 ...... 1 10.110.40.1
1 4 ms 5 ms 5 ms 2 10.110.0.64
10 ms 5 ms 5 ms 3 10.110.7.254
10 ms 5 ms 5 ms 4 10.3.0.177
175 ms 160 ms 145 ms 5 129.9.181.254
185 ms 210 ms 260 ms 6 10.15.50.1
230 ms 185 ms 220 ms Trace complete successfully.
02 Windows平台的Tracert 命令
在PC机上或Windwos为平台的服务器上,Tracert命令的格式如下:
tracert [ -d ] [ -h maximum_hops ] [ -j host-list ] [ -w timeout ] host
-d :不解析主机名。
-h:指定最大TTL大小。
-j:设定松散源地址路由列表。
-w:用于设置UDP报文的超时时间,单位毫秒;例如:查看到目的主机10.15.50.1 中间所经过的前两个网关。
:>tracert -h 2 10.15.50.1 Tracing route to 10.15.50.1 over a maximum of 2 hops: 1 3 ms 2 ms 2 ms 10.110.40.1 2 5 ms 3 ms 2 ms 10.110.0.64 Trace complete.
03
使用Traceroute命令进行故障排除
排障案例① 使用Traceroute命令定位不当的网络配置点
1、现象描述:
组网情况如下图所示:
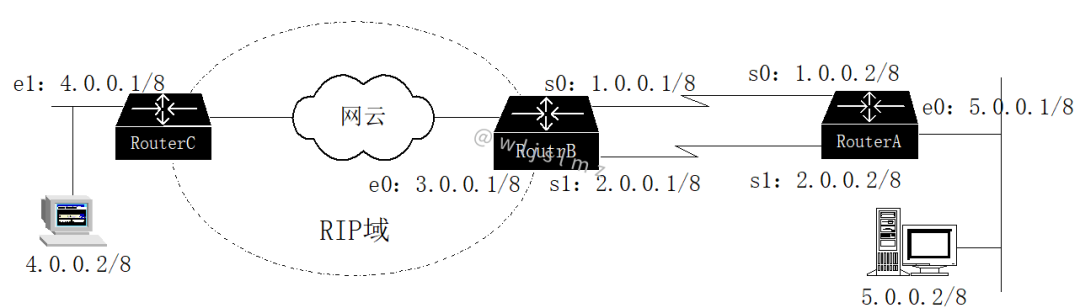
某校园网中,RouterB和RouterC同属于一个运行RIPv2路由协议的网络,主机4.0.0.2访问数据库服务器5.0.0.2,用户抱怨访问性能差。
2、相关信息:
在主机上ping 5.0.0.2显示如下:
C:Documents and Settingsc>ping -n 10 -l 1000 5.0.0.2 Pinging 5.0.0.2 with 1000 bytes of data: Reply from 5.0.0.2: bytes=1000 time=552ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=5735ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=551ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=5734ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=549ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=5634ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=555ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=5738ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=455ms TTL=250 Reply from 5.0.0.2: bytes=1000 time=5811ms TTL=250
3、原因分析:
上面的Ping显示出一个规律,奇数报文的返回时长短,而偶数报文返回时长很长(是奇数报文的10倍多)。
可以初步判断奇数报文和偶数报文是通过不同的路径传输的。
现在我们需要使用Traceroute命令来追踪这不同的路径。在RouterC上,Traceroute远端RouterA的以太网接口5.0.0.1。
RouterC(config)#traceroute
Target IP address or host: 5.0.0.1 Maximum number of hops to search for target [30]:10 Repeat count for each echo[3]:8 Wait timeout milliseconds for each reply [2000]: Type esc/CTRL^c/CTRL^z/q to abort. traceroute 5.0.0.1 ...... 1 6 ms 4 ms 4 ms 4 ms 4 ms 4 ms 4 ms 4 ms 4.0.0.1 。。。。。。(中间省略) 5 20 ms 16 ms 15 ms 16 ms 16 ms 16 ms 16 ms 16 ms 3.0.0.2 6 30 ms 278 ms 25 ms 279 ms 25 ms 278 ms 25 ms 277 ms 5.0.0.1 RouterC(config)#
从上面的显示可看到,直至3.0.0.2,UDP探测报文的返回时长都基本一。
而到5.0.0.1时,则发生明显变化,呈现奇数报文时长短,偶数报文时长长的现象。
