 电子发烧友App
电子发烧友App


函数中的栈
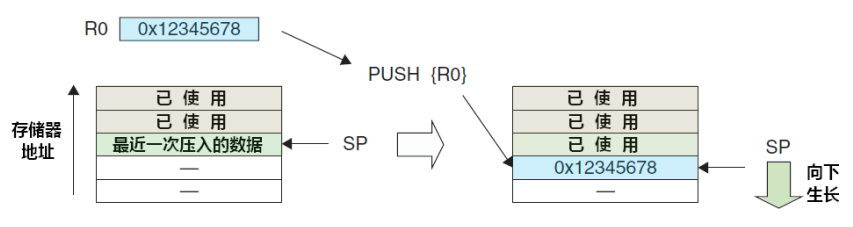
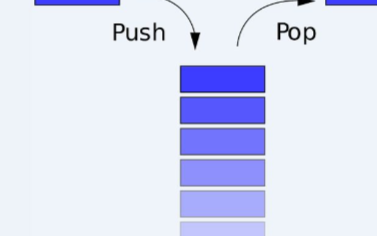
栈是一种具有先入后出特性的数据结构,前面说过,这种特性常常用来帮住我们“原理返回”或者“保持原样”。试想,当我们第一次来到一个陌生的城市,走在陌生的街道上,寻找一个陌生的目标,最令我们有安全感的莫过于仔细记录走过的每一个街道、穿过的每一个路口--这种安全感来源于潜意识里“万一找不到目的地就原路返回”的想法。记得20世纪90年代,有一首家喻户晓的流行歌曲《星星点灯》中曾这样唱到“星星点灯。。。为迷失的孩子,照亮来时的路”。
“找到来时的路”这种想法是人们基本的求生本能,对有人类编写的C语言编译器来说,也是这样--面对一层一层复杂嵌套关系的函数调用,编译器总是试图记录下我们调用的过程,以便“找回回去的路”。栈就在这种场合中,得到了广泛的应用。
C语言支持函数的调用,这完全得益于栈式分配策略的使用。所谓栈式分配,抛去复杂的技术细节,简单说来,就是将函数内部使用的种种信息(例如,局部变量)在发生函数嵌套调用时,压入栈中“记录下所走过的路”。这样,当调用的函数运行结束需要返回时,编译器就能很容易从栈中找到“来时的路”。使用模拟的方法,我们来具体看看这一过程。
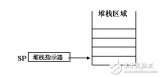
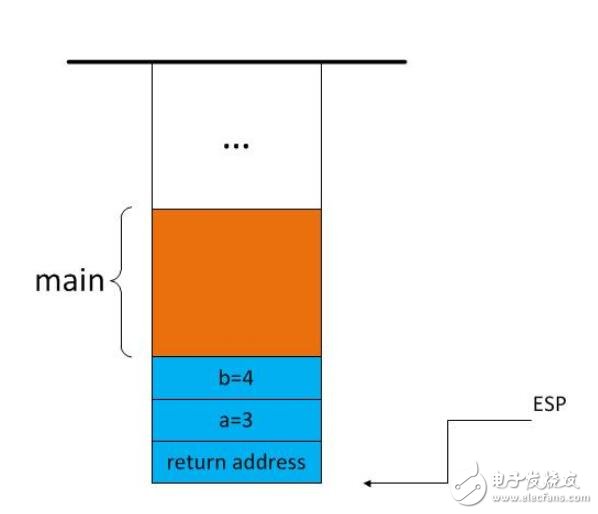
我们假设:一个函数中所有牵涉到的局部信息都被包含在一个与函数同名的接节点中。当我们在某一个函数中发生了对另外一个函数的调用,就将本函数的局部信息压入栈中--也就是将以该函数命名的结点压入栈中:当我们从某一函数中返回,就从栈中弹出一个结点。观察一段代码的函数调用情况,了解编译器如何借助来实现函数的嵌套调用。
软件堆栈和硬件堆栈
ICCAVR 使用两个堆栈:一个用于子程序调用和中断操作的硬件堆栈,一个用于传递参数、临时变量和局部变量的软件堆栈。可以使用堆栈检测函数检测两个堆栈是否溢出。
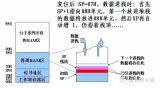
看其栈顶指针是否和CPU具有特殊的关联,有关联者(如SP)“硬”,而无关联者“软”。
单片机在执行调用子程序的指令时,一般会把返回地址自动存入堆栈,而没有被单片机自动入栈但是也需要保存的内容比如状态寄存器、通用寄存器等,就得通过PUSH等指令把它们人为地保存到堆栈中。自动入栈和“人为入栈”可能使用的是一个堆栈指针。有的单片机可以分开,比如AVR,可以通过“ST -Y, R0”这样的指令把R0存入软件堆栈区(Y是由R28和R29两个寄存器的值组成的16位指针),有的单片机缺少这样的指令,就会把软件堆栈和硬件堆栈放在一个栈空间,都使用SP,比如51.
