 电子发烧友App
电子发烧友App


随着网络技术和多媒体技术的发展.视频通信的需求逐渐增加.同时最新的视频压缩标准不断推出。MPEG-4 ( Moving Pictures Expcrts Group-4)是国际运动图像像编码专家组(MPEG Moving Picture Experts Group)在1998年11月制定[1]的,它不同于其他标准.是个而向多媒体应用的压缩标准. 第1次提出了基于对象的压缩方法.使交互功能的实现成为可能。日前基于PC平台的MPEG-4视频编码器[2]在互联网的远程教育和高清晰电影等方面己经有较多的应用.但在硬盘录像机、多媒体通信等视频业务的嵌入式系统应用更为广泛。以DSP为嵌入式图像处理核心的系统,具有开发周期短,编程灵活的特点,因此DSP图像处理系统成为了研究热点。
DSPs结构特点
TMS320C6455是TI ( Tcxas Instrumcnts Incorporatcd)公司推出的最新高速DSP芯片[3]。具体结构见图1。最主要的特点从是结构[4]上采用了VLIW(VLIW: VeryLong Instruction Word)超长指令字内核结构.具有1200 MHz的CPU,每个周期可以同时执行8条32bit的指令。速度可达到9600 MIPS ( 1200 MHz X 8条指令=4 800 MIPS) 。片内采用2级高速缓存结构.片外存储器有很强大的外部存储器接口EMIF ( Extcrnal Mcm ory Intcrfacc)。 这些性能能满足视频图像处理的实时性要求.确立了它在高端多媒体应用中的地位。

图1 TMS320C6455DSP 的内核结构
对Cache的优化
最大程度地发挥Cache效率是达到期望编码器性能的一个关键因素[5]。Cache高速的存储访问速度可以减少CPU延迟周期.提高处理器的效率。TMS320C64xDSP有两级存储结构应用片内数据和程序存储。对于L1Cache能够以CPU的同样速度访问。L2Cache既可以作数据空间也可以作为程序空间使用.L2是片外空间与L1的桥梁。
MPEG-4视频编码器是以宏块为单位进行编码处理 ,只有当前宏块处理完成所有的过程后,视频编码器才能传送一个宏块。直接出现的缺点是: 一个视频编码器整个代码大于 L1P。每个宏块在 L1P和 L2之间的传送过程 ,导致严重的Cache缺失。而一个单独的宏块从片外存储空间到片内空间的搬移 , 也不能发挥 EDMA (Extended Direct Memony Access )的优势。
为避免发生的Cache大量缺失,采取 3种方法[6] 。
1.整个编码算法应该分成 3个模块: 宏块编码、运动估计、运动重建 , 这样使每个模块代码都适合 L1P。每次循环以宏块组为单位 , 宏块组的大小由 L1D大小决定。在宏块编码模块中, 当宏块组被传送到片内,他们一起经过 DCT Direct Cosine Transform 、量化、熵编码 , 直到宏块组编码模块结束为止,L1D才刷新这组宏块。同时对应的程序包括 DCT、量化、熵编码也被保存到 L1P。
2.尽量减少数据类型的大小。可以用 8位数据就不用 16位数据 , 这样不但节省空间 ,而且能提高L1D的使用效率。因为 L1D行的大小是固定的, 在一行内如果采用 8位数据 比 16位数据可多放一倍 , 从而减少程序中 Cache缺失情况的发生。
3.采用乒乓缓存结构, 提高 Cache命中率 , 减少 CPU等待时间。
在视频编码模块中,当前帧和参考帧数据放在片外存储器,在编码过程中需要依次对图像帧中的每个宏块进行操作。但宏块直接从片外内存读取,这就会发生CPU等待。可以设置两对片上缓存,一对存放当前帧宏块,一对存放参考帧宏块,它们以乒乓方式工作。乒乓缓冲工作模式如图1所示。编码前E DMA将片外的当前帧中编码宏块数据和在搜索范围内的参考帧宏块数据搬移到片上内存。在用EDMA搬移数据到其中一块片内缓存的同时,,处理器可以对另一块缓存中的数据进行处理。经过这样的修改,CPU一直从片上读取存储器数据大大减少了CPU阻塞情况的发生,提高了编码速度。