于是判断,问题发生在RouterB和RouterA之间。
通过询问该段网络的管理员,得知这两路由器间有一主一备两串行链路,主链路为2.048Mbps(s0口之间),备份链路为128Kbps(s1口之间)。
网络管理员在此两路由器间配置了静态路由。
RouterB上如下配置:
RouterB(config)# ip route 5.0.0.0 255.0.0.0 1.0.0.2 RouterB(config)# ip route 5.0.0.0 255.0.0.0 2.0.0.2
RouterA上如下配置:
outerA(config)# ip route 0.0.0.0 0.0.0.0 1.0.0.1 RouterA(config)# ip route 0.0.0.0 0.0.0.0 2.0.0.1
于是问题就清楚了。
例如RouterB,由于管理员配置时没有给出静态路由的优先级,这两条路由项的管理距离就同为缺省值1。
然后就同时出现在路由表中,实现的是负载分担,而不能达到主备的目的。
4、处理过程:
可以有两种处理方法。
一个是,继续使用静态路由,进行配置更改 RouterB上进行如下更改:
RouterB(config)# ip route 5.0.0.0 255.0.0.0 1.0.0.2 (主链路仍使用缺省1)
RouterB(config)# ip route 5.0.0.0 255.0.0.0 2.0.0.2 100(备份链路的降低至100)
RouterA上进行如下更改:
RouterA(config)# ip route 0.0.0.0 0.0.0.0 1.0.0.1
RouterA(config)# ip route 0.0.0.0 0.0.0.0 2.0.0.1 100
这样,只有当主链路发生故障,备份链路的路由项才会出线在路由表中,从而接替主链路完成报文转发,实现主备目的。
第二个是,在两路由器上运行动态路由协议,如OSPF,但不要运行RIP协议(因为RIP协议是仅以hop作为Metric的)。
5、建议和总结:
本案例的目的不是为了解释网络配置问题,而是用来展示Ping命令和Traceroute命令的相互配合来找到网络问题的发生点。
尤其在一个大的组网环境中,维护人员可能无法沿着路径逐机排查,此时,能够迅速定位出发生问题的线路或路由器就非常重要了。
排障案例② 使用Traceroute命令发现路由环路
1、现象描述:
组网情况如下图所示:
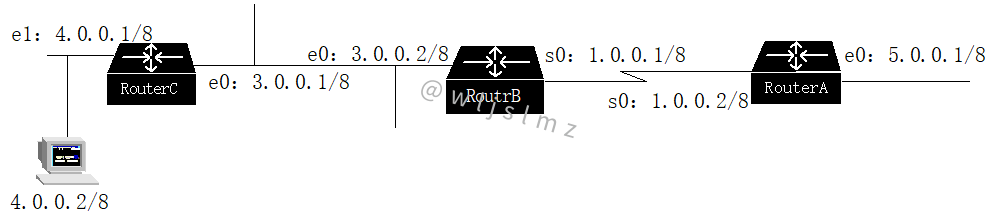
三台路由器均配置静态路由,完成后,登录到RouterA上Ping主机4.0.0.2,发现不通。
2、相关信息:
RouterA# ping 4.0.0.2
Sending 5, 100-byte ICMP Echos to 4.0.0.2, timeout is 2000 milliseconds. ..... Success rate is 0 percent (0/5) RouterA# traceroute 4.0.0.2 Type esc/CTRL^c/CTRL^z/q to abort. traceroute 4.0.0.2 ...... 1 6 ms 4 ms 4 ms 1.0.0.1(RouterB) 2 8 ms 8 ms 8 ms 1.0.0.2(RouterA) 3 12 ms 12 ms 12 ms 1.0.0.1(RouterB) 4 16 ms 16 ms 16 ms 1.0.0.2(RouterA) 。。。。。。
3、原因分析:
从上面的Traceroute命令的显示可以立即发现,在RouterA和RouterB间产生了路由环路。
由于是配置的是静态路由,基本可以断定是RouterA或RouterB的静态路由配置错误。
检查RouterA的路由表,配置的是缺省静态路由:ip route 0.0.0.0 0.0.0.0 1.0.0.1,没有问题。
检查RouterB的路由表,配置到4.0.0.0网络的静态路由为:ip route 4.0.0.0 255.0.0.0 1.0.0.2――下一跳配置的是1.0.0.2,而不是3.0.0.1。这正是错误所在。
4、处理过程:
修改RouterB的配置如下:
RouterB(config)# no ip route 4.0.0.0 255.0.0.0 1.0.0.2
RouterB(config)# ip route 4.0.0.0 255.0.0.0 3.0.0.1
故障排除。
5、建议和总结:
Traceroute命令能够很容易发现路由环路等潜在问题。
当路由器A认为路由器B知道到达目的地的路径,而路由器B也认为路由器A知道目的地时,就是路由环路发生了。
使用Ping命令只能知道接收端出现超时错误,而Traceroute能够立即发现环路所在――如果Traceroute命令两次或者多次显示同样的接口。
当通过Traceroute发现路由环路后,如果配置为:
静态路由:几乎可以肯定是手工配置有问题,如本案例所示。
OSPF协议:可能是地址聚合产生的问题。
多路由协议:可能是路由引入产生的问题。
编辑:黄飞









 工商网监
工商网监
评论