 电子发烧友App
电子发烧友App


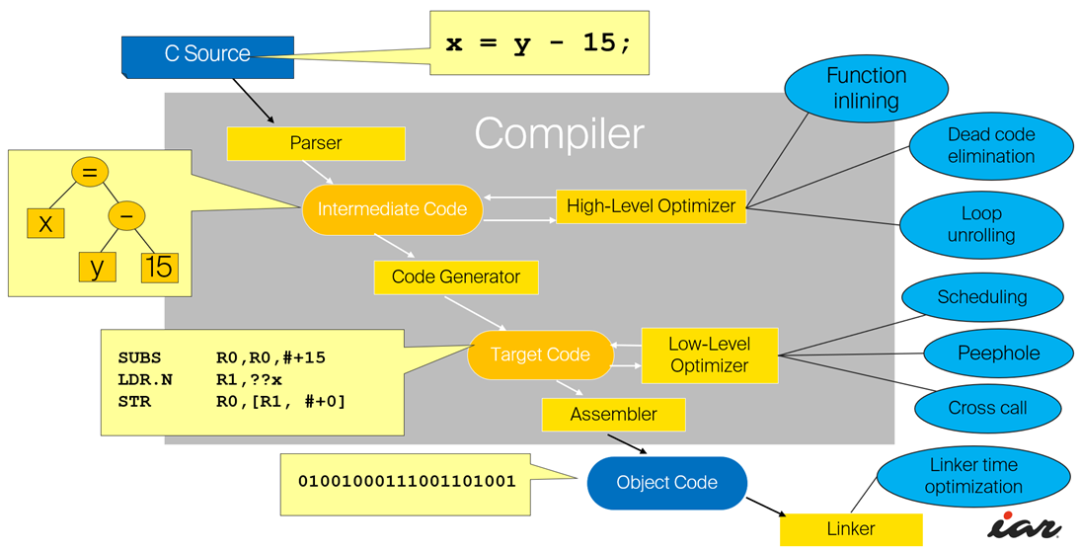
学过编译原理课程的同学应该有体会,各种文法、各种词法语法分析算法,非常消磨人的耐心和兴致;中间代码生成和优化,其实在很多应用场景下并不重要(当然这一块对于“编译原理”很重要);语义分析要处理很多很多细节,特别对于比较复杂的语言;最后的指令生成,可能需要读各种手册,也比较枯燥。
我觉得对普通的程序员来说,编译原理里面有实际用途的,是parser和codegen,但是因为这两个领域,到了2016年都没什么好研究的了,而且也被搞PLT的人所鄙视,所以你们看到的那些经典的教材,都没有好好讲。
一、 编译程序
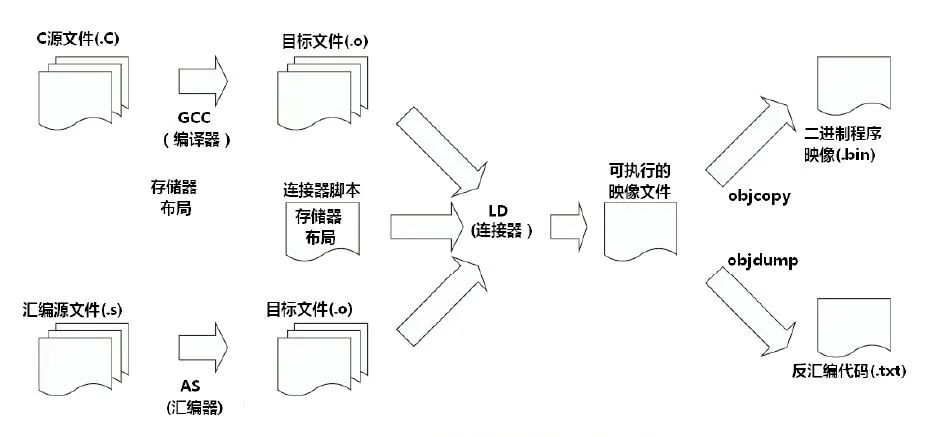
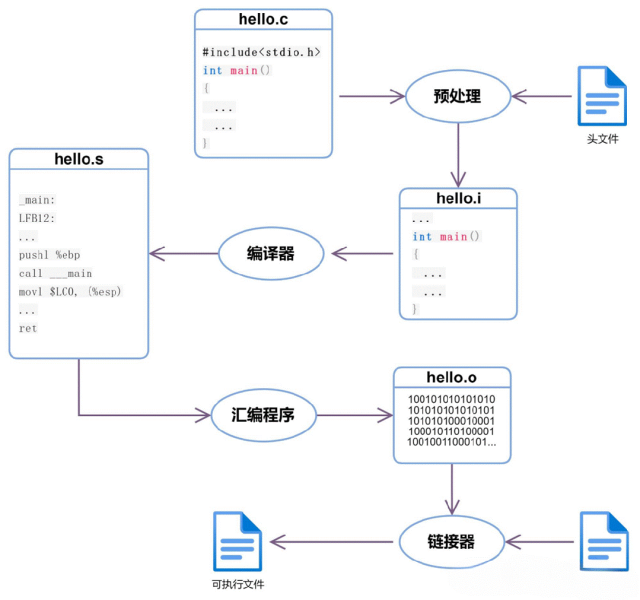
1、 编译器是一种翻译程序,它用于将源语言(即用某种程序设计语言写成的)程序翻译为目标语言(即用二进制数表示的伪机器代码写成的)程序。后者在windows操作系统平台下,其文件的扩展名通常为.obj。该文件通常还要经过进一步的连接,生成可执行文件(机器代码写成的程序,文件扩展名为.exe)。通常有两种方式进行这种翻译,一种是编译,另一种是解释。后者并不生成可执行文件,只是翻译一条语句、执行一条语句。这两种方式相编译比解释运行的速度要快得多。
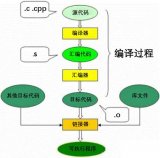
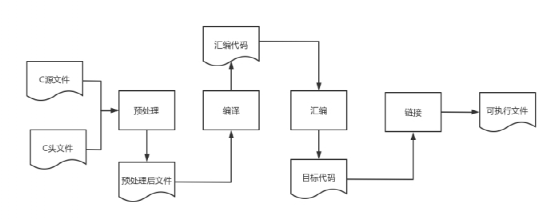
2、 编译过程的5个阶段:词法分析;语法分析;语义分析与中间代码产生;优化;目标代码生成。
3、 在这五个阶段中,词法分析的任务是识别源程序中的单词是否有误,编译程序中实现这种功能的部分一般称为词法分析器。在编译器中,词法分析器通常仅作为语法分析程序的一个子程序以便在它需要单词符号时调用。在这一编译阶段中发现的源程序错误,称为词法错误。
4、 语法分析阶段的目的是识别出源程序的语法结构(即语句或句子)是否错误,所以有时又常为句子分析。编译程序中负责这一功能的程序称为语法分析器或语法分析程序。在这一阶段中发现的错误称为语法错误。
5、 C语言的(源)程序必须经过编译才能生成目标代码,再经过链接才能运行。PASCAL语言、FORTRAN语言的源程序也要经过这样的过程。通常将C、PASCAL、FORTRAN这样的语言统称为高级语言。而将最终的可执行程序称为机器语言程序。