图2 乒乓缓冲存储器结构
SAD和像素插值的优化
SAD(Sum ofAbsolute Difference)是运动估计模块[7]关键模块 , 而 DM642提供了一套丰富的视频和图像专用指令可以高效实现运动估计算法。
LDNDW (Load Non2alignedDoubleWord)指令,可以一次读取 64位无边界数据。这个指令可以从当前帧中和参考帧一次读取8个 8位像素数据。因此可以提高当前帧和参考帧宏块数据的搬移速度。
SUBABS4(Subtractwith Absolute)指令,计算在两组 8位数据包之间的 4个绝对值之差。
DOPTPU4是个计算 4对 8位数据乘积求和的运算。两个 DOPTPU4可在单周期内并行 , 所以可极大地提高 SAD的计算速度。具体步骤如下:
1)两个 LDNDW指令从当前帧和参考帧取 8个像素;
2)两个 SUBABS4计算 8个像素的差值;
3)两个 DOTPU4计算 8个像素乘积求和。
像素插值也是个计算量大的模块。AVG4指令可执行 4个 8位数值平均值计算。AVG2可以执行 2个 16位数据的平均计算。SHRMB(Shift Right andMerge Byte) 右移第 2个寄存器 , 把第 1个寄存器的低位作为高字节。AVG4计算平均值,SHRMB处理结果。
此外笔者参考 TI提供的 IMGLIB支持库 该库中还包括了许多常用的图像和视频处理的函数 ,以完成 DCT、 IDCT (Inverse Direct Cosine Transform)、中值滤波等功能 , 这些函数都是经过汇编优化。完全能够实现软件流水, 执行效率很高。采用标准序列 Coastguard.yuv编码 5帧数据,主要函数优化前后性能比较,如表 1所示。
表 1 各个函数优化性能比较

Tab1Performance of functions by analysis
利用 EDMA进行数据搬移, 提高存储速度
TMS320C6455DSP支持 EDMA功能 , 是在没有 CPU介入的情况下 , 访问存储器的一种工作方式。它可以直接通过 EDMA通道 , 提前把外设或片外存储器中的数据直接搬移到片上内存。对 CPU来说 , 所访问的数据总是在片内的 , 没有阻塞的情况发生 , 减少了 CPU等待时间[8]。
使用 TI的 CSL (Chip SupportLibrary )支持功能[9,10]。它有专门的 DMA模块 , 便于对 DMA的各个存储器控制。主要使用 DAT函数 , 进行 DMA存储器间数据传送。其中使用 DAT copy ( )和DAT fill ( )。
就象常用的内存操作 memcpy 、memset 一样 , 只需要在 API接口指出源地址、目的地址、长度、维数属性等 , 而不需要再去考虑具体的寄存器。
下面的代码就是把 SDRAM中的 90帧 CIF 288 ×352 格式视频序列中的一帧 , 利用 EDMA在缓存中进行搬移。
DAT_open(DAT_CHANNY, DAT_ PRI_ LOW,DAT_OPEN_2D);
Copy2FrameBuf(Unit8*framebuf)
{
if((tempbuf_rawbuf)>13685852)
if (tempbuf!=NULL)
free(tempbuf);
return 1;
}
DAT.copy(tempbuf,framebuf,152064);
Tembuf+=152064;
return 0;
}
编码器的总体性能
表2 MPEG-4编码器的性能
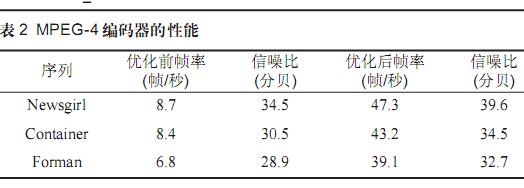
从表2数据可以看出,对于不同的视频序列帧率提高至少5倍以上,信噪比虽然有所降低,但是由于频帧的大幅度提高并达到实时要求而得到弥补,显示效果更好。
结语
笔者论述了TMS32OC6455DSP 平台上进行视频编码算法优化的措施。主要考虑根据DSP自身特点和视频算法进行优化,通过实验可以验证达到30帧/秒以上的实时性要求,随着IC 技术的发展和DSP 价格的降低,基于DSP的视频编码器的商用价值越来越明显。









 工商网监
工商网监
评论