硬件堆栈:或许也可以称作系统堆栈,是位于片内RAM区。有人说,只要能使用PUSH,POP指令的单片机,都可以说含有硬件堆栈。这样的说法我个人觉得不是很全面。通过指令进行压栈和出栈操作只是系统堆栈中的一种操做。系统堆栈还可以被隐含调用。例如,当调用子程序时,系统会主动把返回地址压入堆栈,并不需要用户通过指令操作。通常,栈底设在内存的高端,也就是把内存的最高一段空间划作栈区。这些都是向下生长栈。栈指针可能是专用的寄存器,也可能借用一通用寄存器。也有单片机是在数据区里划一块作栈区,可能是向上生长,也可能是向下生长。
硬件堆栈:是通过寄存器SPH,SPL做为索引指针的地址,是调用了CALL,RCALL等函数调用指令后硬件自动填充的堆栈!
软件堆栈:是编译器为了处理一些参数传递而做的堆栈,会由编译器自动产生和处理,可以通过相应的编译选项对其进行编辑。
简单一点说,硬件堆栈主要做为地址堆栈用,而软件堆栈主要会被分配成数据堆栈!
如果没有硬堆栈,你可以选定一个寄存器作堆栈指针,通过软件实现堆栈操作。移植μC/OS-II也不一定要硬堆栈。ARM 就很难说它的堆栈是软的还是硬的。32位的ARM指令中没有PUSH、POP指令。ARM习惯上用R13作堆栈指针(SP),但用别的寄存器作堆栈指针也未常不可。ARM习惯上用LDM/STM(多寄存器加载/存储指令)来操作堆栈,压多少,按什么顺序都能选择。应该说ARM是软硬结合的堆栈。
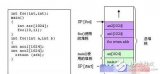
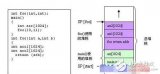
C代码(AVR-GCC编译,优化等级-00):
#include 《avr/io.h》
int add(int a,int b)
{
int c;
c=a+b;
returnc;
}
int main(void)
{
inta=2,b=3,c=0;
c=add(a,b);
//c=sub(a,b);
}
汇编代码:
(省略一些boot代码)
。。。。。。。
00000054 《__ctors_end》:
54: 1124 eor r1,r1
56: 1fbe out 0x3f,r1 ;63
58: cfe5 ldi r28,0x5F ;95 //此处Y指针和SP都指到了SRAM最高端
5a: d4e0 ldi r29,0x04 ;4
5c: debf out 0x3e,r29 ;62
5e: cdbf out 0x3d,r28 ; 61
。。。
0000008e 《add》:
#include 《avr/io.h》
int add(int a,int b)
{
8e: cf93 push r28
90: df93 push r29 //保存了Y指针,此时SP已经-2,这里再减2
92: cdb7 in r28,0x3d ;61 //重新定位Y指针跟SP一样。
94: deb7 in r29,0x3e ;62
96: 2697 sbiw r28,0x06 ;6 //减掉6,即向下开了6字节的区域,存放3变量
98: 0fb6 in r0,0x3f ;63
9a: f894 cli
9c: debf out 0x3e,r29 ;62
9e: 0fbe out 0x3f,r0 ; 63
a0: cdbf out 0x3d,r28 ;61
a2: 9a83 std Y+2,r25 ;0x02
a4: 8983 std Y+1,r24 ;0x01
a6: 7c83 std Y+4,r23 ;0x04
a8: 6b83 std Y+3,r22 ;0x03
int c;
c=a+b;
aa: 2981 ldd r18,Y+1 ;0x01
ac: 3a81 ldd r19,Y+2 ;0x02
ae: 8b81 ldd r24,Y+3 ;0x03
b0: 9c81 ldd r25,Y+4 ;0x04
b2: 820f add r24,r18
b4: 931f adc r25,r19
b6: 9e83 std Y+6,r25 ;0x06
b8: 8d83 std Y+5,r24 ;0x05
returnc;
ba: 8d81 ldd r24,Y+5 ;0x05
bc: 9e81 ldd r25,Y+6 ;0x06
be: 2696 adiw r28,0x06 ;6 //加了6个字节空间,Y指针恢复到减6之前
c0: 0fb6 in r0,0x3f ;63
c2: f894 cli
c4: debf out 0x3e,r29 ;62