6、 在编译C语言程序的过程中,发现源程序中的一个标识符过长,超过了编译程序允许的范围,这个错误应在词法分析阶段发现,这种错误通常被称作词法错误。
6.1. 词法分析器的任务是以词法规则为依据对输入的源程序进行单词及其属性的识别,识别出一个个单词符号。
6.2. 词法分析的输入是源程序,输出是一个个单词的特殊符号,称为Token(标记或符号)。
6.3.语法分析器的类型有:自下而上、自上而下。常用的语法分析器有:递归下降分析方法是一种自上而下分析方法, 算符优先分析法属于自下而上分析方法,LR分析法属于自下而上分析方法等等。
6.4.通常用正规文法或正规式来描述程序设计语言的词法规则,而使用上下文无关文法来描述程序设计语言的语法规则。
6.5.语法分析阶段中,处理的输入数据是来自词法分析阶段的单词符号。它们是词法分析阶段的终结符。
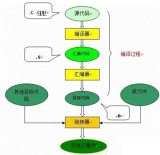
7、 编译程序总框
8、 在计算机发展的早期阶段,内存较小的不能一次完成程序的编译。这时通常将编译过程分成若干遍来完成。每一遍完成一部分功能,称为多遍编译。
与采用高级程序设计语言写的词法分析器相比,用汇编语言写的词法分析通常分析速度要快些。
二。 词法与语法
1、 程序语言主要由语法和语义两个方面来定义。
2、 任何语言的程序都可看成是某字符集上的一个长字符串。
3、 语言的语法:是指这样的一组规则(即产生式),用它可以生成和产生一个良定的程序。这些规则的一部分称为词法规则,另一部分称为语法规则。
4、 词法规则:单词符号的形成规则;语法规则:语法单位(句子)的形成规则。语义规则:定义程序句子的意义。
5、 一个程序语言的基本功能是描述数据和对数据的运算。
6、 高级语言的分类:强制式语言;应用式语言;基于规则的语言;面向对象的语言。
7、 一个语言的字母表为{a,b},则字符串ab的前缀有a、ε,其中ε不是真前缀。
8、 字符串的连接运算一般不满足交换率。
9、 文法G是一个四元组,或者说由四个元素构成,即非终结符集合VN、非终结符号集合VT 、开始符号S、产生式集合P,它可以形式化地表示成G =(VN,VT,S,P)。
按照文法的定义,这4个元素中终结符号集合是这个文法所规定的语言的字母表,产生式集合代表文法所规定的语言语法实体的集合。对上下文无关文法,通常我们只需要写出这个文法的产生式集合就可以确定这个文法的其他所有元素。其中,第一条产生式的左部符号为开始符号,而所有产生式的左部符号构成的集合就是该文法的非终结符集合。
文法的例子:
设文法G=(VN,VT, S,P),其中P为产生式集合,它的每个元素的形式为产生式。