c6: 0fbe out 0x3f,r0 ; 63
c8: cdbf out 0x3d,r28 ;61
ca: df91 pop r29
cc: cf91 pop r28
ce: 0895 ret //弹出堆栈中2个字节
000000d0 《main》:
}
int main(void)
{
d0: c9e5 ldi r28,0x59 ;89 //这4句给SP和Y指针重新赋值了,很明显的在SP的
d2: d4e0 ldi r29,0x04 ;4 //上面还有6个字节(SRAM最大到045E),这6个字节
d4: debf out 0x3e,r29 ;62 //被存放了a,b,c三个变量(可以与上面理论对应)
d6: cdbf out 0x3d,r28 ;61 //通过Y指针来保存了这三个变量到这个区域
inta=2,b=3,c=0;
d8: 82e0 ldi r24,0x02 ;2
da: 90e0 ldi r25,0x00 ;0
dc: 9a83 std Y+2,r25 ;0x02
de: 8983 std Y+1,r24 ;0x01
e0: 83e0 ldi r24,0x03 ;3
e2: 90e0 ldi r25,0x00 ;0
e4: 9c83 std Y+4,r25 ;0x04
e6: 8b83 std Y+3,r24 ;0x03
e8: 1e82 std Y+6,r1 ;0x06
ea: 1d82 std Y+5,r1 ;0x05
c=add(a,b);
ec: 6b81 ldd r22,Y+3 ;0x03
ee: 7c81 ldd r23,Y+4 ;0x04
f0: 8981 ldd r24,Y+1 ;0x01
f2: 9a81 ldd r25,Y+2 ;0x02
f4: 0e 94 4700 call 0x8e《add》 //使用call时自动将PC+2的地址压到堆栈
f8: 9e83 std Y+6,r25 ;0x06
fa: 8d83 std Y+5,r24 ;0x05
//c=sub(a,b);
}
fc: 80e0 ldi r24,0x00 ;0
fe: 90e0 ldi r25,0x00 ;0
100: 0c 94 82 00 jmp 0x104《_exit》
00000104 《_exit》:
104: ffcf rjmp 。-2 ; 0x104《_exit》
r28和r29一起组成SP指针,Y指针可以作为间接寻址,很明显的刚开始的时候Y指针和SP都在045F这里,后来在高处开了6个字节的空间来存放临时变量,所以Y指针成了这个软件堆栈的栈顶,在这个过程中都是使用Y和SP的配合来实现变量和数据的改变,以及恢复,硬件堆栈和软件堆栈在这里已经不怎么区分了
栈是可变的,要留足够的空间才行,如果没有操作系统用的会很少,主要取决于函数的嵌套深度参数类型。
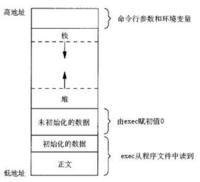
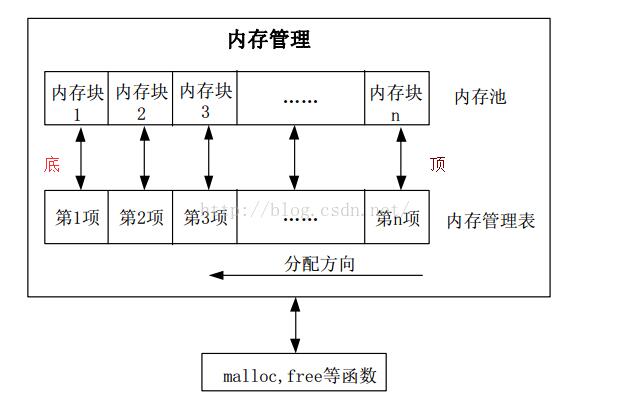
一般情况RAM存放三种类型的数据:
1.全局变量
2.堆(典型的MALLOC函数调用),这个得看你用了还是没有
3.栈,这个必然要用到的,有操作系统的话用的就更多了,每一个任务都会有一个栈,根据任务的函数嵌套程度可分配不同的大小。
具体要看什么编译器了,所以首先要估计一下你的栈要用多少,然后,再计算一下你的全局变量有多少,最后定一下可能的动态分配内存(堆)有多少就可以了。
考虑到存储器的大小的限制,我们在编写单片机的程序时,一定要精打细算。一个程序,当系统中使用了大量的中断资源,并且允许了中断嵌套的存在,那么在极端的情况下,中断处理程序就很容易发生嵌套现象。此时适当扩大硬件堆栈的大小,支持较大的函数嵌套深度,往往能解决很多莫名其妙的跑飞问题。与拥有丰富存储器资源时的状况不同,由于局部变量在函数发生嵌套时,都要占用软件堆栈空间,因此大量使用使用局部变量或者使用了占用空间颇为可观的局部数组(也包括体积巨大的结构体),在嵌套深度较大时,都有可能造成向下生长的软件堆栈侵入其他存储区域(详细情形阅读ICC的帮助文档),导致某些变量意外修改、程序跑飞等现象。解决这一问题的方法其实很简单,在某些局部变量占用空间较大的情况下,将其通过关键static声明为静态变量--这样即保证了变量的局限性,又避免了将这些内容压入软件栈中(静态局部变量在存储时和全局变量没有本质区别,采用的都是 静态分配),只不过每次使用这些变量之前都要记得补充必要的初始化代码。














 工商网监
工商网监
评论