10、如果文法G的一个句子存在两棵不同的最左语法分析树,则这个文法是无二义的。
11、如果文法G的一个句子存在两棵不同的最右语法分析树,则这个文法是无二义的。
12、如果文法G的一个句子存在两棵不同的语法分析树,则这个文法是无法判断是否是二义的。
13、A为非终结符,如果文法存在产生式 ,则称 可以推导出 ;反之,称 可归约为 。
14、乔姆斯基(Chomsky)将文法分为四类,即0型文法、1文法、2文法、3文法。
按照乔姆斯基对方法的分类,上下文无关文法是2型文法,2型文法的描述能力最强,3型文法又称为正规文法。
15、产生式S→Sa | a产生的语言为L(G) = {an | n ≥ 1}。
16、确定有限自动机DFA是非确定有限自动机NFA的特例;对任一非确定有限自动机能找到一个与之等价的确定有限自动机。
17、DFA和NFA的主要区别有三点:一、DFA初态唯一,NFA初态不唯一;二、DFA弧标记为Σ上的元素,NFA弧标记为Σ*上的元素;三、DFA的函数为单射,NFA函数不是单射。
18、有限自动机中两个状态S1和S2是等价的是指,无论是从S1还是S2出发,停于终态时,所识别的输入字的集合相同。
19、自下而上的分析方法,是一个不断归约的过程。
20、递归下降分析器:当一个文法满足LL(1)条件时,我们就可以为它构造一个不带回溯的自上而下分析程序。这个分析程序是由一组递归过程组成的,每个过程对应文法的一个非终结符。
这个产生式中含有的左递归是直接左递归。递归下降分析法中,必须要消除所有的左递归。递归下降分析法中的试探分析法之所以要不断用一个产生式的多个候选式进行逐个试探,最根本的原因是这些候选式有公共左因子。
21、算符优先分析法是一种自下而上的分析方法,它适合分析各种程序设计语中的表达式,并宜于手工实现。目前最广泛的无回溯的“移进—归约”方法是自下而上分析方法。
22、在表驱动预测分析器中,
1)读入一个终结符a,若该终结符与栈项的终结符相同,并且不是结束标志$,则此时栈顶符号出栈;
2)若此时栈项符号是终结符并且是,并且读入的终结符不是,说明源程序有语法错误;
3)若此时栈顶符号为,并且读入的终结符也是,则分析成功。
23、算符优先分析方法不存在使用形如 这样的产生式进行的归约,即只要求终结符的位置与产生式结构一致,从而使得分析速度比LR分析法更快。
24、LR(0)的例子:
产生式E→ E+T对应的LR(0)项目中,待归约的项目是E→ E+∙T,移进项目是E→ E∙+T,还有两个项目为E→ ∙E+T和E→ E+T∙。
当一个LR(0)项目集中含有两个归约项目时,称这个项目集中含有归约-归约冲突。
25、LL(1)文法的产生式中一定没有公共左因子,即LL(1)文法中一定没有左递归。为了避免回溯,在LL(1)文法的预测分析表中,一个表项中至多只有一个产生式。
预测分析方法(即LL(1)方法),由一个栈,一个总控程序和一个预测分析表组成。其中构造出预测分析表是该分析方法的关键。
26、LR(0)与SLR(1)两种分析方法相比,SLR(1)的能力更强。
27、静态语义检查一般包括以下四个部分,即类型检查、控制流检查、名字匹配检查、一致性检查。
C语言编译过程中下述常见的错误都属于检查的范围:
a) 将字符型指针的值赋给结构体类型的指针变量:类型检查。
b)switch语句中,有两个case语句中出现了相同的常量:一致性检查。
c)break语句在既不是循环体内、又不是break语句出现的地方出现:控制流检查。
d)goto语句中的标号在程序的函数中没有找到:一致性检查。
e)同一个枚举常量出现在两个枚举类型的定义当中:相关名字检查。
28、循环优化中代码外提是指对循环中的有些代码,如果它产生的结果在循环过程中是不变的,就把它提到循环体外来;而强度削弱是指把程序中执行时间较长的运算替换为执行时间较短的运算。
解析编译原理主要过程
第一个编译器由机器语言开发 然后就有了后来的各种语言写出来的编译器
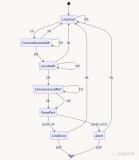
1 编译过程包括如下图所示:。
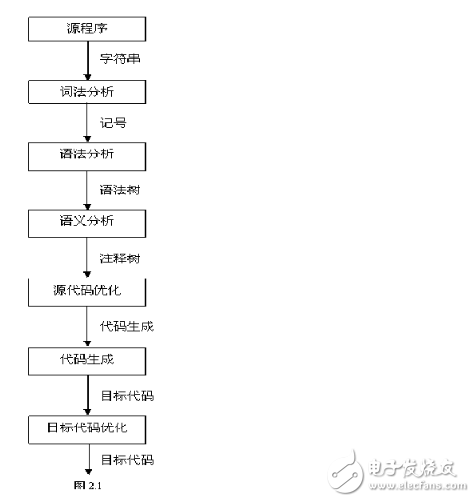
2 词法分析作用:找出单词 。如int a=b+c; 结果为: int,a,=,b,+,c和;
3语法分析作用:找出表达式,程序段,语句等。如int a=b=c;的语法分析结果为int a=b+c这条语句。
4语义分析作用:查看类型是否匹配等。
5注意点:词法分析器实现步骤:正规式-》NFA-》简化后的DFA-》对应程序;语法分析要用到语法树;语义分析要用到语法制导。
编译原理一般分为词法分析,语法分析,语义分析和代码优化及目标代码生成等一系列过程。下面我们结合来了解一下:
本程序可以同时在BC和Visual C++下运行。我测试过了的。下面先将代码贴给大家。其中如果你只想先了解词法分析部分,你可以将其余的注释就可以。我建议大家学习时一步一步来,从词法分析学,然后学语法分析。其他的就类似了。
如果你在DOS下运行,由于使用了汉字,请将其自行换成英文方便您的识别。
程序中的解释就是编译的基本原理。如果还不清楚建议大家看孙悦红的编译原理及实现清华的。




















 工商网监
工商网监
评论